 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILSIC: Corpora for Identifying Indian Legal Statutes from Queries by Laypeople
Jan 31, 2026Legal Statute Identification (LSI) for a given situation is one of the most fundamental tasks in Legal NLP. This task has traditionally been modeled using facts from court judgments as input queries, due to their abundance. However, in practical settings, the input queries are likely to be informal and asked by laypersons, or non-professionals. While a few laypeople LSI datasets exist, there has been little research to explore the differences between court and laypeople data for LSI. In this work, we create ILSIC, a corpus of laypeople queries covering 500+ statutes from Indian law. Additionally, the corpus also contains court case judgements to enable researchers to effectively compare between court and laypeople data for LSI. We conducted extensive experiments on our corpus, including benchmarking over the laypeople dataset using zero and few-shot inference, retrieval-augmented generation and supervised fine-tuning. We observe that models trained purely on court judgements are ineffective during test on laypeople queries, while transfer learning from court to laypeople data can be beneficial in certain scenarios. We also conducted fine-grained analyses of our results in terms of categories of queries and frequency of statutes.
IL-TUR: Benchmark for Indian Legal Text Understanding and Reasoning
Jul 07, 2024Legal systems worldwide are inundated with exponential growth in cases and documents. There is an imminent need to develop NLP and ML techniques for automatically processing and understanding legal documents to streamline the legal system. However, evaluating and comparing various NLP models designed specifically for the legal domain is challenging. This paper addresses this challenge by proposing IL-TUR: Benchmark for Indian Legal Text Understanding and Reasoning. IL-TUR contains monolingual (English, Hindi) and multi-lingual (9 Indian languages) domain-specific tasks that address different aspects of the legal system from the point of view of understanding and reasoning over Indian legal documents. We present baseline models (including LLM-based) for each task, outlining the gap between models and the ground truth. To foster further research in the legal domain, we create a leaderboard (available at: https://exploration-lab.github.io/IL-TUR/) where the research community can upload and compare legal text understanding systems.
Pre-training Transformers on Indian Legal Text
Sep 13, 2022
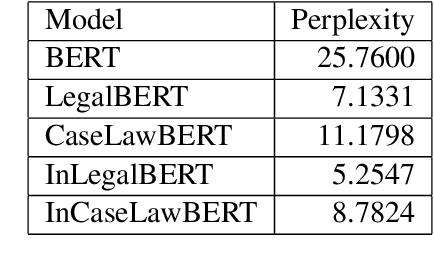
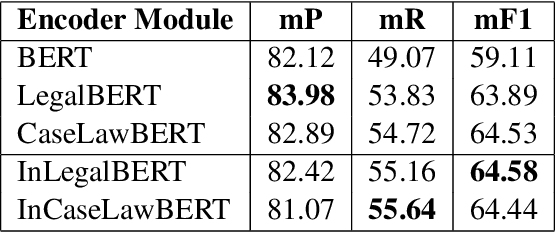
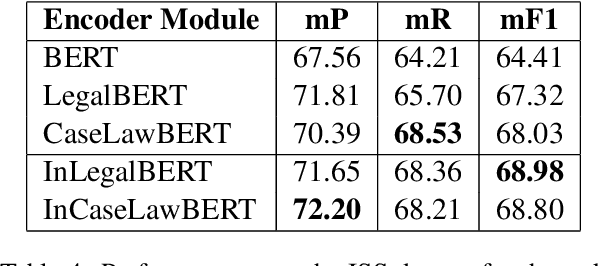
Natural Language Processing in the legal domain been benefited hugely by the emergence of Transformer-based Pre-trained Language Models (PLMs) pre-trained on legal text. There exist PLMs trained over European and US legal text, most notably LegalBERT. However, with the rapidly increasing volume of NLP applications on Indian legal documents, and the distinguishing characteristics of Indian legal text, it has become necessary to pre-train LMs over Indian legal text as well. In this work, we introduce transformer-based PLMs pre-trained over a large corpus of Indian legal documents. We also apply these PLMs over several benchmark legal NLP tasks over Indian legal documents, namely, Legal Statute Identification from facts, Semantic segmentation of court judgements, and Court Judgement Prediction. Our experiments demonstrate the utility of the India-specific PLMs developed in this work.
LeSICiN: A Heterogeneous Graph-based Approach for Automatic Legal Statute Identification from Indian Legal Documents
Dec 29, 2021
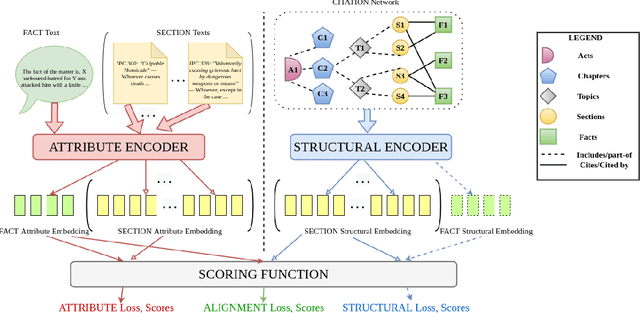

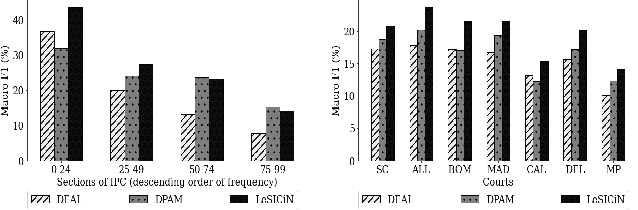
The task of Legal Statute Identification (LSI) aims to identify the legal statutes that are relevant to a given description of Facts or evidence of a legal case. Existing methods only utilize the textual content of Facts and legal articles to guide such a task. However, the citation network among case documents and legal statutes is a rich source of additional information, which is not considered by existing models. In this work, we take the first step towards utilising both the text and the legal citation network for the LSI task. We curate a large novel dataset for this task, including Facts of cases from several major Indian Courts of Law, and statutes from the Indian Penal Code (IPC). Modeling the statutes and training documents as a heterogeneous graph, our proposed model LeSICiN can learn rich textual and graphical features, and can also tune itself to correlate these features. Thereafter, the model can be used to inductively predict links between test documents (new nodes whose graphical features are not available to the model) and statutes (existing nodes). Extensive experiments on the dataset show that our model comfortably outperforms several state-of-the-art baselines, by exploiting the graphical structure along with textual features. The dataset and our codes are available at https://github.com/Law-AI/LeSICiN.