 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimbing the Ladder of Reasoning: What LLMs Can-and Still Can't-Solve after SFT?
Apr 16, 2025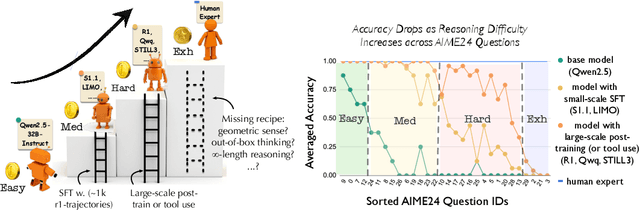

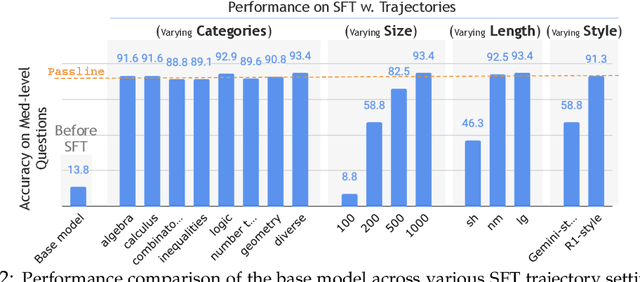
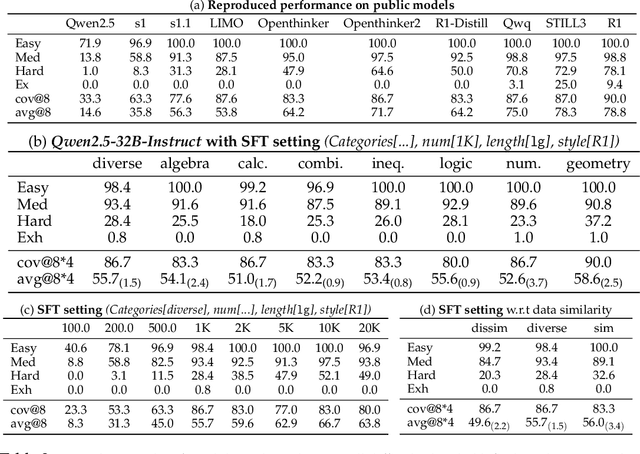
Recent supervised fine-tuning (SFT) approaches have significantly improved language models' performance on mathematical reasoning tasks, even when models are trained at a small scale. However, the specific capabilities enhanced through such fine-tuning remain poorly understood. In this paper, we conduct a detailed analysis of model performance on the AIME24 dataset to understand how reasoning capabilities evolve. We discover a ladder-like structure in problem difficulty, categorize questions into four tiers (Easy, Medium, Hard, and Extremely Hard (Exh)), and identify the specific requirements for advancing between tiers. We find that progression from Easy to Medium tier requires adopting an R1 reasoning style with minimal SFT (500-1K instances), while Hard-level questions suffer from frequent model's errors at each step of the reasoning chain, with accuracy plateauing at around 65% despite logarithmic scaling. Exh-level questions present a fundamentally different challenge; they require unconventional problem-solving skills that current models uniformly struggle with. Additional findings reveal that carefully curated small-scale datasets offer limited advantage-scaling dataset size proves far more effective. Our analysis provides a clearer roadmap for advancing language model capabilities in mathematical reasoning.
