 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorSocket: Shared Data Loading for Deep Learning Training
Sep 27, 2024

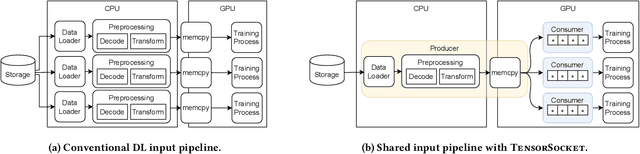
Training deep learning models is a repetitive and resource-intensive process. Data scientists often train several models before landing on set of parameters (e.g., hyper-parameter tuning), model architecture (e.g., neural architecture search), among other things that yields the highest accuracy. The computational efficiency of these training tasks depends highly on how well we can supply the training process with training data. The repetitive nature of these tasks results in the same data processing pipelines running over and over exacerbating the need for and costs of computational resources. In this paper, we present Tensorsocket to reduce the computational needs of deep learning training by enabling simultaneous training processes to share the same data loader. Tensorsocket mitigates CPU-side bottlenecks in cases where the collocated training workloads have high throughput on GPU, but are held back by lower data-loading throughput on CPU. Tensorsocket achieves this by reducing redundant computations across collocated training processes and leveraging modern GPU-GPU interconnects. We demonstrate the hardware- and pipeline-agnostic nature of Tensorsocket and evaluate it using a variety of training scenarios. Our evaluation shows that Tensorsocket enables scenarios that are infeasible without data sharing, increases training throughput by up to $100\%$, and when utilizing cloud instances, Tensorsocket achieves cost savings of $50\%$ by reducing the hardware resource needs on the CPU side. Furthermore, Tensorsocket outperforms the state-of-the-art solutions for shared data loading such as CoorDL and Joader. It is easier to use, maintain, and deploy, and either achieves higher or matches the throughput of other solutions while requiring less CPU resources.
Modyn: A Platform for Model Training on Dynamic Datasets With Sample-Level Data Selection
Dec 11, 2023Machine learning training data is often dynamic in real-world use cases, i.e., data is added or removed and may experience distribution shifts over time. Models must incorporate this evolving training data to improve generalization, adapt to potential distribution shifts, and adhere to privacy regulations. However, the cost of model (re)training is proportional to how often the model trains and on how much data it trains on. While ML research explores these topics in isolation, there is no end-to-end open-source platform to facilitate the exploration of model retraining and data selection policies and the deployment these algorithms efficiently at scale. We present Modyn, a platform for model training on dynamic datasets that enables sample-level data selection and triggering policies. Modyn orchestrates continuous training pipelines while optimizing the underlying system infrastructure to support fast access to arbitrary data samples for efficient data selection. Modyn's extensible architecture allows users to run training pipelines without modifying the platform code, and enables researchers to effortlessly extend the system. We evaluate Modyn's training throughput, showing that even in memory-bound recommendation systems workloads, Modyn is able to reach 80 to 100 % of the throughput compared to loading big chunks of data locally without sample-level data selection. Additionally, we showcase Modyn's functionality with three different data selection policies.
Deep Learning Training on Multi-Instance GPUs
Sep 13, 2022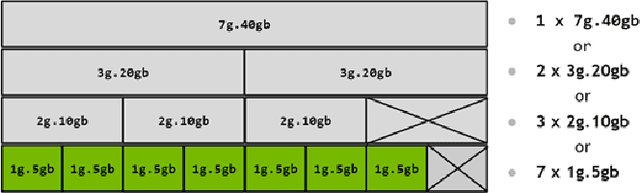
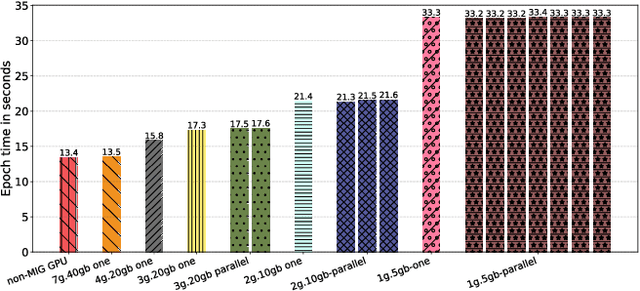
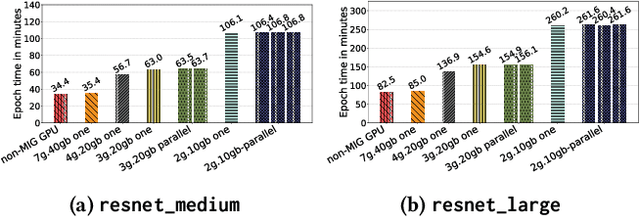
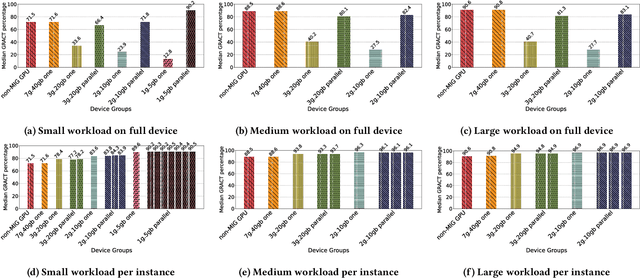
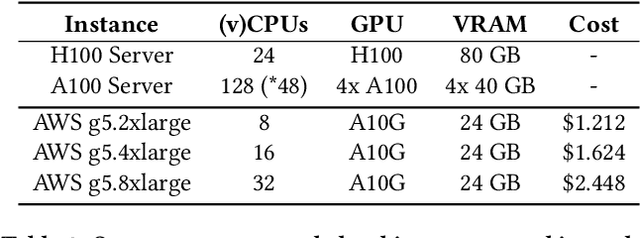
Deep learning training is an expensive process that extensively uses GPUs, but not all model training saturates the modern powerful GPUs. Multi-Instance GPU (MIG) is a new technology introduced by NVIDIA that can partition a GPU to better fit workloads that don't require all the memory and compute resources of a full GPU. In this paper, we examine the performance of a MIG-enabled A100 GPU under deep learning workloads of three sizes focusing on image recognition training with ResNet models. We investigate the behavior of these workloads when running in isolation on a variety of MIG instances allowed by the GPU in addition to running them in parallel on homogeneous instances co-located on the same GPU. Our results demonstrate that employing MIG can significantly improve the utilization of the GPU when the workload is too small to utilize the whole GPU in isolation. By training multiple small models in parallel, more work can be performed by the GPU per unit of time, despite the increase in time-per-epoch, leading to $\sim$3 times the throughput. In contrast, for medium and large-sized workloads, which already utilize the whole GPU well on their own, MIG only provides marginal performance improvements. Nevertheless, we observe that training models in parallel using separate MIG partitions does not exhibit interference underlining the value of having a functionality like MIG on modern GPUs.