 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Quantifying Commonsense Reasoning with Mechanistic Insights
Apr 14, 2025Commonsense reasoning deals with the implicit knowledge that is well understood by humans and typically acquired via interactions with the world. In recent times, commonsense reasoning and understanding of various LLMs have been evaluated using text-based tasks. In this work, we argue that a proxy of this understanding can be maintained as a graphical structure that can further help to perform a rigorous evaluation of commonsense reasoning abilities about various real-world activities. We create an annotation scheme for capturing this implicit knowledge in the form of a graphical structure for 37 daily human activities. We find that the created resource can be used to frame an enormous number of commonsense queries (~ 10^{17}), facilitating rigorous evaluation of commonsense reasoning in LLMs. Moreover, recently, the remarkable performance of LLMs has raised questions about whether these models are truly capable of reasoning in the wild and, in general, how reasoning occurs inside these models. In this resource paper, we bridge this gap by proposing design mechanisms that facilitate research in a similar direction. Our findings suggest that the reasoning components are localized in LLMs that play a prominent role in decision-making when prompted with a commonsense query.
COLD: Causal reasOning in cLosed Daily activities
Nov 29, 2024
Large Language Models (LLMs) have shown state-of-the-art performance in a variety of tasks, including arithmetic and reasoning; however, to gauge the intellectual capabilities of LLMs, causal reasoning has become a reliable proxy for validating a general understanding of the mechanics and intricacies of the world similar to humans. Previous works in natural language processing (NLP) have either focused on open-ended causal reasoning via causal commonsense reasoning (CCR) or framed a symbolic representation-based question answering for theoretically backed-up analysis via a causal inference engine. The former adds an advantage of real-world grounding but lacks theoretically backed-up analysis/validation, whereas the latter is far from real-world grounding. In this work, we bridge this gap by proposing the COLD (Causal reasOning in cLosed Daily activities) framework, which is built upon human understanding of daily real-world activities to reason about the causal nature of events. We show that the proposed framework facilitates the creation of enormous causal queries (~ 9 million) and comes close to the mini-turing test, simulating causal reasoning to evaluate the understanding of a daily real-world task. We evaluate multiple LLMs on the created causal queries and find that causal reasoning is challenging even for activities trivial to humans. We further explore (the causal reasoning abilities of LLMs) using the backdoor criterion to determine the causal strength between events.
Towards Robust Evaluation of Unlearning in LLMs via Data Transformations
Nov 23, 2024
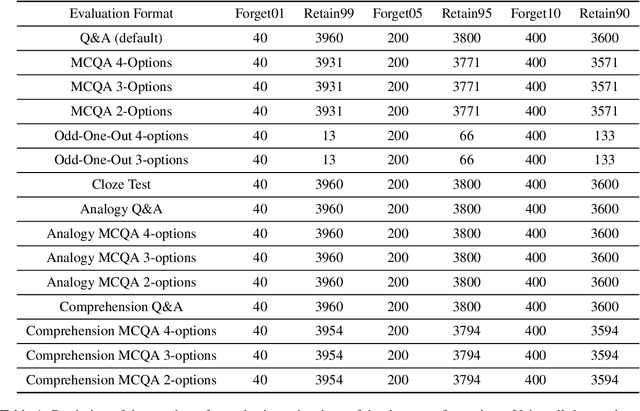


Large Language Models (LLMs) have shown to be a great success in a wide range of applications ranging from regular NLP-based use cases to AI agents. LLMs have been trained on a vast corpus of texts from various sources; despite the best efforts during the data pre-processing stage while training the LLMs, they may pick some undesirable information such as personally identifiable information (PII). Consequently, in recent times research in the area of Machine Unlearning (MUL) has become active, the main idea is to force LLMs to forget (unlearn) certain information (e.g., PII) without suffering from performance loss on regular tasks. In this work, we examine the robustness of the existing MUL techniques for their ability to enable leakage-proof forgetting in LLMs. In particular, we examine the effect of data transformation on forgetting, i.e., is an unlearned LLM able to recall forgotten information if there is a change in the format of the input? Our findings on the TOFU dataset highlight the necessity of using diverse data formats to quantify unlearning in LLMs more reliably.
