 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELT-Bench-Verified: Benchmark Quality Issues Underestimate AI Agent Capabilities
Apr 02, 2026Constructing Extract-Load-Transform (ELT) pipelines is a labor-intensive data engineering task and a high-impact target for AI automation. On ELT-Bench, the first benchmark for end-to-end ELT pipeline construction, AI agents initially showed low success rates, suggesting they lacked practical utility. We revisit these results and identify two factors causing a substantial underestimation of agent capabilities. First, re-evaluating ELT-Bench with upgraded large language models reveals that the extraction and loading stage is largely solved, while transformation performance improves significantly. Second, we develop an Auditor-Corrector methodology that combines scalable LLM-driven root-cause analysis with rigorous human validation (inter-annotator agreement Fleiss' kappa = 0.85) to audit benchmark quality. Applying this to ELT-Bench uncovers that most failed transformation tasks contain benchmark-attributable errors -- including rigid evaluation scripts, ambiguous specifications, and incorrect ground truth -- that penalize correct agent outputs. Based on these findings, we construct ELT-Bench-Verified, a revised benchmark with refined evaluation logic and corrected ground truth. Re-evaluating on this version yields significant improvement attributable entirely to benchmark correction. Our results show that both rapid model improvement and benchmark quality issues contributed to underestimating agent capabilities. More broadly, our findings echo observations of pervasive annotation errors in text-to-SQL benchmarks, suggesting quality issues are systemic in data engineering evaluation. Systematic quality auditing should be standard practice for complex agentic tasks. We release ELT-Bench-Verified to provide a more reliable foundation for progress in AI-driven data engineering automation.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Mixtera: A Data Plane for Foundation Model Training
Feb 27, 2025State-of-the-art large language and vision models are trained over trillions of tokens that are aggregated from a large variety of sources. As training data collections grow, manually managing the samples becomes time-consuming, tedious, and prone to errors. Yet recent research shows that the data mixture and the order in which samples are visited during training can significantly influence model accuracy. We build and present Mixtera, a data plane for foundation model training that enables users to declaratively express which data samples should be used in which proportion and in which order during training. Mixtera is a centralized, read-only layer that is deployed on top of existing training data collections and can be declaratively queried. It operates independently of the filesystem structure and supports mixtures across arbitrary properties (e.g., language, source dataset) as well as dynamic adjustment of the mixture based on model feedback. We experimentally evaluate Mixtera and show that our implementation does not bottleneck training and scales to 256 GH200 superchips. We demonstrate how Mixtera supports recent advancements in mixing strategies by implementing the proposed Adaptive Data Optimization (ADO) algorithm in the system and evaluating its performance impact. We also explore the role of mixtures for vision-language models.
The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks
Feb 12, 2025



Large Reasoning Models (LRMs) represent a breakthrough in AI problem-solving capabilities, but their effectiveness in interactive environments can be limited. This paper introduces and analyzes overthinking in LRMs. A phenomenon where models favor extended internal reasoning chains over environmental interaction. Through experiments on software engineering tasks using SWE Bench Verified, we observe three recurring patterns: Analysis Paralysis, Rogue Actions, and Premature Disengagement. We propose a framework to study these behaviors, which correlates with human expert assessments, and analyze 4018 trajectories. We observe that higher overthinking scores correlate with decreased performance, with reasoning models exhibiting stronger tendencies toward overthinking compared to non-reasoning models. Our analysis reveals that simple efforts to mitigate overthinking in agentic environments, such as selecting the solution with the lower overthinking score, can improve model performance by almost 30% while reducing computational costs by 43%. These results suggest that mitigating overthinking has strong practical implications. We suggest that by leveraging native function-calling capabilities and selective reinforcement learning overthinking tendencies could be mitigated. We also open-source our evaluation framework and dataset to facilitate research in this direction at https://github.com/AlexCuadron/Overthinking.