WorldModelBench: Judging Video Generation Models As World Models
Feb 28, 2025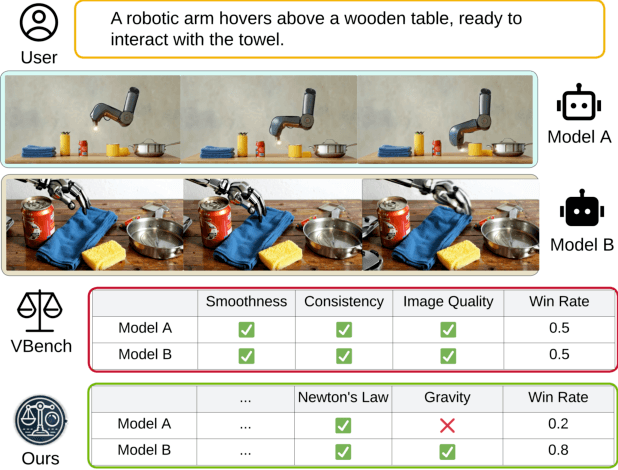
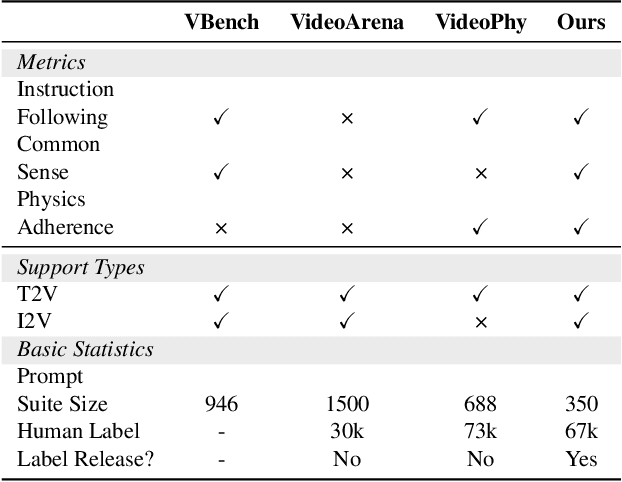
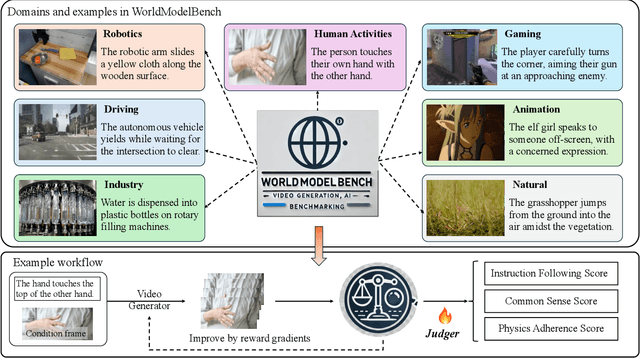
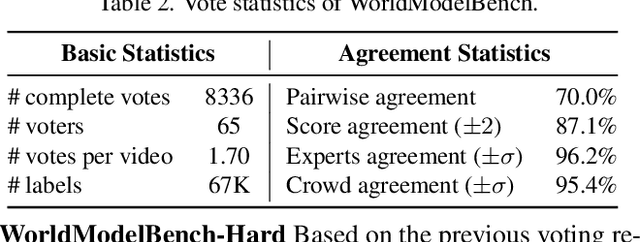
Video generation models have rapidly progressed, positioning themselves as video world models capable of supporting decision-making applications like robotics and autonomous driving. However, current benchmarks fail to rigorously evaluate these claims, focusing only on general video quality, ignoring important factors to world models such as physics adherence. To bridge this gap, we propose WorldModelBench, a benchmark designed to evaluate the world modeling capabilities of video generation models in application-driven domains. WorldModelBench offers two key advantages: (1) Against to nuanced world modeling violations: By incorporating instruction-following and physics-adherence dimensions, WorldModelBench detects subtle violations, such as irregular changes in object size that breach the mass conservation law - issues overlooked by prior benchmarks. (2) Aligned with large-scale human preferences: We crowd-source 67K human labels to accurately measure 14 frontier models. Using our high-quality human labels, we further fine-tune an accurate judger to automate the evaluation procedure, achieving 8.6% higher average accuracy in predicting world modeling violations than GPT-4o with 2B parameters. In addition, we demonstrate that training to align human annotations by maximizing the rewards from the judger noticeably improve the world modeling capability. The website is available at https://worldmodelbench-team.github.io.
