 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorSocket: Shared Data Loading for Deep Learning Training
Paper and Code
Sep 27, 2024

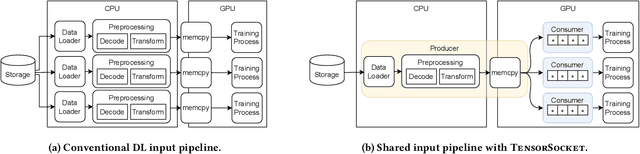
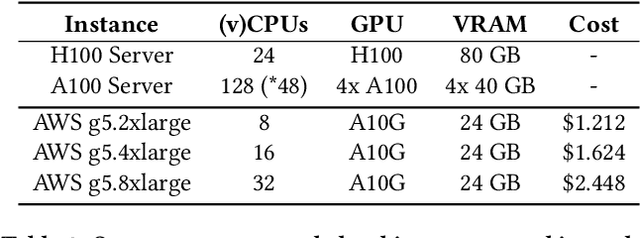
Training deep learning models is a repetitive and resource-intensive process. Data scientists often train several models before landing on set of parameters (e.g., hyper-parameter tuning), model architecture (e.g., neural architecture search), among other things that yields the highest accuracy. The computational efficiency of these training tasks depends highly on how well we can supply the training process with training data. The repetitive nature of these tasks results in the same data processing pipelines running over and over exacerbating the need for and costs of computational resources. In this paper, we present Tensorsocket to reduce the computational needs of deep learning training by enabling simultaneous training processes to share the same data loader. Tensorsocket mitigates CPU-side bottlenecks in cases where the collocated training workloads have high throughput on GPU, but are held back by lower data-loading throughput on CPU. Tensorsocket achieves this by reducing redundant computations across collocated training processes and leveraging modern GPU-GPU interconnects. We demonstrate the hardware- and pipeline-agnostic nature of Tensorsocket and evaluate it using a variety of training scenarios. Our evaluation shows that Tensorsocket enables scenarios that are infeasible without data sharing, increases training throughput by up to $100\%$, and when utilizing cloud instances, Tensorsocket achieves cost savings of $50\%$ by reducing the hardware resource needs on the CPU side. Furthermore, Tensorsocket outperforms the state-of-the-art solutions for shared data loading such as CoorDL and Joader. It is easier to use, maintain, and deploy, and either achieves higher or matches the throughput of other solutions while requiring less CPU resources.