 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient-vDiT: Efficient Video Diffusion Transformers With Attention Tile
Feb 10, 2025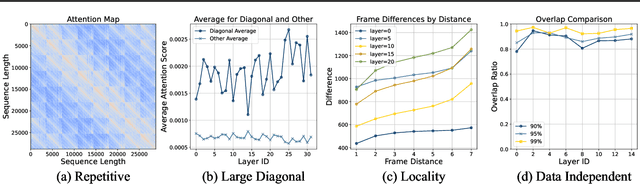
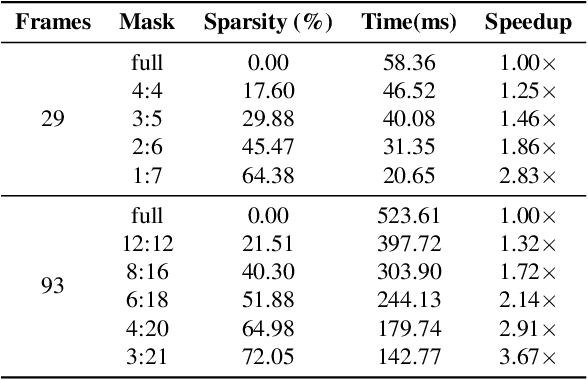


Despite the promise of synthesizing high-fidelity videos, Diffusion Transformers (DiTs) with 3D full attention suffer from expensive inference due to the complexity of attention computation and numerous sampling steps. For example, the popular Open-Sora-Plan model consumes more than 9 minutes for generating a single video of 29 frames. This paper addresses the inefficiency issue from two aspects: 1) Prune the 3D full attention based on the redundancy within video data; We identify a prevalent tile-style repetitive pattern in the 3D attention maps for video data, and advocate a new family of sparse 3D attention that holds a linear complexity w.r.t. the number of video frames. 2) Shorten the sampling process by adopting existing multi-step consistency distillation; We split the entire sampling trajectory into several segments and perform consistency distillation within each one to activate few-step generation capacities. We further devise a three-stage training pipeline to conjoin the low-complexity attention and few-step generation capacities. Notably, with 0.1% pretraining data, we turn the Open-Sora-Plan-1.2 model into an efficient one that is 7.4x -7.8x faster for 29 and 93 frames 720p video generation with a marginal performance trade-off in VBench. In addition, we demonstrate that our approach is amenable to distributed inference, achieving an additional 3.91x speedup when running on 4 GPUs with sequence parallelism.
Fast Video Generation with Sliding Tile Attention
Feb 06, 2025


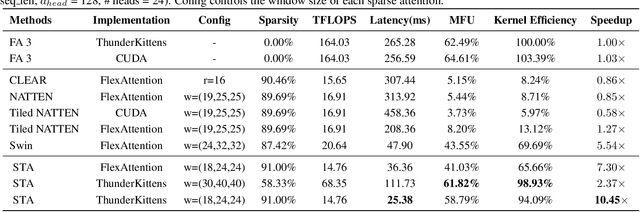
Diffusion Transformers (DiTs) with 3D full attention power state-of-the-art video generation, but suffer from prohibitive compute cost -- when generating just a 5-second 720P video, attention alone takes 800 out of 945 seconds of total inference time. This paper introduces sliding tile attention (STA) to address this challenge. STA leverages the observation that attention scores in pretrained video diffusion models predominantly concentrate within localized 3D windows. By sliding and attending over the local spatial-temporal region, STA eliminates redundancy from full attention. Unlike traditional token-wise sliding window attention (SWA), STA operates tile-by-tile with a novel hardware-aware sliding window design, preserving expressiveness while being hardware-efficient. With careful kernel-level optimizations, STA offers the first efficient 2D/3D sliding-window-like attention implementation, achieving 58.79% MFU. Precisely, STA accelerates attention by 2.8-17x over FlashAttention-2 (FA2) and 1.6-10x over FlashAttention-3 (FA3). On the leading video DiT, HunyuanVideo, STA reduces end-to-end latency from 945s (FA3) to 685s without quality degradation, requiring no training. Enabling finetuning further lowers latency to 268s with only a 0.09% drop on VBench.
MiniKV: Pushing the Limits of LLM Inference via 2-Bit Layer-Discriminative KV Cache
Nov 28, 2024
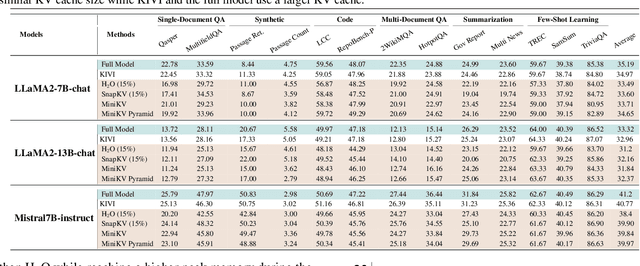