S*: Test Time Scaling for Code Generation
Feb 20, 2025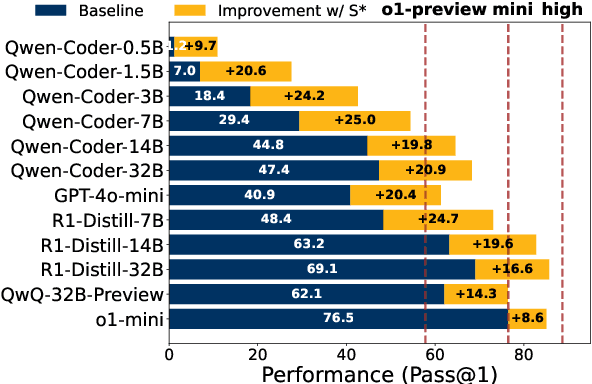
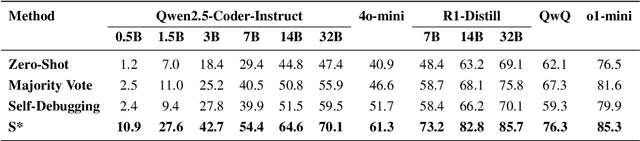
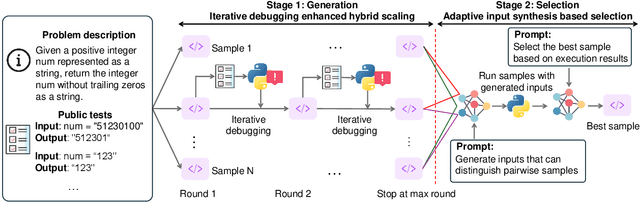
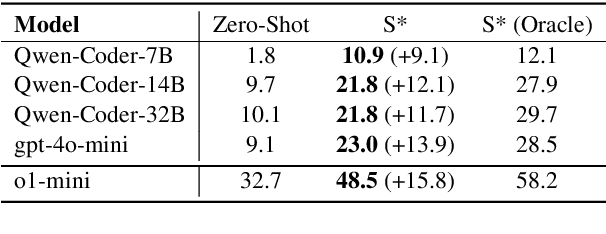
Increasing test-time compute for LLMs shows promise across domains but remains underexplored in code generation, despite extensive study in math. In this paper, we propose S*, the first hybrid test-time scaling framework that substantially improves the coverage and selection accuracy of generated code. S* extends the existing parallel scaling paradigm with sequential scaling to push performance boundaries. It further leverages a novel selection mechanism that adaptively generates distinguishing inputs for pairwise comparison, combined with execution-grounded information to robustly identify correct solutions. We evaluate across 12 Large Language Models and Large Reasoning Model and show: (1) S* consistently improves performance across model families and sizes, enabling a 3B model to outperform GPT-4o-mini; (2) S* enables non-reasoning models to surpass reasoning models - GPT-4o-mini with S* outperforms o1-preview by 3.7% on LiveCodeBench; (3) S* further boosts state-of-the-art reasoning models - DeepSeek-R1-Distill-Qwen-32B with S* achieves 85.7% on LiveCodeBench, approaching o1 (high) at 88.5%. Code will be available under https://github.com/NovaSky-AI/SkyThought.
The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks
Feb 12, 2025



Large Reasoning Models (LRMs) represent a breakthrough in AI problem-solving capabilities, but their effectiveness in interactive environments can be limited. This paper introduces and analyzes overthinking in LRMs. A phenomenon where models favor extended internal reasoning chains over environmental interaction. Through experiments on software engineering tasks using SWE Bench Verified, we observe three recurring patterns: Analysis Paralysis, Rogue Actions, and Premature Disengagement. We propose a framework to study these behaviors, which correlates with human expert assessments, and analyze 4018 trajectories. We observe that higher overthinking scores correlate with decreased performance, with reasoning models exhibiting stronger tendencies toward overthinking compared to non-reasoning models. Our analysis reveals that simple efforts to mitigate overthinking in agentic environments, such as selecting the solution with the lower overthinking score, can improve model performance by almost 30% while reducing computational costs by 43%. These results suggest that mitigating overthinking has strong practical implications. We suggest that by leveraging native function-calling capabilities and selective reinforcement learning overthinking tendencies could be mitigated. We also open-source our evaluation framework and dataset to facilitate research in this direction at https://github.com/AlexCuadron/Overthinking.
LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!
Feb 11, 2025Large reasoning models (LRMs) tackle complex reasoning problems by following long chain-of-thoughts (Long CoT) that incorporate reflection, backtracking, and self-validation. However, the training techniques and data requirements to elicit Long CoT remain poorly understood. In this work, we find that a Large Language model (LLM) can effectively learn Long CoT reasoning through data-efficient supervised fine-tuning (SFT) and parameter-efficient low-rank adaptation (LoRA). With just 17k long CoT training samples, the Qwen2.5-32B-Instruct model achieves significant improvements on a wide range of math and coding benchmarks, including 56.7% (+40.0%) on AIME 2024 and 57.0% (+8.1%) on LiveCodeBench, competitive to the proprietary o1-preview model's score of 44.6% and 59.1%. More importantly, we find that the structure of Long CoT is critical to the learning process, whereas the content of individual reasoning steps has minimal impact. Perturbations affecting content, such as training on incorrect samples or removing reasoning keywords, have little impact on performance. In contrast, structural modifications that disrupt logical consistency in the Long CoT, such as shuffling or deleting reasoning steps, significantly degrade accuracy. For example, a model trained on Long CoT samples with incorrect answers still achieves only 3.2% lower accuracy compared to training with fully correct samples. These insights deepen our understanding of how to elicit reasoning capabilities in LLMs and highlight key considerations for efficiently training the next generation of reasoning models. This is the academic paper of our previous released Sky-T1-32B-Preview model. Codes are available at https://github.com/NovaSky-AI/SkyThought.
