 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Model Predictive Shielding for Provably Safe Reinforcement Learning
May 22, 2024Among approaches for provably safe reinforcement learning, Model Predictive Shielding (MPS) has proven effective at complex tasks in continuous, high-dimensional state spaces, by leveraging a backup policy to ensure safety when the learned policy attempts to take risky actions. However, while MPS can ensure safety both during and after training, it often hinders task progress due to the conservative and task-oblivious nature of backup policies. This paper introduces Dynamic Model Predictive Shielding (DMPS), which optimizes reinforcement learning objectives while maintaining provable safety. DMPS employs a local planner to dynamically select safe recovery actions that maximize both short-term progress as well as long-term rewards. Crucially, the planner and the neural policy play a synergistic role in DMPS. When planning recovery actions for ensuring safety, the planner utilizes the neural policy to estimate long-term rewards, allowing it to observe beyond its short-term planning horizon. Conversely, the neural policy under training learns from the recovery plans proposed by the planner, converging to policies that are both high-performing and safe in practice. This approach guarantees safety during and after training, with bounded recovery regret that decreases exponentially with planning horizon depth. Experimental results demonstrate that DMPS converges to policies that rarely require shield interventions after training and achieve higher rewards compared to several state-of-the-art baselines.
Program Synthesis for Robot Learning from Demonstrations
May 04, 2023



This paper presents a new synthesis-based approach for solving the Learning from Demonstration (LfD) problem in robotics. Given a set of user demonstrations, the goal of programmatic LfD is to learn a policy in a programming language that can be used to control a robot's behavior. We address this problem through a novel program synthesis algorithm that leverages two key ideas: First, to perform fast and effective generalization from user demonstrations, our synthesis algorithm views these demonstrations as strings over a finite alphabet and abstracts programs in our DSL as regular expressions over the same alphabet. This regex abstraction facilitates synthesis by helping infer useful program sketches and pruning infeasible parts of the search space. Second, to deal with the large number of object types in the environment, our method leverages a Large Language Model (LLM) to guide search. We have implemented our approach in a tool called Prolex and present the results of a comprehensive experimental evaluation on 120 benchmarks involving 40 unique tasks in three different environments. We show that, given a 120 second time limit, Prolex can find a program consistent with the demonstrations in 80% of the cases. Furthermore, for 81% of the tasks for which a solution is returned, Prolex is able to find the ground truth program with just one demonstration. To put these results in perspective, we conduct a comparison against two baselines and show that both perform much worse.
PLUNDER: Probabilistic Program Synthesis for Learning from Unlabeled and Noisy Demonstrations
Mar 02, 2023


Learning from demonstration (LfD) is a widely researched paradigm for teaching robots to perform novel tasks. LfD works particularly well with program synthesis since the resulting programmatic policy is data efficient, interpretable, and amenable to formal verification. However, existing synthesis approaches to LfD rely on precise and labeled demonstrations and are incapable of reasoning about the uncertainty inherent in human decision-making. In this paper, we propose PLUNDER, a new LfD approach that integrates a probabilistic program synthesizer in an expectation-maximization (EM) loop to overcome these limitations. PLUNDER only requires unlabeled low-level demonstrations of the intended task (e.g., remote-controlled motion trajectories), which liberates end-users from providing explicit labels and facilitates a more intuitive LfD experience. PLUNDER also generates a probabilistic policy that captures actuation errors and the uncertainties inherent in human decision making. Our experiments compare PLUNDER with state-of the-art LfD techniques and demonstrate its advantages across different robotic tasks.
Multi-modal Program Inference: a Marriage of Pre-trainedLanguage Models and Component-based Synthesis
Sep 03, 2021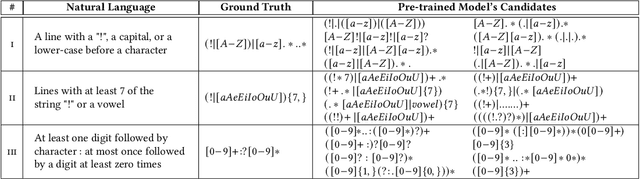


Multi-modal program synthesis refers to the task of synthesizing programs (code) from their specification given in different forms, such as a combination of natural language and examples. Examples provide a precise but incomplete specification, and natural language provides an ambiguous but more "complete" task description. Machine-learned pre-trained models (PTMs) are adept at handling ambiguous natural language, but struggle with generating syntactically and semantically precise code. Program synthesis techniques can generate correct code, often even from incomplete but precise specifications, such as examples, but they are unable to work with the ambiguity of natural languages. We present an approach that combines PTMs with component-based synthesis (CBS): PTMs are used to generate candidates programs from the natural language description of the task, which are then used to guide the CBS procedure to find the program that matches the precise examples-based specification. We use our combination approach to instantiate multi-modal synthesis systems for two programming domains: the domain of regular expressions and the domain of CSS selectors. Our evaluation demonstrates the effectiveness of our domain-agnostic approach in comparison to a state-of-the-art specialized system, and the generality of our approach in providing multi-modal program synthesis from natural language and examples in different programming domains.