 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTACKFEED: Structured Textual Actor-Critic Knowledge Base Editing with FeedBack
Oct 14, 2024Large Language Models (LLMs) often generate incorrect or outdated information, especially in low-resource settings or when dealing with private data. To address this, Retrieval-Augmented Generation (RAG) uses external knowledge bases (KBs), but these can also suffer from inaccuracies. We introduce STACKFEED, a novel Structured Textual Actor-Critic Knowledge base editing with FEEDback approach that iteratively refines the KB based on expert feedback using a multi-actor, centralized critic reinforcement learning framework. Each document is assigned to an actor, modeled as a ReACT agent, which performs structured edits based on document-specific targeted instructions from a centralized critic. Experimental results show that STACKFEED significantly improves KB quality and RAG system performance, enhancing accuracy by up to 8% over baselines.
Exploring Interaction Patterns for Debugging: Enhancing Conversational Capabilities of AI-assistants
Feb 09, 2024



The widespread availability of Large Language Models (LLMs) within Integrated Development Environments (IDEs) has led to their speedy adoption. Conversational interactions with LLMs enable programmers to obtain natural language explanations for various software development tasks. However, LLMs often leap to action without sufficient context, giving rise to implicit assumptions and inaccurate responses. Conversations between developers and LLMs are primarily structured as question-answer pairs, where the developer is responsible for asking the the right questions and sustaining conversations across multiple turns. In this paper, we draw inspiration from interaction patterns and conversation analysis -- to design Robin, an enhanced conversational AI-assistant for debugging. Through a within-subjects user study with 12 industry professionals, we find that equipping the LLM to -- (1) leverage the insert expansion interaction pattern, (2) facilitate turn-taking, and (3) utilize debugging workflows -- leads to lowered conversation barriers, effective fault localization, and 5x improvement in bug resolution rates.
Automating Human Tutor-Style Programming Feedback: Leveraging GPT-4 Tutor Model for Hint Generation and GPT-3.5 Student Model for Hint Validation
Oct 05, 2023



Generative AI and large language models hold great promise in enhancing programming education by automatically generating individualized feedback for students. We investigate the role of generative AI models in providing human tutor-style programming hints to help students resolve errors in their buggy programs. Recent works have benchmarked state-of-the-art models for various feedback generation scenarios; however, their overall quality is still inferior to human tutors and not yet ready for real-world deployment. In this paper, we seek to push the limits of generative AI models toward providing high-quality programming hints and develop a novel technique, GPT4Hints-GPT3.5Val. As a first step, our technique leverages GPT-4 as a ``tutor'' model to generate hints -- it boosts the generative quality by using symbolic information of failing test cases and fixes in prompts. As a next step, our technique leverages GPT-3.5, a weaker model, as a ``student'' model to further validate the hint quality -- it performs an automatic quality validation by simulating the potential utility of providing this feedback. We show the efficacy of our technique via extensive evaluation using three real-world datasets of Python programs covering a variety of concepts ranging from basic algorithms to regular expressions and data analysis using pandas library.
Generative AI for Programming Education: Benchmarking ChatGPT, GPT-4, and Human Tutors
Jun 30, 2023



Generative AI and large language models hold great promise in enhancing computing education by powering next-generation educational technologies for introductory programming. Recent works have studied these models for different scenarios relevant to programming education; however, these works are limited for several reasons, as they typically consider already outdated models or only specific scenario(s). Consequently, there is a lack of a systematic study that benchmarks state-of-the-art models for a comprehensive set of programming education scenarios. In our work, we systematically evaluate two models, ChatGPT (based on GPT-3.5) and GPT-4, and compare their performance with human tutors for a variety of scenarios. We evaluate using five introductory Python programming problems and real-world buggy programs from an online platform, and assess performance using expert-based annotations. Our results show that GPT-4 drastically outperforms ChatGPT (based on GPT-3.5) and comes close to human tutors' performance for several scenarios. These results also highlight settings where GPT-4 still struggles, providing exciting future directions on developing techniques to improve the performance of these models.
GrACE: Generation using Associated Code Edits
May 24, 2023



Developers expend a significant amount of time in editing code for a variety of reasons such as bug fixing or adding new features. Designing effective methods to predict code edits has been an active yet challenging area of research due to the diversity of code edits and the difficulty of capturing the developer intent. In this work, we address these challenges by endowing pre-trained large language models (LLMs) of code with the knowledge of prior, relevant edits. The generative capability of the LLMs helps address the diversity in code changes and conditioning code generation on prior edits helps capture the latent developer intent. We evaluate two well-known LLMs, Codex and CodeT5, in zero-shot and fine-tuning settings respectively. In our experiments with two datasets, the knowledge of prior edits boosts the performance of the LLMs significantly and enables them to generate 29% and 54% more correctly edited code in top-1 suggestions relative to the current state-of-the-art symbolic and neural approaches, respectively.
Repairing Bugs in Python Assignments Using Large Language Models
Sep 29, 2022

