 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training Transformers on Indian Legal Text
Sep 13, 2022
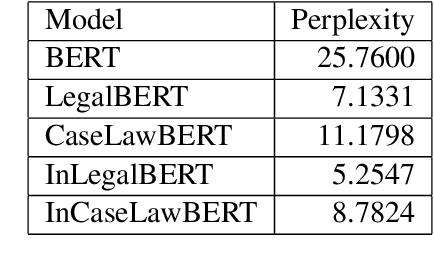
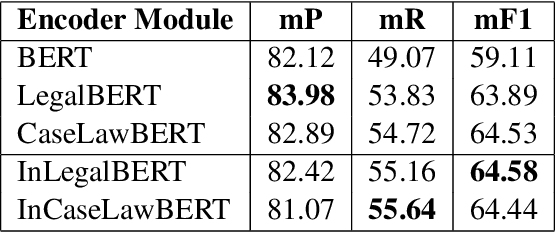
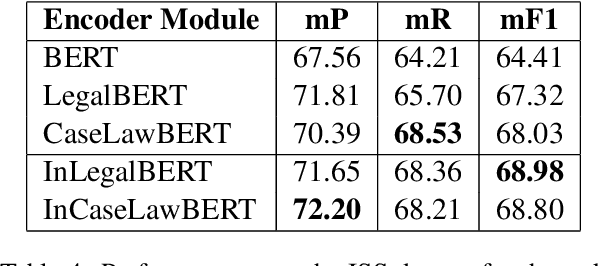
Natural Language Processing in the legal domain been benefited hugely by the emergence of Transformer-based Pre-trained Language Models (PLMs) pre-trained on legal text. There exist PLMs trained over European and US legal text, most notably LegalBERT. However, with the rapidly increasing volume of NLP applications on Indian legal documents, and the distinguishing characteristics of Indian legal text, it has become necessary to pre-train LMs over Indian legal text as well. In this work, we introduce transformer-based PLMs pre-trained over a large corpus of Indian legal documents. We also apply these PLMs over several benchmark legal NLP tasks over Indian legal documents, namely, Legal Statute Identification from facts, Semantic segmentation of court judgements, and Court Judgement Prediction. Our experiments demonstrate the utility of the India-specific PLMs developed in this work.