 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniKV: Pushing the Limits of LLM Inference via 2-Bit Layer-Discriminative KV Cache
Nov 28, 2024
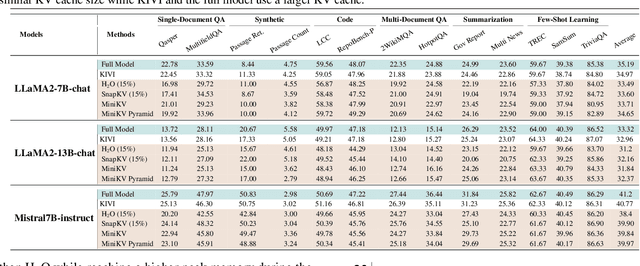

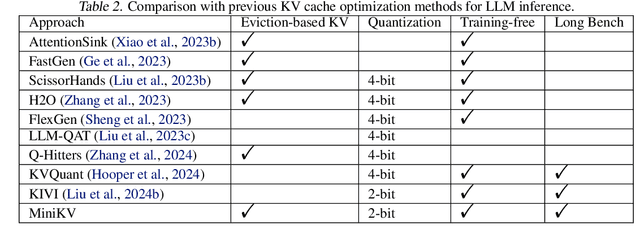
How to efficiently serve LLMs in practice has become exceptionally challenging due to their prohibitive memory and computation requirements. In this study, we investigate optimizing the KV cache, whose memory footprint poses a critical bottleneck in LLM inference, especially when dealing with long context tasks. To tackle the challenge, we introduce MiniKV, a KV cache optimization method that simultaneously preserves long context task accuracy while significantly reducing KV cache size via a novel 2-bit layer-discriminative KV cache. More importantly, we develop specialized CUDA kernels to make MiniKV compatible with FlashAttention. Experiments on a wide range of long context tasks show that MiniKV effectively achieves 86% KV cache compression ratio while recovering over 98.5% of accuracy, outperforming state-of-the-art methods while achieving excellent measured system performance improvements.
Pushing the Limits of LLM Inference via 2-Bit Layer-Discriminative KV Cache
Nov 27, 2024How to efficiently serve LLMs in practice has become exceptionally challenging due to their prohibitive memory and computation requirements. In this study, we investigate optimizing the KV cache, whose memory footprint poses a critical bottleneck in LLM inference, especially when dealing with long context tasks. To tackle the challenge, we introduce MiniKV, a KV cache optimization method that simultaneously preserves long context task accuracy while significantly reducing KV cache size via a novel 2-bit layer-discriminative KV cache. More importantly, we develop specialized CUDA kernels to make MiniKV compatible with FlashAttention. Experiments on a wide range of long context tasks show that MiniKV effectively achieves 86% KV cache compression ratio while recovering over 98.5% of accuracy, outperforming state-of-the-art methods while achieving excellent measured system performance improvements.
IL-TUR: Benchmark for Indian Legal Text Understanding and Reasoning
Jul 07, 2024Legal systems worldwide are inundated with exponential growth in cases and documents. There is an imminent need to develop NLP and ML techniques for automatically processing and understanding legal documents to streamline the legal system. However, evaluating and comparing various NLP models designed specifically for the legal domain is challenging. This paper addresses this challenge by proposing IL-TUR: Benchmark for Indian Legal Text Understanding and Reasoning. IL-TUR contains monolingual (English, Hindi) and multi-lingual (9 Indian languages) domain-specific tasks that address different aspects of the legal system from the point of view of understanding and reasoning over Indian legal documents. We present baseline models (including LLM-based) for each task, outlining the gap between models and the ground truth. To foster further research in the legal domain, we create a leaderboard (available at: https://exploration-lab.github.io/IL-TUR/) where the research community can upload and compare legal text understanding systems.
Adaptive Thresholding Heuristic for KPI Anomaly Detection
Aug 21, 2023



A plethora of outlier detectors have been explored in the time series domain, however, in a business sense, not all outliers are anomalies of interest. Existing anomaly detection solutions are confined to certain outlier detectors limiting their applicability to broader anomaly detection use cases. Network KPIs (Key Performance Indicators) tend to exhibit stochastic behaviour producing statistical outliers, most of which do not adversely affect business operations. Thus, a heuristic is required to capture the business definition of an anomaly for time series KPI. This article proposes an Adaptive Thresholding Heuristic (ATH) to dynamically adjust the detection threshold based on the local properties of the data distribution and adapt to changes in time series patterns. The heuristic derives the threshold based on the expected periodicity and the observed proportion of anomalies minimizing false positives and addressing concept drift. ATH can be used in conjunction with any underlying seasonality decomposition method and an outlier detector that yields an outlier score. This method has been tested on EON1-Cell-U, a labeled KPI anomaly dataset produced by Ericsson, to validate our hypothesis. Experimental results show that ATH is computationally efficient making it scalable for near real time anomaly detection and flexible with multiple forecasters and outlier detectors.
U-CREAT: Unsupervised Case Retrieval using Events extrAcTion
Jul 11, 2023The task of Prior Case Retrieval (PCR) in the legal domain is about automatically citing relevant (based on facts and precedence) prior legal cases in a given query case. To further promote research in PCR, in this paper, we propose a new large benchmark (in English) for the PCR task: IL-PCR (Indian Legal Prior Case Retrieval) corpus. Given the complex nature of case relevance and the long size of legal documents, BM25 remains a strong baseline for ranking the cited prior documents. In this work, we explore the role of events in legal case retrieval and propose an unsupervised retrieval method-based pipeline U-CREAT (Unsupervised Case Retrieval using Events Extraction). We find that the proposed unsupervised retrieval method significantly increases performance compared to BM25 and makes retrieval faster by a considerable margin, making it applicable to real-time case retrieval systems. Our proposed system is generic, we show that it generalizes across two different legal systems (Indian and Canadian), and it shows state-of-the-art performance on the benchmarks for both the legal systems (IL-PCR and COLIEE corpora).