 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient-vDiT: Efficient Video Diffusion Transformers With Attention Tile
Feb 10, 2025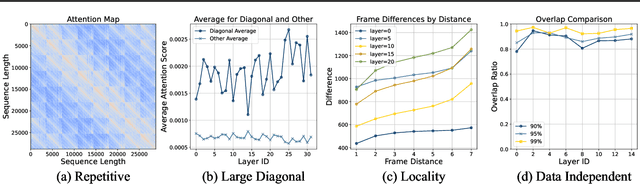
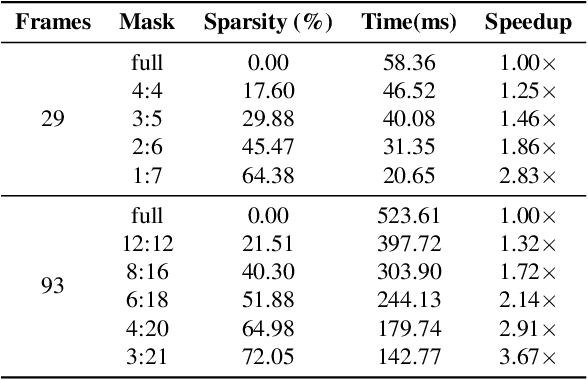


Despite the promise of synthesizing high-fidelity videos, Diffusion Transformers (DiTs) with 3D full attention suffer from expensive inference due to the complexity of attention computation and numerous sampling steps. For example, the popular Open-Sora-Plan model consumes more than 9 minutes for generating a single video of 29 frames. This paper addresses the inefficiency issue from two aspects: 1) Prune the 3D full attention based on the redundancy within video data; We identify a prevalent tile-style repetitive pattern in the 3D attention maps for video data, and advocate a new family of sparse 3D attention that holds a linear complexity w.r.t. the number of video frames. 2) Shorten the sampling process by adopting existing multi-step consistency distillation; We split the entire sampling trajectory into several segments and perform consistency distillation within each one to activate few-step generation capacities. We further devise a three-stage training pipeline to conjoin the low-complexity attention and few-step generation capacities. Notably, with 0.1% pretraining data, we turn the Open-Sora-Plan-1.2 model into an efficient one that is 7.4x -7.8x faster for 29 and 93 frames 720p video generation with a marginal performance trade-off in VBench. In addition, we demonstrate that our approach is amenable to distributed inference, achieving an additional 3.91x speedup when running on 4 GPUs with sequence parallelism.
Fast Video Generation with Sliding Tile Attention
Feb 06, 2025


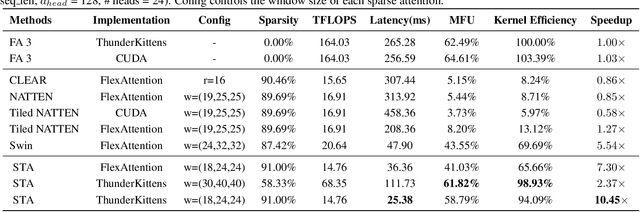
Diffusion Transformers (DiTs) with 3D full attention power state-of-the-art video generation, but suffer from prohibitive compute cost -- when generating just a 5-second 720P video, attention alone takes 800 out of 945 seconds of total inference time. This paper introduces sliding tile attention (STA) to address this challenge. STA leverages the observation that attention scores in pretrained video diffusion models predominantly concentrate within localized 3D windows. By sliding and attending over the local spatial-temporal region, STA eliminates redundancy from full attention. Unlike traditional token-wise sliding window attention (SWA), STA operates tile-by-tile with a novel hardware-aware sliding window design, preserving expressiveness while being hardware-efficient. With careful kernel-level optimizations, STA offers the first efficient 2D/3D sliding-window-like attention implementation, achieving 58.79% MFU. Precisely, STA accelerates attention by 2.8-17x over FlashAttention-2 (FA2) and 1.6-10x over FlashAttention-3 (FA3). On the leading video DiT, HunyuanVideo, STA reduces end-to-end latency from 945s (FA3) to 685s without quality degradation, requiring no training. Enabling finetuning further lowers latency to 268s with only a 0.09% drop on VBench.
Efficient LLM Scheduling by Learning to Rank
Aug 28, 2024

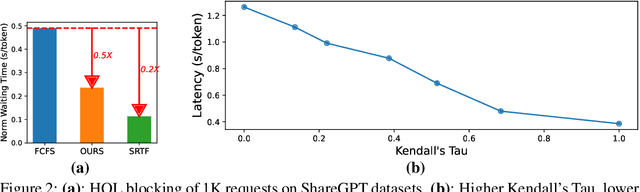

In Large Language Model (LLM) inference, the output length of an LLM request is typically regarded as not known a priori. Consequently, most LLM serving systems employ a simple First-come-first-serve (FCFS) scheduling strategy, leading to Head-Of-Line (HOL) blocking and reduced throughput and service quality. In this paper, we reexamine this assumption -- we show that, although predicting the exact generation length of each request is infeasible, it is possible to predict the relative ranks of output lengths in a batch of requests, using learning to rank. The ranking information offers valuable guidance for scheduling requests. Building on this insight, we develop a novel scheduler for LLM inference and serving that can approximate the shortest-job-first (SJF) schedule better than existing approaches. We integrate this scheduler with the state-of-the-art LLM serving system and show significant performance improvement in several important applications: 2.8x lower latency in chatbot serving and 6.5x higher throughput in synthetic data generation. Our code is available at https://github.com/hao-ai-lab/vllm-ltr.git