 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$V_1$: Unifying Generation and Self-Verification for Parallel Reasoners
Mar 04, 2026Test-time scaling for complex reasoning tasks shows that leveraging inference-time compute, by methods such as independently sampling and aggregating multiple solutions, results in significantly better task outcomes. However, a critical bottleneck is verification: sampling is only effective if correct solutions can be reliably identified among candidates. While existing approaches typically evaluate candidates independently via scalar scoring, we demonstrate that models are substantially stronger at pairwise self-verification. Leveraging this insight, we introduce $V_1$, a framework that unifies generation and verification through efficient pairwise ranking. $V_1$ comprises two components: $V_1$-Infer, an uncertainty-guided algorithm using a tournament-based ranking that dynamically allocates self-verification compute to candidate pairs whose relative correctness is most uncertain; and $V_1$-PairRL, an RL framework that jointly trains a single model as both generator and pairwise self-verifier, ensuring the verifier adapts to the generator's evolving distribution. On code generation (LiveCodeBench, CodeContests, SWE-Bench) and math reasoning (AIME, HMMT) benchmarks, $V_1$-Infer improves Pass@1 by up to $10%$ over pointwise verification and outperforms recent test-time scaling methods while being significantly more efficient. Furthermore, $V_1$-PairRL achieves $7$--$9%$ test-time scaling gains over standard RL and pointwise joint training, and improves base Pass@1 by up to 8.7% over standard RL in a code-generation setting.
Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test
Jun 08, 2025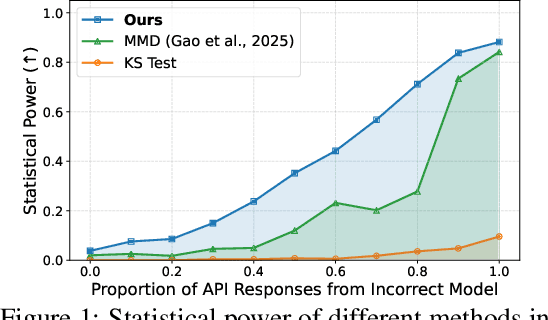

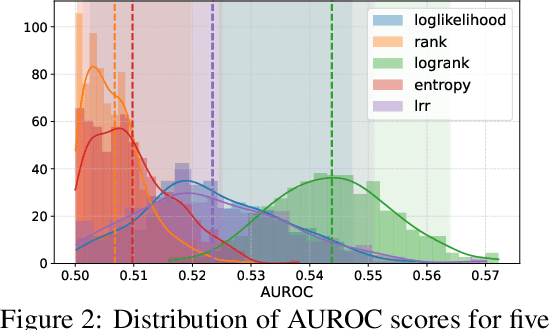
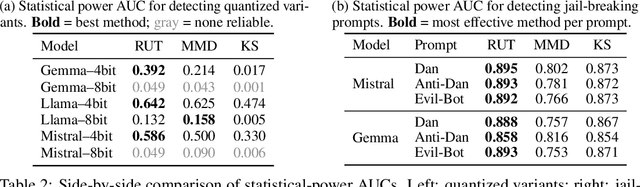
As API access becomes a primary interface to large language models (LLMs), users often interact with black-box systems that offer little transparency into the deployed model. To reduce costs or maliciously alter model behaviors, API providers may discreetly serve quantized or fine-tuned variants, which can degrade performance and compromise safety. Detecting such substitutions is difficult, as users lack access to model weights and, in most cases, even output logits. To tackle this problem, we propose a rank-based uniformity test that can verify the behavioral equality of a black-box LLM to a locally deployed authentic model. Our method is accurate, query-efficient, and avoids detectable query patterns, making it robust to adversarial providers that reroute or mix responses upon the detection of testing attempts. We evaluate the approach across diverse threat scenarios, including quantization, harmful fine-tuning, jailbreak prompts, and full model substitution, showing that it consistently achieves superior statistical power over prior methods under constrained query budgets.
