 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks
Feb 12, 2025



Large Reasoning Models (LRMs) represent a breakthrough in AI problem-solving capabilities, but their effectiveness in interactive environments can be limited. This paper introduces and analyzes overthinking in LRMs. A phenomenon where models favor extended internal reasoning chains over environmental interaction. Through experiments on software engineering tasks using SWE Bench Verified, we observe three recurring patterns: Analysis Paralysis, Rogue Actions, and Premature Disengagement. We propose a framework to study these behaviors, which correlates with human expert assessments, and analyze 4018 trajectories. We observe that higher overthinking scores correlate with decreased performance, with reasoning models exhibiting stronger tendencies toward overthinking compared to non-reasoning models. Our analysis reveals that simple efforts to mitigate overthinking in agentic environments, such as selecting the solution with the lower overthinking score, can improve model performance by almost 30% while reducing computational costs by 43%. These results suggest that mitigating overthinking has strong practical implications. We suggest that by leveraging native function-calling capabilities and selective reinforcement learning overthinking tendencies could be mitigated. We also open-source our evaluation framework and dataset to facilitate research in this direction at https://github.com/AlexCuadron/Overthinking.
Adaptive Semantic Prompt Caching with VectorQ
Feb 06, 2025Semantic prompt caches reduce the latency and cost of large language model (LLM) inference by reusing cached LLM-generated responses for semantically similar prompts. Vector similarity metrics assign a numerical score to quantify the similarity between an embedded prompt and its nearest neighbor in the cache. Existing systems rely on a static threshold to classify whether the similarity score is sufficiently high to result in a cache hit. We show that this one-size-fits-all threshold is insufficient across different prompts. We propose VectorQ, a framework to learn embedding-specific threshold regions that adapt to the complexity and uncertainty of an embedding. Through evaluations on a combination of four diverse datasets, we show that VectorQ consistently outperforms state-of-the-art systems across all static thresholds, achieving up to 12x increases in cache hit rate and error rate reductions up to 92%.
HashAttention: Semantic Sparsity for Faster Inference
Dec 19, 2024



Utilizing longer contexts is increasingly essential to power better AI systems. However, the cost of attending to long contexts is high due to the involved softmax computation. While the scaled dot-product attention (SDPA) exhibits token sparsity, with only a few pivotal tokens significantly contributing to attention, leveraging this sparsity effectively remains an open challenge. Previous methods either suffer from model degradation or require considerable additional resources. We propose HashAttention --a principled approach casting pivotal token identification as a recommendation problem. Given a query, HashAttention encodes keys and queries in Hamming space capturing the required semantic similarity using learned mapping functions. HashAttention efficiently identifies pivotal tokens for a given query in this Hamming space using bitwise operations, and only these pivotal tokens are used for attention computation, significantly improving overall attention efficiency. HashAttention can reduce the number of tokens used by a factor of $1/32\times$ for the Llama-3.1-8B model with LongBench, keeping average quality loss within 0.6 points, while using only 32 bits per token auxiliary memory. At $32\times$ sparsity, HashAttention is $3{-}6\times$ faster than LightLLM and $2.5{-}4.5\times$ faster than gpt-fast on Nvidia-L4 GPU.
JudgeBench: A Benchmark for Evaluating LLM-based Judges
Oct 16, 2024
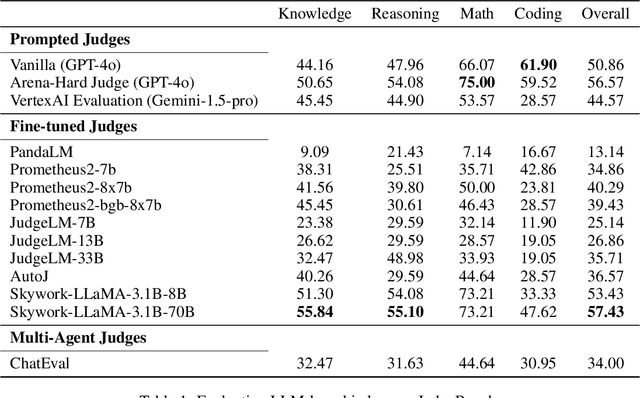
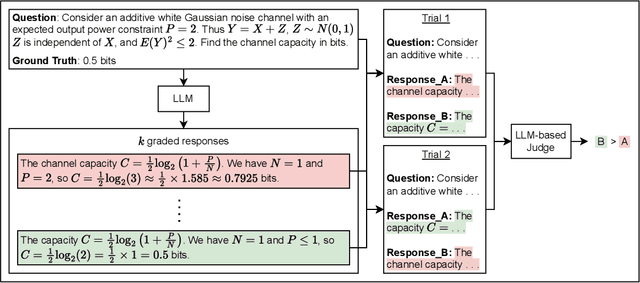
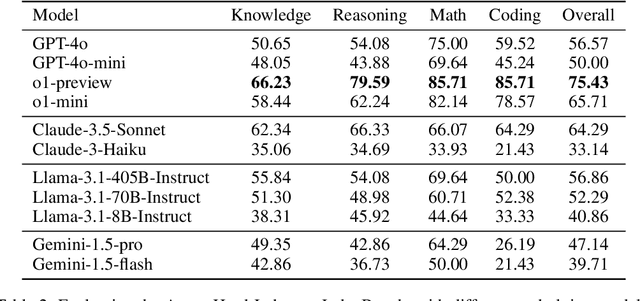
LLM-based judges have emerged as a scalable alternative to human evaluation and are increasingly used to assess, compare, and improve models. However, the reliability of LLM-based judges themselves is rarely scrutinized. As LLMs become more advanced, their responses grow more sophisticated, requiring stronger judges to evaluate them. Existing benchmarks primarily focus on a judge's alignment with human preferences, but often fail to account for more challenging tasks where crowdsourced human preference is a poor indicator of factual and logical correctness. To address this, we propose a novel evaluation framework to objectively evaluate LLM-based judges. Based on this framework, we propose JudgeBench, a benchmark for evaluating LLM-based judges on challenging response pairs spanning knowledge, reasoning, math, and coding. JudgeBench leverages a novel pipeline for converting existing difficult datasets into challenging response pairs with preference labels reflecting objective correctness. Our comprehensive evaluation on a collection of prompted judges, fine-tuned judges, multi-agent judges, and reward models shows that JudgeBench poses a significantly greater challenge than previous benchmarks, with many strong models (e.g., GPT-4o) performing just slightly better than random guessing. Overall, JudgeBench offers a reliable platform for assessing increasingly advanced LLM-based judges. Data and code are available at https://github.com/ScalerLab/JudgeBench .