 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA data-driven model-free physical-informed deep operator network for solving nonlinear dynamic system
Feb 22, 2026The existing physical-informed Deep Operator Networks are mostly based on either the well-known mathematical formula of the system or huge amounts of data for different scenarios. However, in some cases, it is difficult to get the exact mathematical formula and vast amounts of data in some dynamic systems, we can only get a few experimental data or limited mathematical information. To address the cases, we propose a data-driven model-free physical-informed Deep Operator Network (DeepOnet) framework to learn the nonlinear dynamic systems from few available data. We first explore the short-term dependence of the available data and use a surrogate machine learning model to extract the short-term dependence. Then, the surrogate machine learning model is incorporated into the DeepOnet as the physical information part. Then, the constructed DeepOnet is trained to simulate the system's dynamic response for given control inputs and initial conditions. Numerical experiments on different systems confirm that our DeepOnet framework learns to approximate the dynamic response of some nonlinear dynamic systems effectively.
Towards Instance-wise Personalized Federated Learning via Semi-Implicit Bayesian Prompt Tuning
Aug 27, 2025Federated learning (FL) is a privacy-preserving machine learning paradigm that enables collaborative model training across multiple distributed clients without disclosing their raw data. Personalized federated learning (pFL) has gained increasing attention for its ability to address data heterogeneity. However, most existing pFL methods assume that each client's data follows a single distribution and learn one client-level personalized model for each client. This assumption often fails in practice, where a single client may possess data from multiple sources or domains, resulting in significant intra-client heterogeneity and suboptimal performance. To tackle this challenge, we propose pFedBayesPT, a fine-grained instance-wise pFL framework based on visual prompt tuning. Specifically, we formulate instance-wise prompt generation from a Bayesian perspective and model the prompt posterior as an implicit distribution to capture diverse visual semantics. We derive a variational training objective under the semi-implicit variational inference framework. Extensive experiments on benchmark datasets demonstrate that pFedBayesPT consistently outperforms existing pFL methods under both feature and label heterogeneity settings.
ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank Compression
Dec 13, 2024Offsite-tuning is a privacy-preserving method for tuning large language models (LLMs) by sharing a lossy compressed emulator from the LLM owners with data owners for downstream task tuning. This approach protects the privacy of both the model and data owners. However, current offsite tuning methods often suffer from adaptation degradation, high computational costs, and limited protection strength due to uniformly dropping LLM layers or relying on expensive knowledge distillation. To address these issues, we propose ScaleOT, a novel privacy-utility-scalable offsite-tuning framework that effectively balances privacy and utility. ScaleOT introduces a novel layerwise lossy compression algorithm that uses reinforcement learning to obtain the importance of each layer. It employs lightweight networks, termed harmonizers, to replace the raw LLM layers. By combining important original LLM layers and harmonizers in different ratios, ScaleOT generates emulators tailored for optimal performance with various model scales for enhanced privacy protection. Additionally, we present a rank reduction method to further compress the original LLM layers, significantly enhancing privacy with negligible impact on utility. Comprehensive experiments show that ScaleOT can achieve nearly lossless offsite tuning performance compared with full fine-tuning while obtaining better model privacy.
Layer-wise Importance Matters: Less Memory for Better Performance in Parameter-efficient Fine-tuning of Large Language Models
Oct 15, 2024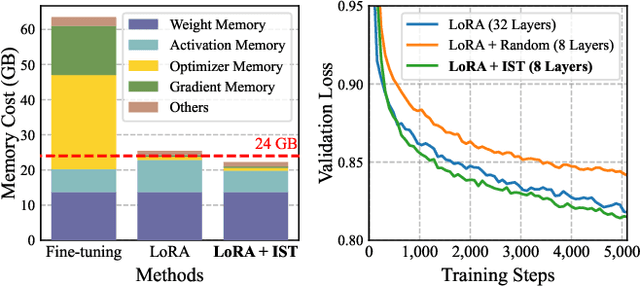
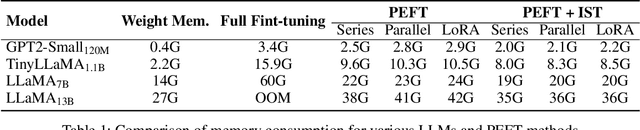
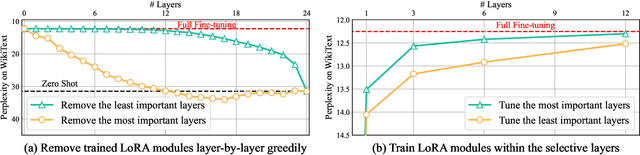
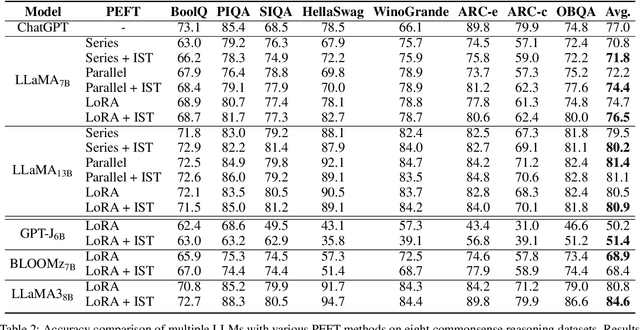
Parameter-Efficient Fine-Tuning (PEFT) methods have gained significant popularity for adapting pre-trained Large Language Models (LLMs) to downstream tasks, primarily due to their potential to significantly reduce memory and computational overheads. However, a common limitation in most PEFT approaches is their application of a uniform architectural design across all layers. This uniformity involves identical trainable modules and ignores the varying importance of each layer, leading to sub-optimal fine-tuning results. To overcome the above limitation and obtain better performance, we develop a novel approach, Importance-aware Sparse Tuning (IST), to fully utilize the inherent sparsity and select the most important subset of full layers with effective layer-wise importance scoring. The proposed IST is a versatile and plug-and-play technique compatible with various PEFT methods that operate on a per-layer basis. By leveraging the estimated importance scores, IST dynamically updates these selected layers in PEFT modules, leading to reduced memory demands. We further provide theoretical proof of convergence and empirical evidence of superior performance to demonstrate the advantages of IST over uniform updating strategies. Extensive experiments on a range of LLMs, PEFTs, and downstream tasks substantiate the effectiveness of our proposed method, showcasing IST's capacity to enhance existing layer-based PEFT methods. Our code is available at https://github.com/Kaiseem/IST.