JudgeBench: A Benchmark for Evaluating LLM-based Judges
Oct 16, 2024
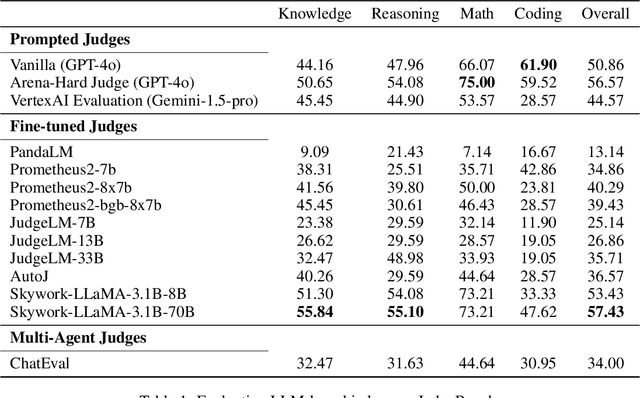
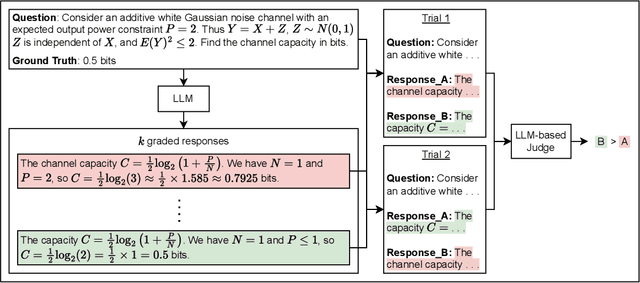
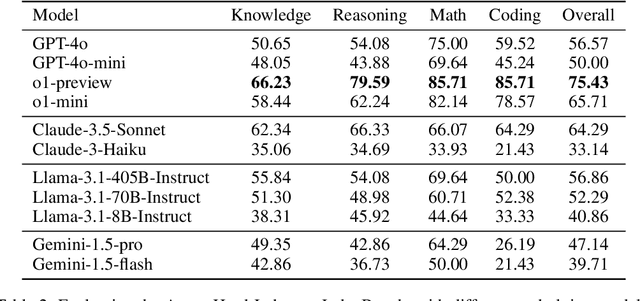
LLM-based judges have emerged as a scalable alternative to human evaluation and are increasingly used to assess, compare, and improve models. However, the reliability of LLM-based judges themselves is rarely scrutinized. As LLMs become more advanced, their responses grow more sophisticated, requiring stronger judges to evaluate them. Existing benchmarks primarily focus on a judge's alignment with human preferences, but often fail to account for more challenging tasks where crowdsourced human preference is a poor indicator of factual and logical correctness. To address this, we propose a novel evaluation framework to objectively evaluate LLM-based judges. Based on this framework, we propose JudgeBench, a benchmark for evaluating LLM-based judges on challenging response pairs spanning knowledge, reasoning, math, and coding. JudgeBench leverages a novel pipeline for converting existing difficult datasets into challenging response pairs with preference labels reflecting objective correctness. Our comprehensive evaluation on a collection of prompted judges, fine-tuned judges, multi-agent judges, and reward models shows that JudgeBench poses a significantly greater challenge than previous benchmarks, with many strong models (e.g., GPT-4o) performing just slightly better than random guessing. Overall, JudgeBench offers a reliable platform for assessing increasingly advanced LLM-based judges. Data and code are available at https://github.com/ScalerLab/JudgeBench .
LLoCO: Learning Long Contexts Offline
Apr 11, 2024Processing long contexts remains a challenge for large language models (LLMs) due to the quadratic computational and memory overhead of the self-attention mechanism and the substantial KV cache sizes during generation. We propose a novel approach to address this problem by learning contexts offline through context compression and in-domain parameter-efficient finetuning. Our method enables an LLM to create a concise representation of the original context and efficiently retrieve relevant information to answer questions accurately. We introduce LLoCO, a technique that combines context compression, retrieval, and parameter-efficient finetuning using LoRA. Our approach extends the effective context window of a 4k token LLaMA2-7B model to handle up to 128k tokens. We evaluate our approach on several long-context question-answering datasets, demonstrating that LLoCO significantly outperforms in-context learning while using $30\times$ fewer tokens during inference. LLoCO achieves up to $7.62\times$ speed-up and substantially reduces the cost of long document question answering, making it a promising solution for efficient long context processing. Our code is publicly available at https://github.com/jeffreysijuntan/lloco.
