 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOSMIR: Chain Orchestrated Structured Memory for Iterative Reasoning over Long Context
Oct 06, 2025


Reasoning over very long inputs remains difficult for large language models (LLMs). Common workarounds either shrink the input via retrieval (risking missed evidence), enlarge the context window (straining selectivity), or stage multiple agents to read in pieces. In staged pipelines (e.g., Chain of Agents, CoA), free-form summaries passed between agents can discard crucial details and amplify early mistakes. We introduce COSMIR (Chain Orchestrated Structured Memory for Iterative Reasoning), a chain-style framework that replaces ad hoc messages with a structured memory. A Planner agent first turns a user query into concrete, checkable sub-questions. worker agents process chunks via a fixed micro-cycle: Extract, Infer, Refine, writing all updates to the shared memory. A Manager agent then Synthesizes the final answer directly from the memory. This preserves step-wise read-then-reason benefits while changing both the communication medium (structured memory) and the worker procedure (fixed micro-cycle), yielding higher faithfulness, better long-range aggregation, and auditability. On long-context QA from the HELMET suite, COSMIR reduces propagation-stage information loss and improves accuracy over a CoA baseline.
STACKFEED: Structured Textual Actor-Critic Knowledge Base Editing with FeedBack
Oct 14, 2024Large Language Models (LLMs) often generate incorrect or outdated information, especially in low-resource settings or when dealing with private data. To address this, Retrieval-Augmented Generation (RAG) uses external knowledge bases (KBs), but these can also suffer from inaccuracies. We introduce STACKFEED, a novel Structured Textual Actor-Critic Knowledge base editing with FEEDback approach that iteratively refines the KB based on expert feedback using a multi-actor, centralized critic reinforcement learning framework. Each document is assigned to an actor, modeled as a ReACT agent, which performs structured edits based on document-specific targeted instructions from a centralized critic. Experimental results show that STACKFEED significantly improves KB quality and RAG system performance, enhancing accuracy by up to 8% over baselines.
Generalized Product-of-Experts for Learning Multimodal Representations in Noisy Environments
Nov 07, 2022A real-world application or setting involves interaction between different modalities (e.g., video, speech, text). In order to process the multimodal information automatically and use it for an end application, Multimodal Representation Learning (MRL) has emerged as an active area of research in recent times. MRL involves learning reliable and robust representations of information from heterogeneous sources and fusing them. However, in practice, the data acquired from different sources are typically noisy. In some extreme cases, a noise of large magnitude can completely alter the semantics of the data leading to inconsistencies in the parallel multimodal data. In this paper, we propose a novel method for multimodal representation learning in a noisy environment via the generalized product of experts technique. In the proposed method, we train a separate network for each modality to assess the credibility of information coming from that modality, and subsequently, the contribution from each modality is dynamically varied while estimating the joint distribution. We evaluate our method on two challenging benchmarks from two diverse domains: multimodal 3D hand-pose estimation and multimodal surgical video segmentation. We attain state-of-the-art performance on both benchmarks. Our extensive quantitative and qualitative evaluations show the advantages of our method compared to previous approaches.
Fastron: An Online Learning-Based Model and Active Learning Strategy for Proxy Collision Detection
Sep 07, 2017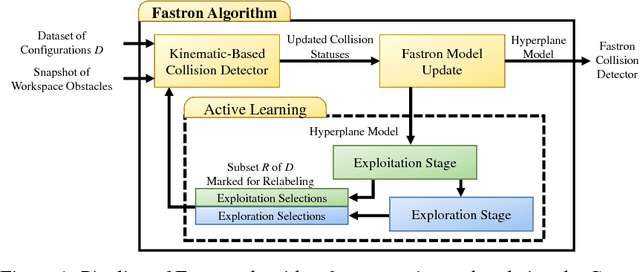
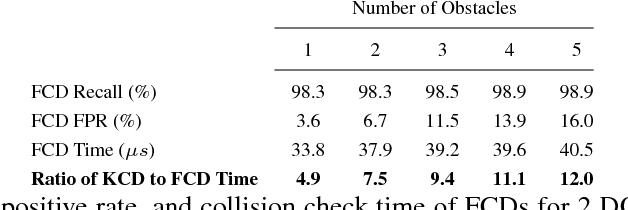
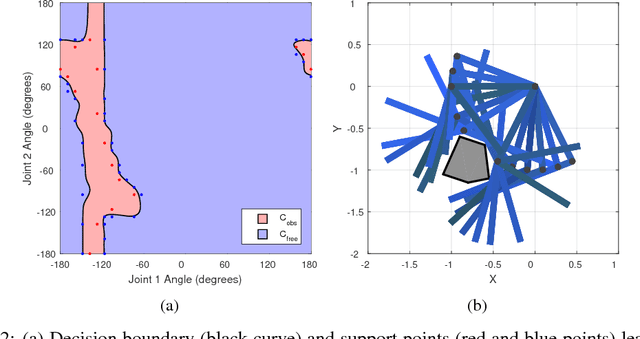
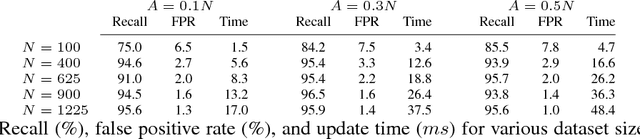
We introduce the Fastron, a configuration space (C-space) model to be used as a proxy to kinematic-based collision detection. The Fastron allows iterative updates to account for a changing environment through a combination of a novel formulation of the kernel perceptron learning algorithm and an active learning strategy. Our simulations on a 7 degree-of-freedom arm indicate that proxy collision checks may be performed at least 2 times faster than an efficient polyhedral collision checker and at least 8 times faster than an efficient high-precision collision checker. The Fastron model provides conservative collision status predictions by padding C-space obstacles, and proxy collision checking time does not scale poorly as the number of workspace obstacles increases. All results were achieved without GPU acceleration or parallel computing.