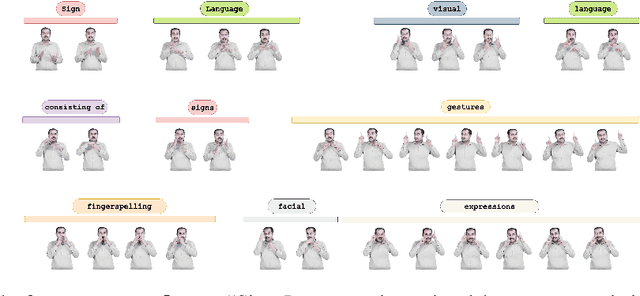
iSign: A Benchmark for Indian Sign Language Processing
Jul 07, 2024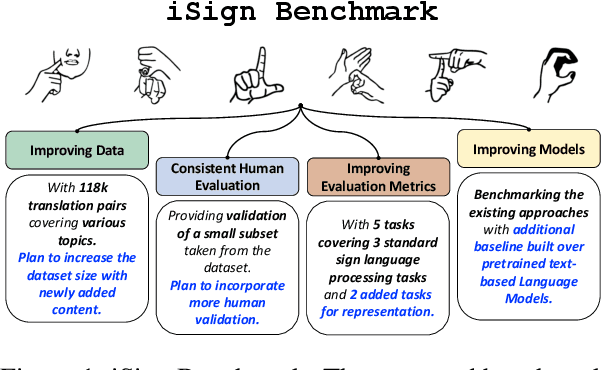
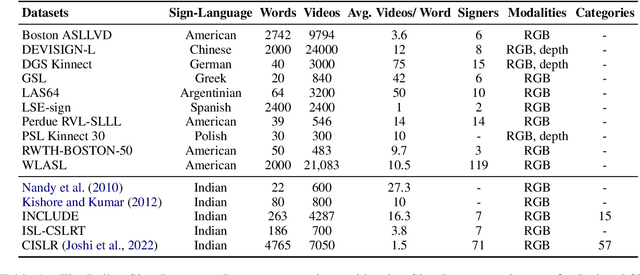

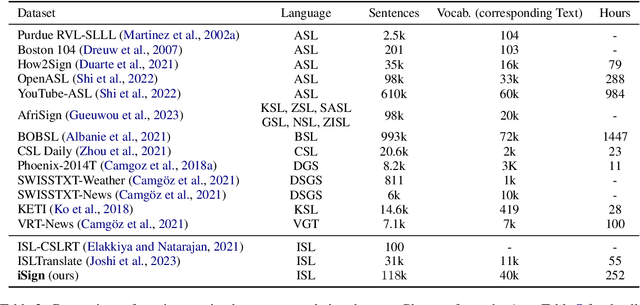
Indian Sign Language has limited resources for developing machine learning and data-driven approaches for automated language processing. Though text/audio-based language processing techniques have shown colossal research interest and tremendous improvements in the last few years, Sign Languages still need to catch up due to the need for more resources. To bridge this gap, in this work, we propose iSign: a benchmark for Indian Sign Language (ISL) Processing. We make three primary contributions to this work. First, we release one of the largest ISL-English datasets with more than 118K video-sentence/phrase pairs. To the best of our knowledge, it is the largest sign language dataset available for ISL. Second, we propose multiple NLP-specific tasks (including SignVideo2Text, SignPose2Text, Text2Pose, Word Prediction, and Sign Semantics) and benchmark them with the baseline models for easier access to the research community. Third, we provide detailed insights into the proposed benchmarks with a few linguistic insights into the workings of ISL. We streamline the evaluation of Sign Language processing, addressing the gaps in the NLP research community for Sign Languages. We release the dataset, tasks, and models via the following website: https://exploration-lab.github.io/iSign/
IL-TUR: Benchmark for Indian Legal Text Understanding and Reasoning
Jul 07, 2024Legal systems worldwide are inundated with exponential growth in cases and documents. There is an imminent need to develop NLP and ML techniques for automatically processing and understanding legal documents to streamline the legal system. However, evaluating and comparing various NLP models designed specifically for the legal domain is challenging. This paper addresses this challenge by proposing IL-TUR: Benchmark for Indian Legal Text Understanding and Reasoning. IL-TUR contains monolingual (English, Hindi) and multi-lingual (9 Indian languages) domain-specific tasks that address different aspects of the legal system from the point of view of understanding and reasoning over Indian legal documents. We present baseline models (including LLM-based) for each task, outlining the gap between models and the ground truth. To foster further research in the legal domain, we create a leaderboard (available at: https://exploration-lab.github.io/IL-TUR/) where the research community can upload and compare legal text understanding systems.