Efficient-vDiT: Efficient Video Diffusion Transformers With Attention Tile
Feb 10, 2025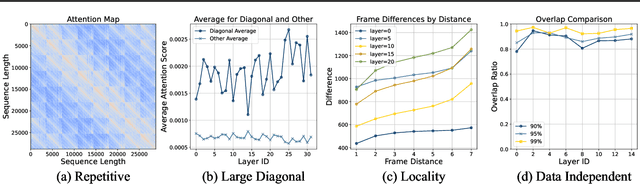
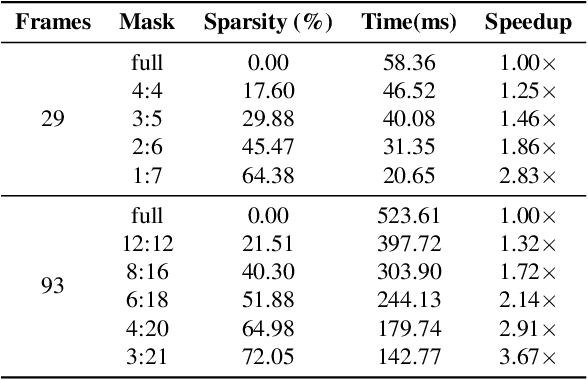


Despite the promise of synthesizing high-fidelity videos, Diffusion Transformers (DiTs) with 3D full attention suffer from expensive inference due to the complexity of attention computation and numerous sampling steps. For example, the popular Open-Sora-Plan model consumes more than 9 minutes for generating a single video of 29 frames. This paper addresses the inefficiency issue from two aspects: 1) Prune the 3D full attention based on the redundancy within video data; We identify a prevalent tile-style repetitive pattern in the 3D attention maps for video data, and advocate a new family of sparse 3D attention that holds a linear complexity w.r.t. the number of video frames. 2) Shorten the sampling process by adopting existing multi-step consistency distillation; We split the entire sampling trajectory into several segments and perform consistency distillation within each one to activate few-step generation capacities. We further devise a three-stage training pipeline to conjoin the low-complexity attention and few-step generation capacities. Notably, with 0.1% pretraining data, we turn the Open-Sora-Plan-1.2 model into an efficient one that is 7.4x -7.8x faster for 29 and 93 frames 720p video generation with a marginal performance trade-off in VBench. In addition, we demonstrate that our approach is amenable to distributed inference, achieving an additional 3.91x speedup when running on 4 GPUs with sequence parallelism.
Sparse VideoGen: Accelerating Video Diffusion Transformers with Spatial-Temporal Sparsity
Feb 03, 2025



Diffusion Transformers (DiTs) dominate video generation but their high computational cost severely limits real-world applicability, usually requiring tens of minutes to generate a few seconds of video even on high-performance GPUs. This inefficiency primarily arises from the quadratic computational complexity of 3D Full Attention with respect to the context length. In this paper, we propose a training-free framework termed Sparse VideoGen (SVG) that leverages the inherent sparsity in 3D Full Attention to boost inference efficiency. We reveal that the attention heads can be dynamically classified into two groups depending on distinct sparse patterns: (1) Spatial Head, where only spatially-related tokens within each frame dominate the attention output, and (2) Temporal Head, where only temporally-related tokens across different frames dominate. Based on this insight, SVG proposes an online profiling strategy to capture the dynamic sparse patterns and predicts the type of attention head. Combined with a novel hardware-efficient tensor layout transformation and customized kernel implementations, SVG achieves up to 2.28x and 2.33x end-to-end speedup on CogVideoX-v1.5 and HunyuanVideo, respectively, while preserving generation quality.