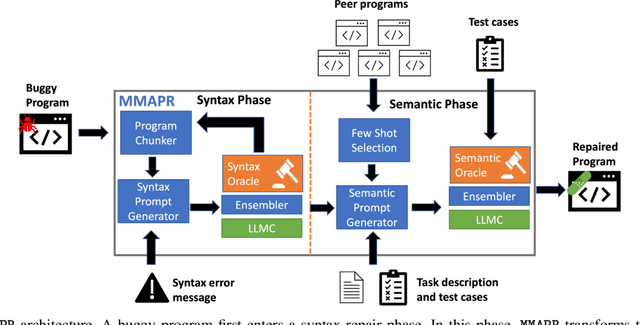

Students often make mistakes on their introductory programming assignments as part of their learning process. Unfortunately, providing custom repairs for these mistakes can require a substantial amount of time and effort from class instructors. Automated program repair (APR) techniques can be used to synthesize such fixes. Prior work has explored the use of symbolic and neural techniques for APR in the education domain. Both types of approaches require either substantial engineering efforts or large amounts of data and training. We propose to use a large language model trained on code, such as Codex, to build an APR system -- MMAPR -- for introductory Python programming assignments. Our system can fix both syntactic and semantic mistakes by combining multi-modal prompts, iterative querying, test-case-based selection of few-shots, and program chunking. We evaluate MMAPR on 286 real student programs and compare to a baseline built by combining a state-of-the-art Python syntax repair engine, BIFI, and state-of-the-art Python semantic repair engine for student assignments, Refactory. We find that MMAPR can fix more programs and produce smaller patches on average.
Overwatch: Learning Patterns in Code Edit Sequences
Jul 25, 2022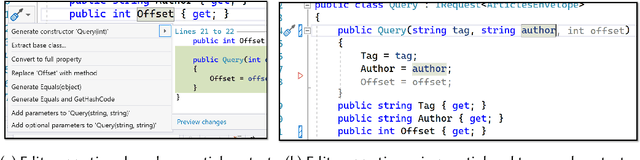
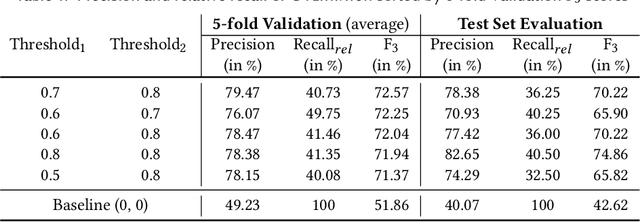


Integrated Development Environments (IDEs) provide tool support to automate many source code editing tasks. Traditionally, IDEs use only the spatial context, i.e., the location where the developer is editing, to generate candidate edit recommendations. However, spatial context alone is often not sufficient to confidently predict the developer's next edit, and thus IDEs generate many suggestions at a location. Therefore, IDEs generally do not actively offer suggestions and instead, the developer is usually required to click on a specific icon or menu and then select from a large list of potential suggestions. As a consequence, developers often miss the opportunity to use the tool support because they are not aware it exists or forget to use it. To better understand common patterns in developer behavior and produce better edit recommendations, we can additionally use the temporal context, i.e., the edits that a developer was recently performing. To enable edit recommendations based on temporal context, we present Overwatch, a novel technique for learning edit sequence patterns from traces of developers' edits performed in an IDE. Our experiments show that Overwatch has 78% precision and that Overwatch not only completed edits when developers missed the opportunity to use the IDE tool support but also predicted new edits that have no tool support in the IDE.
Synchromesh: Reliable code generation from pre-trained language models
Jan 26, 2022

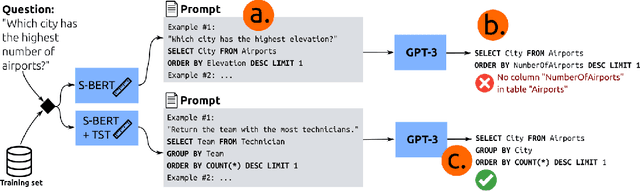
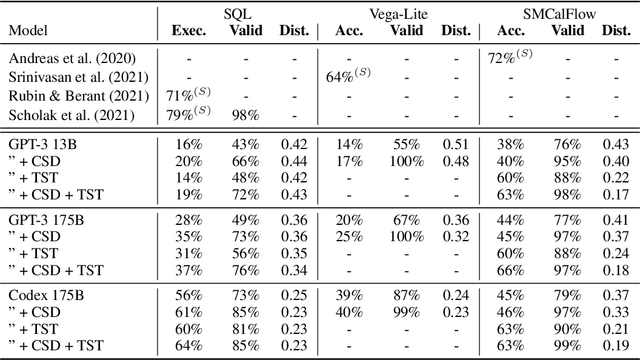
Large pre-trained language models have been used to generate code,providing a flexible interface for synthesizing programs from natural language specifications. However, they often violate syntactic and semantic rules of their output language, limiting their practical usability. In this paper, we propose Synchromesh: a framework for substantially improving the reliability of pre-trained models for code generation. Synchromesh comprises two components. First, it retrieves few-shot examples from a training bank using Target Similarity Tuning (TST), a novel method for semantic example selection. TST learns to recognize utterances that describe similar target programs despite differences in surface natural language features. Then, Synchromesh feeds the examples to a pre-trained language model and samples programs using Constrained Semantic Decoding (CSD): a general framework for constraining the output to a set of valid programs in the target language. CSD leverages constraints on partial outputs to sample complete correct programs, and needs neither re-training nor fine-tuning of the language model. We evaluate our methods by synthesizing code from natural language descriptions using GPT-3 and Codex in three real-world languages: SQL queries, Vega-Lite visualizations and SMCalFlow programs. These domains showcase rich constraints that CSD is able to enforce, including syntax, scope, typing rules, and contextual logic. We observe substantial complementary gains from CSD and TST in prediction accuracy and in effectively preventing run-time errors.
Multi-modal Program Inference: a Marriage of Pre-trainedLanguage Models and Component-based Synthesis
Sep 03, 2021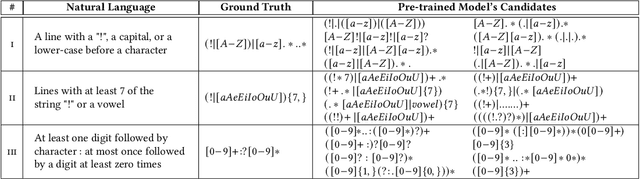
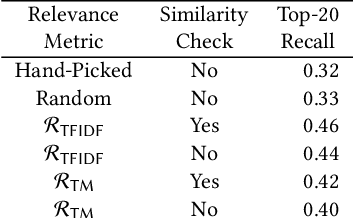