U-CREAT: Unsupervised Case Retrieval using Events extrAcTion
Jul 11, 2023The task of Prior Case Retrieval (PCR) in the legal domain is about automatically citing relevant (based on facts and precedence) prior legal cases in a given query case. To further promote research in PCR, in this paper, we propose a new large benchmark (in English) for the PCR task: IL-PCR (Indian Legal Prior Case Retrieval) corpus. Given the complex nature of case relevance and the long size of legal documents, BM25 remains a strong baseline for ranking the cited prior documents. In this work, we explore the role of events in legal case retrieval and propose an unsupervised retrieval method-based pipeline U-CREAT (Unsupervised Case Retrieval using Events Extraction). We find that the proposed unsupervised retrieval method significantly increases performance compared to BM25 and makes retrieval faster by a considerable margin, making it applicable to real-time case retrieval systems. Our proposed system is generic, we show that it generalizes across two different legal systems (Indian and Canadian), and it shows state-of-the-art performance on the benchmarks for both the legal systems (IL-PCR and COLIEE corpora).
ISLTranslate: Dataset for Translating Indian Sign Language
Jul 11, 2023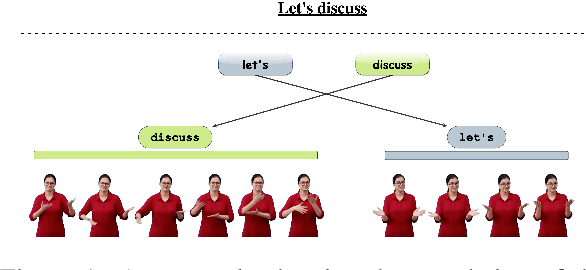
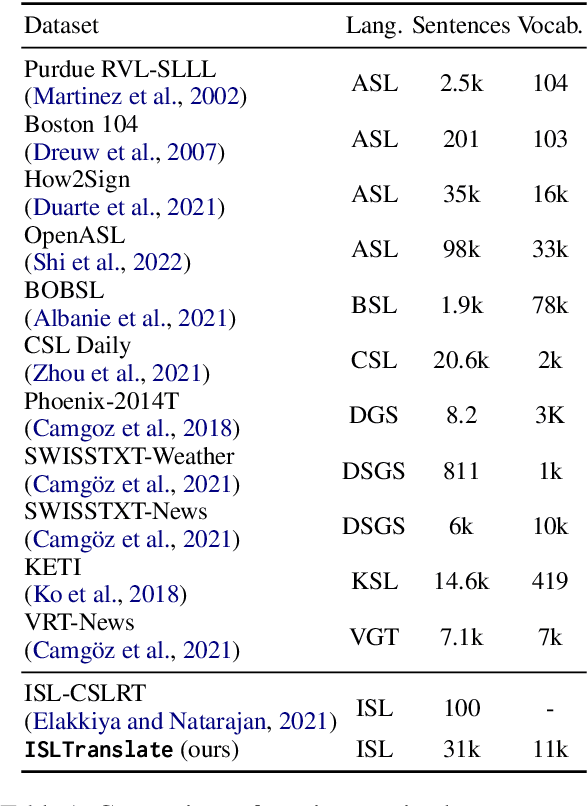

Sign languages are the primary means of communication for many hard-of-hearing people worldwide. Recently, to bridge the communication gap between the hard-of-hearing community and the rest of the population, several sign language translation datasets have been proposed to enable the development of statistical sign language translation systems. However, there is a dearth of sign language resources for the Indian sign language. This resource paper introduces ISLTranslate, a translation dataset for continuous Indian Sign Language (ISL) consisting of 31k ISL-English sentence/phrase pairs. To the best of our knowledge, it is the largest translation dataset for continuous Indian Sign Language. We provide a detailed analysis of the dataset. To validate the performance of existing end-to-end Sign language to spoken language translation systems, we benchmark the created dataset with a transformer-based model for ISL translation.
