 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamcrafter: Immersive Editing of 3D Radiance Fields Through Flexible, Generative Inputs and Outputs
Dec 23, 2025



Authoring 3D scenes is a central task for spatial computing applications. Competing visions for lowering existing barriers are (1) focus on immersive, direct manipulation of 3D content or (2) leverage AI techniques that capture real scenes (3D Radiance Fields such as, NeRFs, 3D Gaussian Splatting) and modify them at a higher level of abstraction, at the cost of high latency. We unify the complementary strengths of these approaches and investigate how to integrate generative AI advances into real-time, immersive 3D Radiance Field editing. We introduce Dreamcrafter, a VR-based 3D scene editing system that: (1) provides a modular architecture to integrate generative AI algorithms; (2) combines different levels of control for creating objects, including natural language and direct manipulation; and (3) introduces proxy representations that support interaction during high-latency operations. We contribute empirical findings on control preferences and discuss how generative AI interfaces beyond text input enhance creativity in scene editing and world building.
Visual Prompting with Iterative Refinement for Design Critique Generation
Dec 22, 2024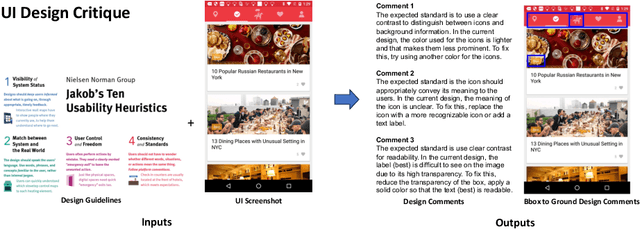

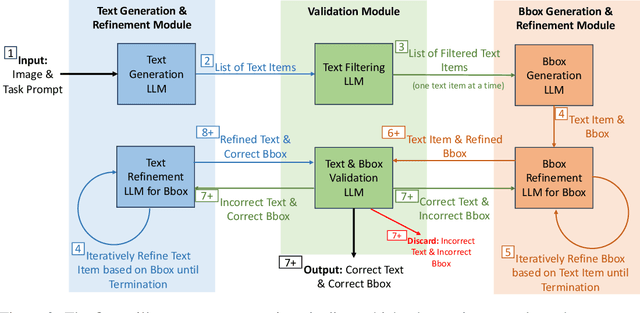
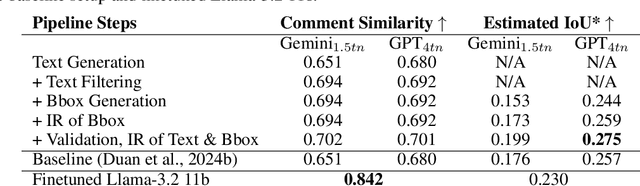
Feedback is crucial for every design process, such as user interface (UI) design, and automating design critiques can significantly improve the efficiency of the design workflow. Although existing multimodal large language models (LLMs) excel in many tasks, they often struggle with generating high-quality design critiques -- a complex task that requires producing detailed design comments that are visually grounded in a given design's image. Building on recent advancements in iterative refinement of text output and visual prompting methods, we propose an iterative visual prompting approach for UI critique that takes an input UI screenshot and design guidelines and generates a list of design comments, along with corresponding bounding boxes that map each comment to a specific region in the screenshot. The entire process is driven completely by LLMs, which iteratively refine both the text output and bounding boxes using few-shot samples tailored for each step. We evaluated our approach using Gemini-1.5-pro and GPT-4o, and found that human experts generally preferred the design critiques generated by our pipeline over those by the baseline, with the pipeline reducing the gap from human performance by 50% for one rating metric. To assess the generalizability of our approach to other multimodal tasks, we applied our pipeline to open-vocabulary object and attribute detection, and experiments showed that our method also outperformed the baseline.
UICrit: Enhancing Automated Design Evaluation with a UICritique Dataset
Jul 11, 2024Automated UI evaluation can be beneficial for the design process; for example, to compare different UI designs, or conduct automated heuristic evaluation. LLM-based UI evaluation, in particular, holds the promise of generalizability to a wide variety of UI types and evaluation tasks. However, current LLM-based techniques do not yet match the performance of human evaluators. We hypothesize that automatic evaluation can be improved by collecting a targeted UI feedback dataset and then using this dataset to enhance the performance of general-purpose LLMs. We present a targeted dataset of 3,059 design critiques and quality ratings for 983 mobile UIs, collected from seven experienced designers. We carried out an in-depth analysis to characterize the dataset's features. We then applied this dataset to achieve a 55% performance gain in LLM-generated UI feedback via various few-shot and visual prompting techniques. We also discuss future applications of this dataset, including training a reward model for generative UI techniques, and fine-tuning a tool-agnostic multi-modal LLM that automates UI evaluation.