HashAttention: Semantic Sparsity for Faster Inference
Dec 19, 2024



Utilizing longer contexts is increasingly essential to power better AI systems. However, the cost of attending to long contexts is high due to the involved softmax computation. While the scaled dot-product attention (SDPA) exhibits token sparsity, with only a few pivotal tokens significantly contributing to attention, leveraging this sparsity effectively remains an open challenge. Previous methods either suffer from model degradation or require considerable additional resources. We propose HashAttention --a principled approach casting pivotal token identification as a recommendation problem. Given a query, HashAttention encodes keys and queries in Hamming space capturing the required semantic similarity using learned mapping functions. HashAttention efficiently identifies pivotal tokens for a given query in this Hamming space using bitwise operations, and only these pivotal tokens are used for attention computation, significantly improving overall attention efficiency. HashAttention can reduce the number of tokens used by a factor of $1/32\times$ for the Llama-3.1-8B model with LongBench, keeping average quality loss within 0.6 points, while using only 32 bits per token auxiliary memory. At $32\times$ sparsity, HashAttention is $3{-}6\times$ faster than LightLLM and $2.5{-}4.5\times$ faster than gpt-fast on Nvidia-L4 GPU.
On Distributed Larger-Than-Memory Subset Selection With Pairwise Submodular Functions
Feb 26, 2024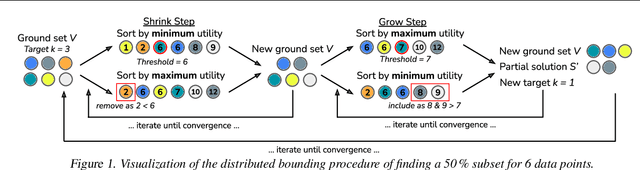
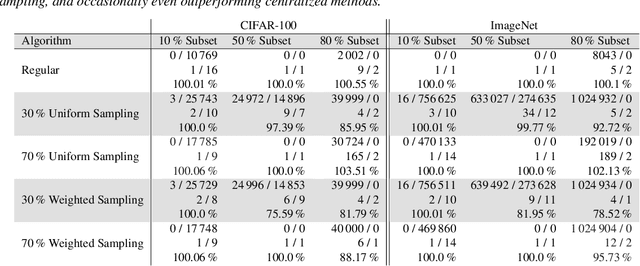

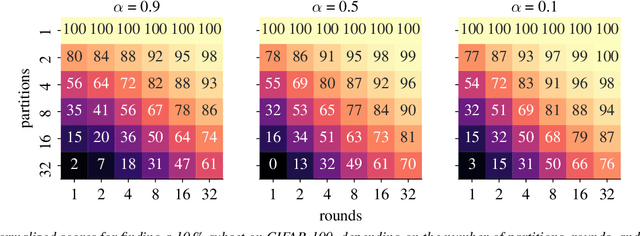
Many learning problems hinge on the fundamental problem of subset selection, i.e., identifying a subset of important and representative points. For example, selecting the most significant samples in ML training cannot only reduce training costs but also enhance model quality. Submodularity, a discrete analogue of convexity, is commonly used for solving subset selection problems. However, existing algorithms for optimizing submodular functions are sequential, and the prior distributed methods require at least one central machine to fit the target subset. In this paper, we relax the requirement of having a central machine for the target subset by proposing a novel distributed bounding algorithm with provable approximation guarantees. The algorithm iteratively bounds the minimum and maximum utility values to select high quality points and discard the unimportant ones. When bounding does not find the complete subset, we use a multi-round, partition-based distributed greedy algorithm to identify the remaining subset. We show that these algorithms find high quality subsets on CIFAR-100 and ImageNet with marginal or no loss in quality compared to centralized methods, and scale to a dataset with 13 billion points.