Multi-modal program synthesis refers to the task of synthesizing programs (code) from their specification given in different forms, such as a combination of natural language and examples. Examples provide a precise but incomplete specification, and natural language provides an ambiguous but more "complete" task description. Machine-learned pre-trained models (PTMs) are adept at handling ambiguous natural language, but struggle with generating syntactically and semantically precise code. Program synthesis techniques can generate correct code, often even from incomplete but precise specifications, such as examples, but they are unable to work with the ambiguity of natural languages. We present an approach that combines PTMs with component-based synthesis (CBS): PTMs are used to generate candidates programs from the natural language description of the task, which are then used to guide the CBS procedure to find the program that matches the precise examples-based specification. We use our combination approach to instantiate multi-modal synthesis systems for two programming domains: the domain of regular expressions and the domain of CSS selectors. Our evaluation demonstrates the effectiveness of our domain-agnostic approach in comparison to a state-of-the-art specialized system, and the generality of our approach in providing multi-modal program synthesis from natural language and examples in different programming domains.
Learning Syntactic Program Transformations from Examples
Aug 31, 2016
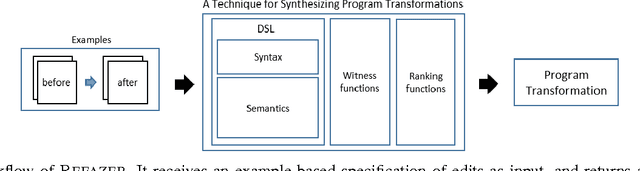
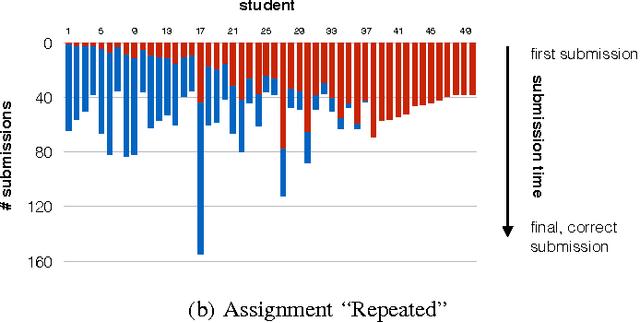
IDEs, such as Visual Studio, automate common transformations, such as Rename and Extract Method refactorings. However, extending these catalogs of transformations is complex and time-consuming. A similar phenomenon appears in intelligent tutoring systems where instructors have to write cumbersome code transformations that describe "common faults" to fix similar student submissions to programming assignments. We present REFAZER, a technique for automatically generating program transformations. REFAZER builds on the observation that code edits performed by developers can be used as examples for learning transformations. Example edits may share the same structure but involve different variables and subexpressions, which must be generalized in a transformation at the right level of abstraction. To learn transformations, REFAZER leverages state-of-the-art programming-by-example methodology using the following key components: (a) a novel domain-specific language (DSL) for describing program transformations, (b) domain-specific deductive algorithms for synthesizing transformations in the DSL, and (c) functions for ranking the synthesized transformations. We instantiate and evaluate REFAZER in two domains. First, given examples of edits used by students to fix incorrect programming assignment submissions, we learn transformations that can fix other students' submissions with similar faults. In our evaluation conducted on 4 programming tasks performed by 720 students, our technique helped to fix incorrect submissions for 87% of the students. In the second domain, we use repetitive edits applied by developers to the same project to synthesize a program transformation that applies these edits to other locations in the code. In our evaluation conducted on 59 scenarios of repetitive edits taken from 3 C# open-source projects, REFAZER learns the intended program transformation in 83% of the cases.