ScriptWorld: Text Based Environment For Learning Procedural Knowledge
Jul 08, 2023



Text-based games provide a framework for developing natural language understanding and commonsense knowledge about the world in reinforcement learning based agents. Existing text-based environments often rely on fictional situations and characters to create a gaming framework and are far from real-world scenarios. In this paper, we introduce ScriptWorld: a text-based environment for teaching agents about real-world daily chores and hence imparting commonsense knowledge. To the best of our knowledge, it is the first interactive text-based gaming framework that consists of daily real-world human activities designed using scripts dataset. We provide gaming environments for 10 daily activities and perform a detailed analysis of the proposed environment. We develop RL-based baseline models/agents to play the games in Scriptworld. To understand the role of language models in such environments, we leverage features obtained from pre-trained language models in the RL agents. Our experiments show that prior knowledge obtained from a pre-trained language model helps to solve real-world text-based gaming environments. We release the environment via Github: https://github.com/Exploration-Lab/ScriptWorld
SemEval 2023 Task 6: LegalEval - Understanding Legal Texts
May 01, 2023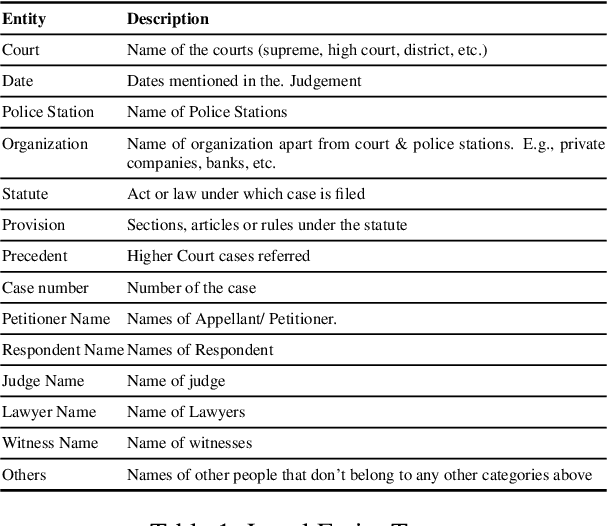


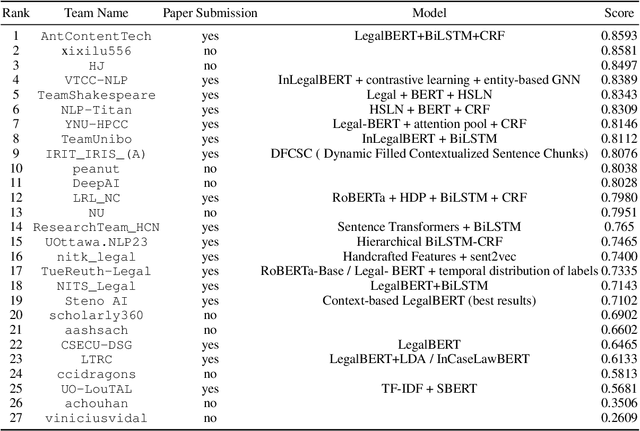
In populous countries, pending legal cases have been growing exponentially. There is a need for developing NLP-based techniques for processing and automatically understanding legal documents. To promote research in the area of Legal NLP we organized the shared task LegalEval - Understanding Legal Texts at SemEval 2023. LegalEval task has three sub-tasks: Task-A (Rhetorical Roles Labeling) is about automatically structuring legal documents into semantically coherent units, Task-B (Legal Named Entity Recognition) deals with identifying relevant entities in a legal document and Task-C (Court Judgement Prediction with Explanation) explores the possibility of automatically predicting the outcome of a legal case along with providing an explanation for the prediction. In total 26 teams (approx. 100 participants spread across the world) submitted systems paper. In each of the sub-tasks, the proposed systems outperformed the baselines; however, there is a lot of scope for improvement. This paper describes the tasks, and analyzes techniques proposed by various teams.
Generalized Product-of-Experts for Learning Multimodal Representations in Noisy Environments
Nov 07, 2022A real-world application or setting involves interaction between different modalities (e.g., video, speech, text). In order to process the multimodal information automatically and use it for an end application, Multimodal Representation Learning (MRL) has emerged as an active area of research in recent times. MRL involves learning reliable and robust representations of information from heterogeneous sources and fusing them. However, in practice, the data acquired from different sources are typically noisy. In some extreme cases, a noise of large magnitude can completely alter the semantics of the data leading to inconsistencies in the parallel multimodal data. In this paper, we propose a novel method for multimodal representation learning in a noisy environment via the generalized product of experts technique. In the proposed method, we train a separate network for each modality to assess the credibility of information coming from that modality, and subsequently, the contribution from each modality is dynamically varied while estimating the joint distribution. We evaluate our method on two challenging benchmarks from two diverse domains: multimodal 3D hand-pose estimation and multimodal surgical video segmentation. We attain state-of-the-art performance on both benchmarks. Our extensive quantitative and qualitative evaluations show the advantages of our method compared to previous approaches.