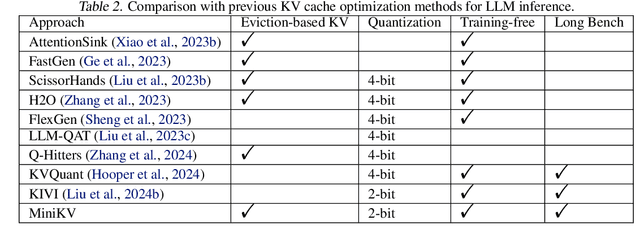
How to efficiently serve LLMs in practice has become exceptionally challenging due to their prohibitive memory and computation requirements. In this study, we investigate optimizing the KV cache, whose memory footprint poses a critical bottleneck in LLM inference, especially when dealing with long context tasks. To tackle the challenge, we introduce MiniKV, a KV cache optimization method that simultaneously preserves long context task accuracy while significantly reducing KV cache size via a novel 2-bit layer-discriminative KV cache. More importantly, we develop specialized CUDA kernels to make MiniKV compatible with FlashAttention. Experiments on a wide range of long context tasks show that MiniKV effectively achieves 86% KV cache compression ratio while recovering over 98.5% of accuracy, outperforming state-of-the-art methods while achieving excellent measured system performance improvements.
Pushing the Limits of LLM Inference via 2-Bit Layer-Discriminative KV Cache
Nov 27, 2024How to efficiently serve LLMs in practice has become exceptionally challenging due to their prohibitive memory and computation requirements. In this study, we investigate optimizing the KV cache, whose memory footprint poses a critical bottleneck in LLM inference, especially when dealing with long context tasks. To tackle the challenge, we introduce MiniKV, a KV cache optimization method that simultaneously preserves long context task accuracy while significantly reducing KV cache size via a novel 2-bit layer-discriminative KV cache. More importantly, we develop specialized CUDA kernels to make MiniKV compatible with FlashAttention. Experiments on a wide range of long context tasks show that MiniKV effectively achieves 86% KV cache compression ratio while recovering over 98.5% of accuracy, outperforming state-of-the-art methods while achieving excellent measured system performance improvements.
AgentBench: Evaluating LLMs as Agents
Aug 07, 2023



Large Language Models (LLMs) are becoming increasingly smart and autonomous, targeting real-world pragmatic missions beyond traditional NLP tasks. As a result, there has been an urgent need to evaluate LLMs as agents on challenging tasks in interactive environments. We present AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting. Our extensive test over 25 LLMs (including APIs and open-sourced models) shows that, while top commercial LLMs present a strong ability of acting as agents in complex environments, there is a significant disparity in performance between them and open-sourced competitors. It also serves as a component of an ongoing project with wider coverage and deeper consideration towards systematic LLM evaluation. Datasets, environments, and an integrated evaluation package for AgentBench are released at https://github.com/THUDM/AgentBench