Locality-aware Fair Scheduling in LLM Serving
Jan 24, 2025

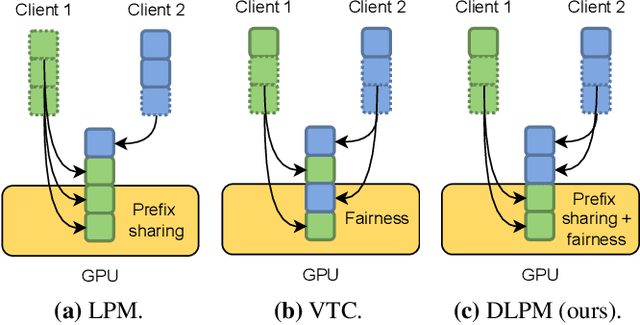
Large language model (LLM) inference workload dominates a wide variety of modern AI applications, ranging from multi-turn conversation to document analysis. Balancing fairness and efficiency is critical for managing diverse client workloads with varying prefix patterns. Unfortunately, existing fair scheduling algorithms for LLM serving, such as Virtual Token Counter (VTC), fail to take prefix locality into consideration and thus suffer from poor performance. On the other hand, locality-aware scheduling algorithms in existing LLM serving frameworks tend to maximize the prefix cache hit rate without considering fair sharing among clients. This paper introduces the first locality-aware fair scheduling algorithm, Deficit Longest Prefix Match (DLPM), which can maintain a high degree of prefix locality with a fairness guarantee. We also introduce a novel algorithm, Double Deficit LPM (D$^2$LPM), extending DLPM for the distributed setup that can find a balance point among fairness, locality, and load-balancing. Our extensive evaluation demonstrates the superior performance of DLPM and D$^2$LPM in ensuring fairness while maintaining high throughput (up to 2.87$\times$ higher than VTC) and low per-client (up to 7.18$\times$ lower than state-of-the-art distributed LLM serving system) latency.
NVILA: Efficient Frontier Visual Language Models
Dec 05, 2024
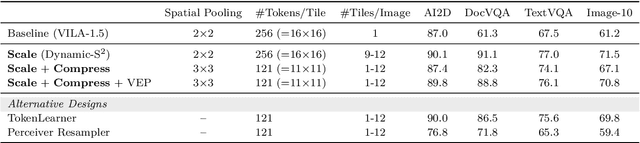

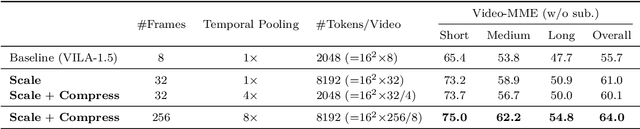
Visual language models (VLMs) have made significant advances in accuracy in recent years. However, their efficiency has received much less attention. This paper introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy. Building on top of VILA, we improve its model architecture by first scaling up the spatial and temporal resolutions, and then compressing visual tokens. This "scale-then-compress" approach enables NVILA to efficiently process high-resolution images and long videos. We also conduct a systematic investigation to enhance the efficiency of NVILA throughout its entire lifecycle, from training and fine-tuning to deployment. NVILA matches or surpasses the accuracy of many leading open and proprietary VLMs across a wide range of image and video benchmarks. At the same time, it reduces training costs by 4.5X, fine-tuning memory usage by 3.4X, pre-filling latency by 1.6-2.2X, and decoding latency by 1.2-2.8X. We will soon make our code and models available to facilitate reproducibility.
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Sep 06, 2024


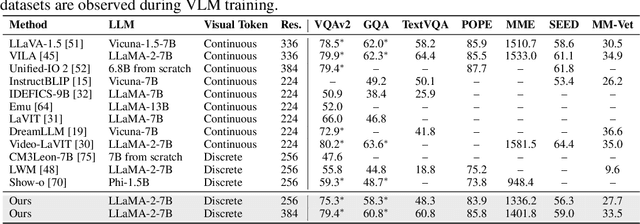
VILA-U is a Unified foundation model that integrates Video, Image, Language understanding and generation. Traditional visual language models (VLMs) use separate modules for understanding and generating visual content, which can lead to misalignment and increased complexity. In contrast, VILA-U employs a single autoregressive next-token prediction framework for both tasks, eliminating the need for additional components like diffusion models. This approach not only simplifies the model but also achieves near state-of-the-art performance in visual language understanding and generation. The success of VILA-U is attributed to two main factors: the unified vision tower that aligns discrete visual tokens with textual inputs during pretraining, which enhances visual perception, and autoregressive image generation can achieve similar quality as diffusion models with high-quality dataset. This allows VILA-U to perform comparably to more complex models using a fully token-based autoregressive framework.