MORSE-STF: A Privacy Preserving Computation System
Sep 24, 2021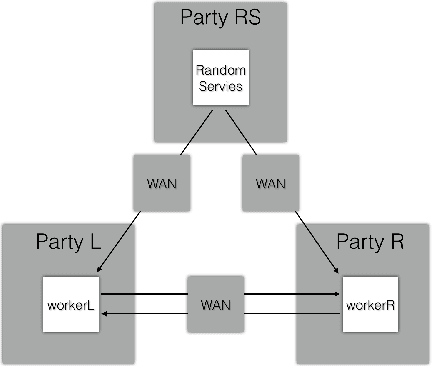
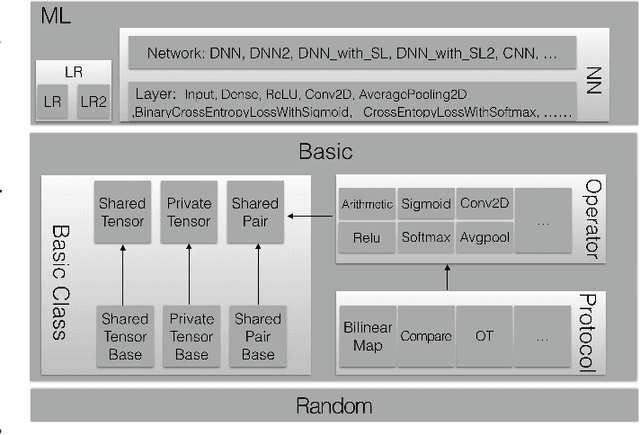
Privacy-preserving machine learning has become a popular area of research due to the increasing concern over data privacy. One way to achieve privacy-preserving machine learning is to use secure multi-party computation, where multiple distrusting parties can perform computations on data without revealing the data itself. We present Secure-TF, a privacy-preserving machine learning framework based on MPC. Our framework is able to support widely-used machine learning models such as logistic regression, fully-connected neural network, and convolutional neural network. We propose novel cryptographic protocols that has lower round complexity and less communication for computing sigmoid, ReLU, conv2D and there derivatives. All are central building blocks for modern machine learning models. With our more efficient protocols, our system is able to outperform previous state-of-the-art privacy-preserving machine learning framework in the WAN setting.
MPC Protocol for G-module and its Application in Secure Compare and ReLU
Jul 08, 2020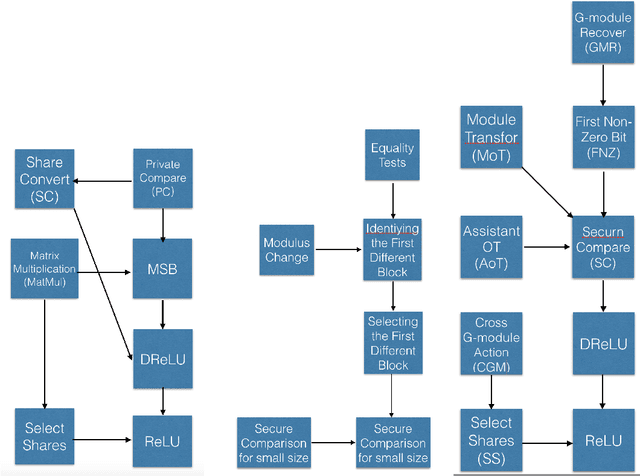



Secure multi-party computation (MPC) is a subfield of cryptography. Its aim is creating methods for multiple parties to jointly compute a function over their inputs meanwhile keeping their inputs privately. The Secure Compare problem, introduced by Yao under the name millionaire's problem, is an important problem in MPC. On the other hand, Privacy Preserving Machine Learning (PPML) is an intersectional field of cryptography and machine learning. It allows a group of independent data owners to collaboratively learn a model over their data sets without exposing their private data. MPC is a common cryptographic technique commonly used in PPML. In Deep learning, ReLU is an important layer. In order to train neural network to use MPC, we need an MPC protocol for ReLU and DReLU (the derivative of ReLU) in forward propagation and backward propagation of neural network respectively. In this paper, we give two new tools "G-module action" and "G-module recover" for MPC protocol, and use them to give the protocols for Secure Compare, DReLU and ReLU. The total communication in online and offline of our protocols is much less than the state of the art.