Modyn: A Platform for Model Training on Dynamic Datasets With Sample-Level Data Selection
Dec 11, 2023


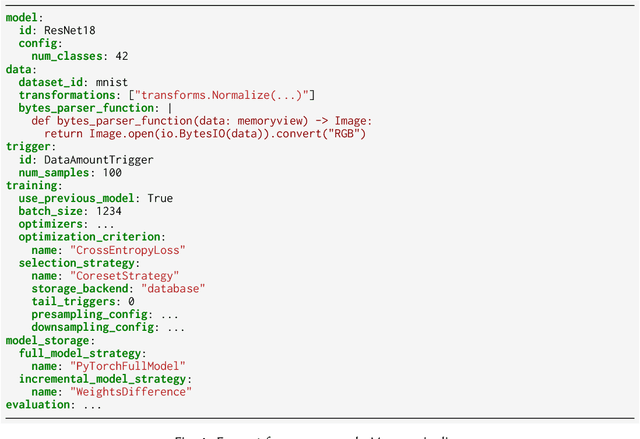
Machine learning training data is often dynamic in real-world use cases, i.e., data is added or removed and may experience distribution shifts over time. Models must incorporate this evolving training data to improve generalization, adapt to potential distribution shifts, and adhere to privacy regulations. However, the cost of model (re)training is proportional to how often the model trains and on how much data it trains on. While ML research explores these topics in isolation, there is no end-to-end open-source platform to facilitate the exploration of model retraining and data selection policies and the deployment these algorithms efficiently at scale. We present Modyn, a platform for model training on dynamic datasets that enables sample-level data selection and triggering policies. Modyn orchestrates continuous training pipelines while optimizing the underlying system infrastructure to support fast access to arbitrary data samples for efficient data selection. Modyn's extensible architecture allows users to run training pipelines without modifying the platform code, and enables researchers to effortlessly extend the system. We evaluate Modyn's training throughput, showing that even in memory-bound recommendation systems workloads, Modyn is able to reach 80 to 100 % of the throughput compared to loading big chunks of data locally without sample-level data selection. Additionally, we showcase Modyn's functionality with three different data selection policies.
DeltaZip: Multi-Tenant Language Model Serving via Delta Compression
Dec 08, 2023Fine-tuning large language models (LLMs) for downstream tasks can greatly improve model quality, however serving many different fine-tuned LLMs concurrently for users in multi-tenant environments is challenging. Dedicating GPU memory for each model is prohibitively expensive and naively swapping large model weights in and out of GPU memory is slow. Our key insight is that fine-tuned models can be quickly swapped in and out of GPU memory by extracting and compressing the delta between each model and its pre-trained base model. We propose DeltaZip, an LLM serving system that efficiently serves multiple full-parameter fine-tuned models concurrently by aggressively compressing model deltas by a factor of $6\times$ to $8\times$ while maintaining high model quality. DeltaZip increases serving throughput by $1.5\times$ to $3\times$ and improves SLO attainment compared to a vanilla HuggingFace serving system.
A case for disaggregation of ML data processing
Oct 28, 2022



Machine Learning (ML) computation requires feeding input data for the models to ingest. Traditionally, input data processing happens on the same host as the ML computation. The input data processing can however become a bottleneck of the ML computation if there are insufficient resources to process data quickly enough. This slows down the ML computation and wastes valuable and scarce ML hardware (e.g. GPUs and TPUs) used by the ML computation. In this paper, we present tf.data service, a disaggregated input data processing service built on top of tf.data. Our work goes beyond describing the design and implementation of a new system which disaggregates preprocessing from ML computation and presents: (1) empirical evidence based on production workloads for the need of disaggregation, as well as quantitative evaluation of the impact disaggregation has on the performance and cost of production workloads, (2) benefits of disaggregation beyond horizontal scaling, (3) analysis of tf.data service's adoption at Google, the lessons learned during building and deploying the system and potential future lines of research opened up by our work. We demonstrate that horizontally scaling data processing using tf.data service helps remove input bottlenecks, achieving speedups of up to 110x and job cost reductions of up to 89x. We further show that tf.data service can support computation reuse through data sharing across ML jobs with identical data processing pipelines (e.g. hyperparameter tuning jobs), incurring no performance penalty and reducing overall resource cost. Finally, we show that tf.data service advanced features can benefit performance of non-input bound jobs; in particular, coordinated data reads through tf.data service can yield up to 2x speedups and job cost savings for NLP jobs.
