 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompting with Iterative Refinement for Design Critique Generation
Dec 22, 2024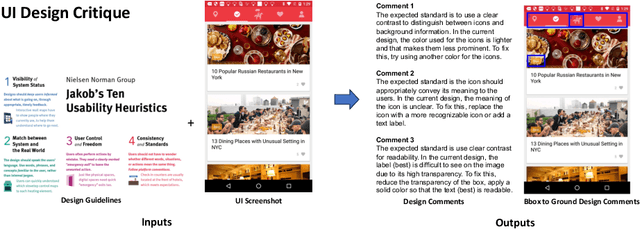

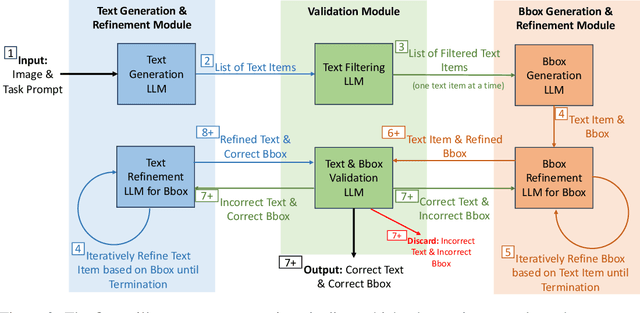
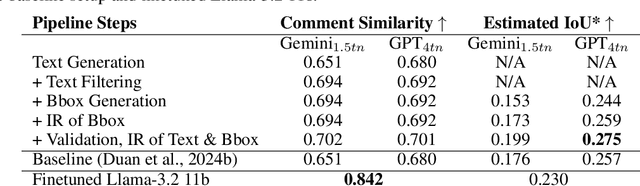
Feedback is crucial for every design process, such as user interface (UI) design, and automating design critiques can significantly improve the efficiency of the design workflow. Although existing multimodal large language models (LLMs) excel in many tasks, they often struggle with generating high-quality design critiques -- a complex task that requires producing detailed design comments that are visually grounded in a given design's image. Building on recent advancements in iterative refinement of text output and visual prompting methods, we propose an iterative visual prompting approach for UI critique that takes an input UI screenshot and design guidelines and generates a list of design comments, along with corresponding bounding boxes that map each comment to a specific region in the screenshot. The entire process is driven completely by LLMs, which iteratively refine both the text output and bounding boxes using few-shot samples tailored for each step. We evaluated our approach using Gemini-1.5-pro and GPT-4o, and found that human experts generally preferred the design critiques generated by our pipeline over those by the baseline, with the pipeline reducing the gap from human performance by 50% for one rating metric. To assess the generalizability of our approach to other multimodal tasks, we applied our pipeline to open-vocabulary object and attribute detection, and experiments showed that our method also outperformed the baseline.
UICrit: Enhancing Automated Design Evaluation with a UICritique Dataset
Jul 11, 2024Automated UI evaluation can be beneficial for the design process; for example, to compare different UI designs, or conduct automated heuristic evaluation. LLM-based UI evaluation, in particular, holds the promise of generalizability to a wide variety of UI types and evaluation tasks. However, current LLM-based techniques do not yet match the performance of human evaluators. We hypothesize that automatic evaluation can be improved by collecting a targeted UI feedback dataset and then using this dataset to enhance the performance of general-purpose LLMs. We present a targeted dataset of 3,059 design critiques and quality ratings for 983 mobile UIs, collected from seven experienced designers. We carried out an in-depth analysis to characterize the dataset's features. We then applied this dataset to achieve a 55% performance gain in LLM-generated UI feedback via various few-shot and visual prompting techniques. We also discuss future applications of this dataset, including training a reward model for generative UI techniques, and fine-tuning a tool-agnostic multi-modal LLM that automates UI evaluation.