Learning Syntactic Program Transformations from Examples
Aug 31, 2016
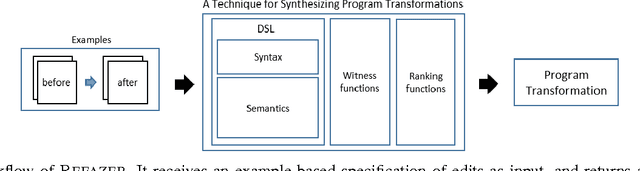
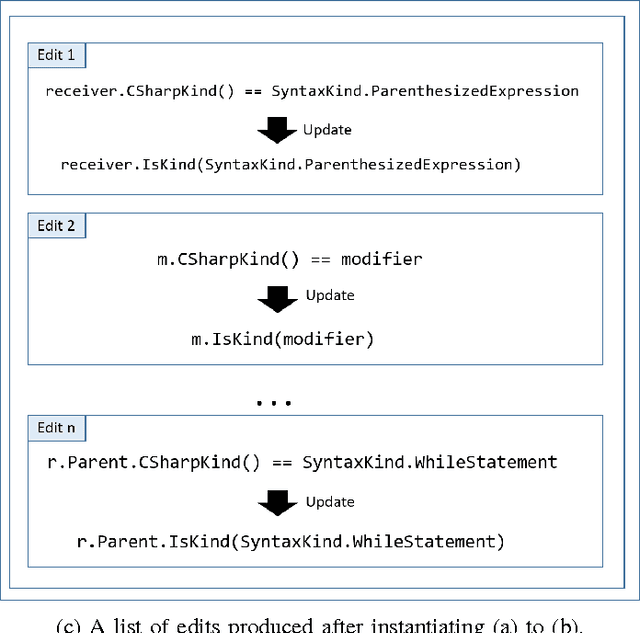
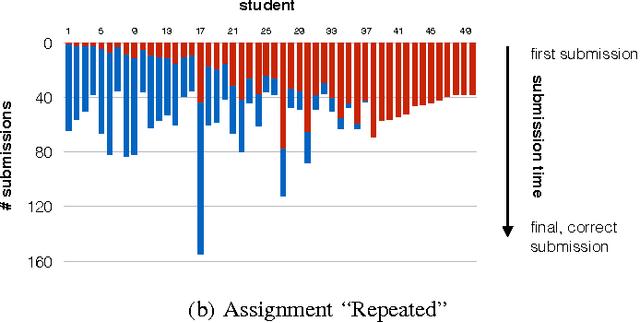
IDEs, such as Visual Studio, automate common transformations, such as Rename and Extract Method refactorings. However, extending these catalogs of transformations is complex and time-consuming. A similar phenomenon appears in intelligent tutoring systems where instructors have to write cumbersome code transformations that describe "common faults" to fix similar student submissions to programming assignments. We present REFAZER, a technique for automatically generating program transformations. REFAZER builds on the observation that code edits performed by developers can be used as examples for learning transformations. Example edits may share the same structure but involve different variables and subexpressions, which must be generalized in a transformation at the right level of abstraction. To learn transformations, REFAZER leverages state-of-the-art programming-by-example methodology using the following key components: (a) a novel domain-specific language (DSL) for describing program transformations, (b) domain-specific deductive algorithms for synthesizing transformations in the DSL, and (c) functions for ranking the synthesized transformations. We instantiate and evaluate REFAZER in two domains. First, given examples of edits used by students to fix incorrect programming assignment submissions, we learn transformations that can fix other students' submissions with similar faults. In our evaluation conducted on 4 programming tasks performed by 720 students, our technique helped to fix incorrect submissions for 87% of the students. In the second domain, we use repetitive edits applied by developers to the same project to synthesize a program transformation that applies these edits to other locations in the code. In our evaluation conducted on 59 scenarios of repetitive edits taken from 3 C# open-source projects, REFAZER learns the intended program transformation in 83% of the cases.