Least Square Calibration for Peer Review
Oct 25, 2021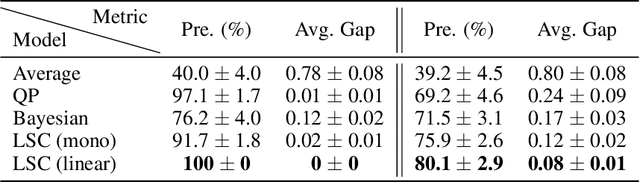
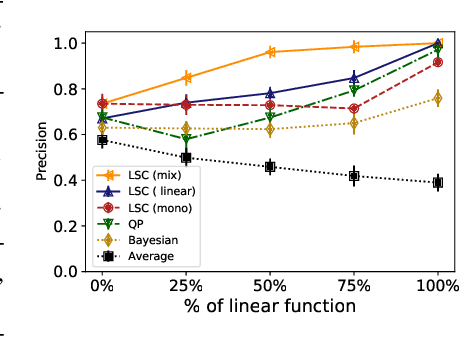

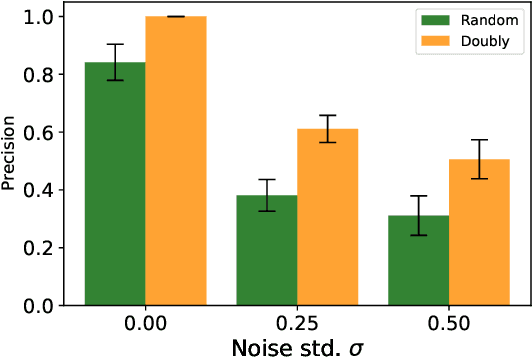
Peer review systems such as conference paper review often suffer from the issue of miscalibration. Previous works on peer review calibration usually only use the ordinal information or assume simplistic reviewer scoring functions such as linear functions. In practice, applications like academic conferences often rely on manual methods, such as open discussions, to mitigate miscalibration. It remains an important question to develop algorithms that can handle different types of miscalibrations based on available prior knowledge. In this paper, we propose a flexible framework, namely least square calibration (LSC), for selecting top candidates from peer ratings. Our framework provably performs perfect calibration from noiseless linear scoring functions under mild assumptions, yet also provides competitive calibration results when the scoring function is from broader classes beyond linear functions and with arbitrary noise. On our synthetic dataset, we empirically demonstrate that our algorithm consistently outperforms the baseline which select top papers based on the highest average ratings.
MORSE-STF: A Privacy Preserving Computation System
Sep 24, 2021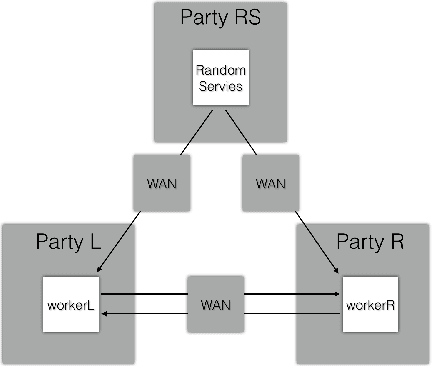
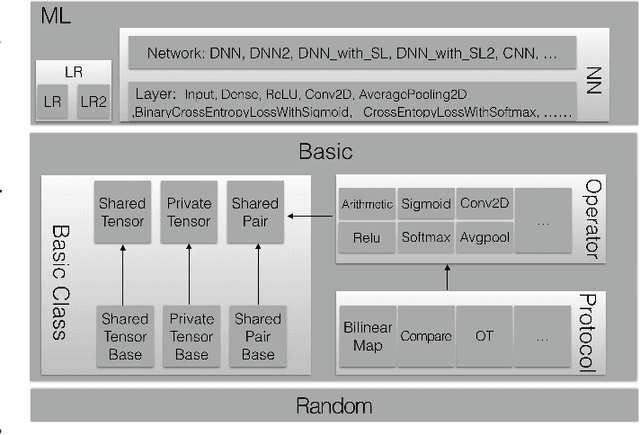
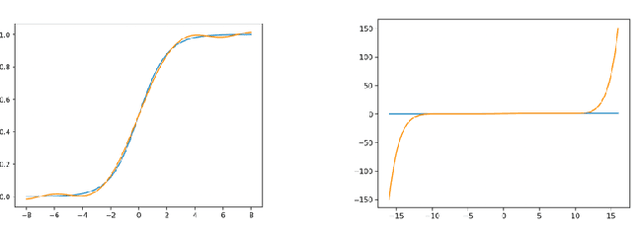
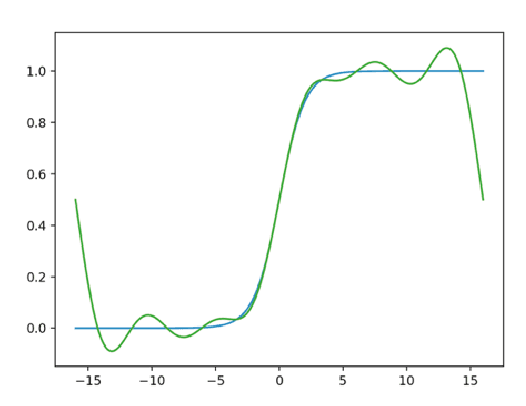
Privacy-preserving machine learning has become a popular area of research due to the increasing concern over data privacy. One way to achieve privacy-preserving machine learning is to use secure multi-party computation, where multiple distrusting parties can perform computations on data without revealing the data itself. We present Secure-TF, a privacy-preserving machine learning framework based on MPC. Our framework is able to support widely-used machine learning models such as logistic regression, fully-connected neural network, and convolutional neural network. We propose novel cryptographic protocols that has lower round complexity and less communication for computing sigmoid, ReLU, conv2D and there derivatives. All are central building blocks for modern machine learning models. With our more efficient protocols, our system is able to outperform previous state-of-the-art privacy-preserving machine learning framework in the WAN setting.