SHiFT: An Efficient, Flexible Search Engine for Transfer Learning
Apr 04, 2022
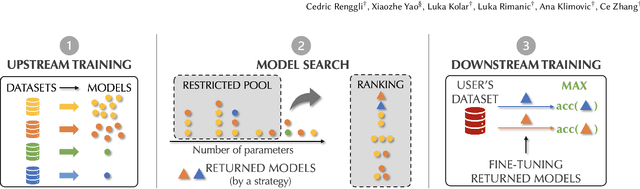
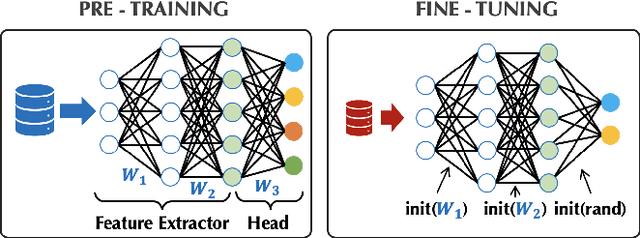
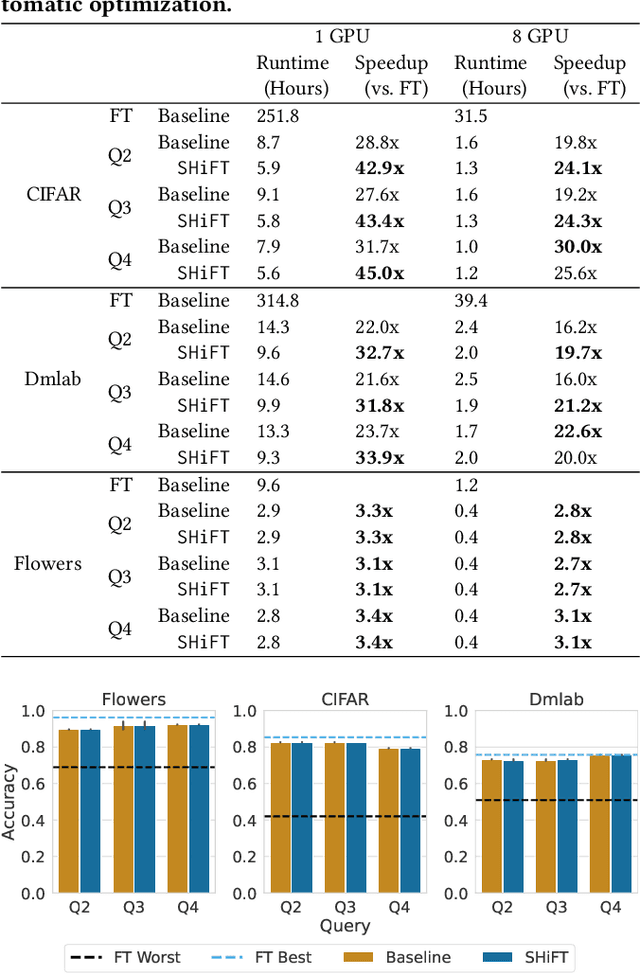
Transfer learning can be seen as a data- and compute-efficient alternative to training models from scratch. The emergence of rich model repositories, such as TensorFlow Hub, enables practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. By carefully comparing various selection and search strategies, we realize that no single method outperforms the others, and hybrid or mixed strategies can be beneficial. Therefore, we propose SHiFT, the first downstream task-aware, flexible, and efficient model search engine for transfer learning. These properties are enabled by a custom query language SHiFT-QL together with a cost-based decision maker, which we empirically validate. Motivated by the iterative nature of machine learning development, we further support efficient incremental executions of our queries, which requires a careful implementation when jointly used with our optimizations.