CryptGPU: Fast Privacy-Preserving Machine Learning on the GPU
Apr 22, 2021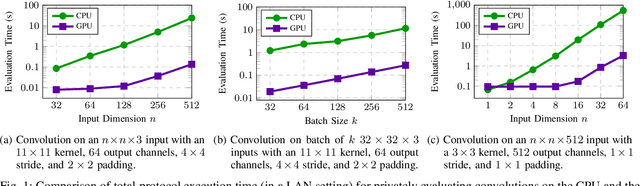
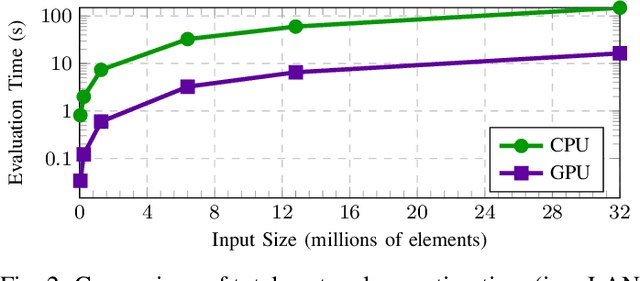
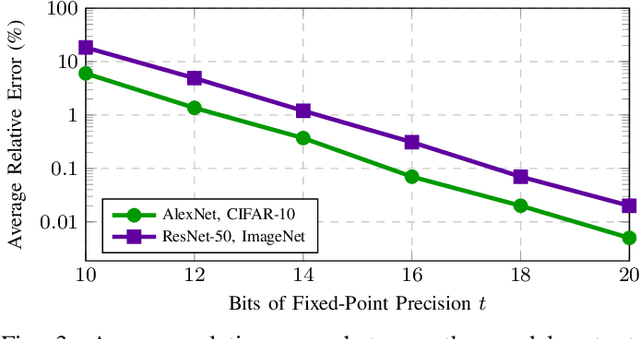
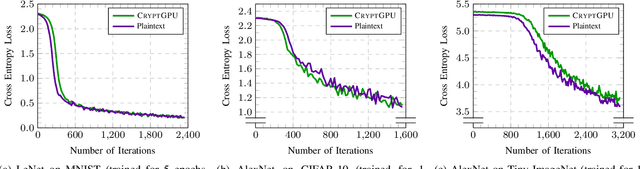
We introduce CryptGPU, a system for privacy-preserving machine learning that implements all operations on the GPU (graphics processing unit). Just as GPUs played a pivotal role in the success of modern deep learning, they are also essential for realizing scalable privacy-preserving deep learning. In this work, we start by introducing a new interface to losslessly embed cryptographic operations over secret-shared values (in a discrete domain) into floating-point operations that can be processed by highly-optimized CUDA kernels for linear algebra. We then identify a sequence of "GPU-friendly" cryptographic protocols to enable privacy-preserving evaluation of both linear and non-linear operations on the GPU. Our microbenchmarks indicate that our private GPU-based convolution protocol is over 150x faster than the analogous CPU-based protocol; for non-linear operations like the ReLU activation function, our GPU-based protocol is around 10x faster than its CPU analog. With CryptGPU, we support private inference and private training on convolutional neural networks with over 60 million parameters as well as handle large datasets like ImageNet. Compared to the previous state-of-the-art, when considering large models and datasets, our protocols achieve a 2x to 8x improvement in private inference and a 6x to 36x improvement for private training. Our work not only showcases the viability of performing secure multiparty computation (MPC) entirely on the GPU to enable fast privacy-preserving machine learning, but also highlights the importance of designing new MPC primitives that can take full advantage of the GPU's computing capabilities.