 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap Between Semantic and User Preference Spaces for Multi-modal Music Representation Learning
May 29, 2025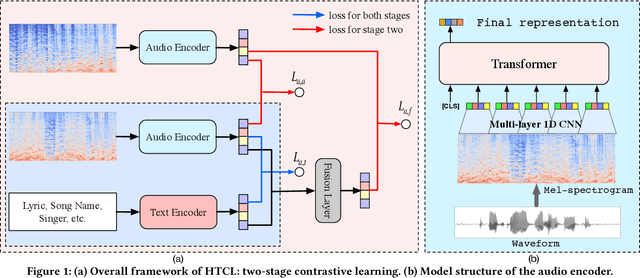
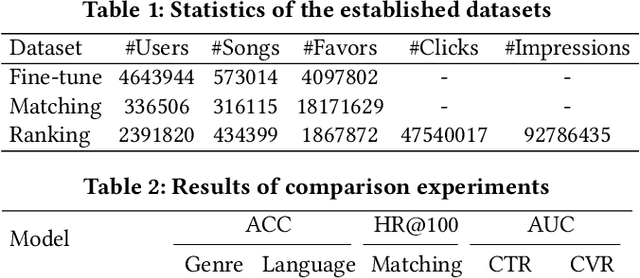
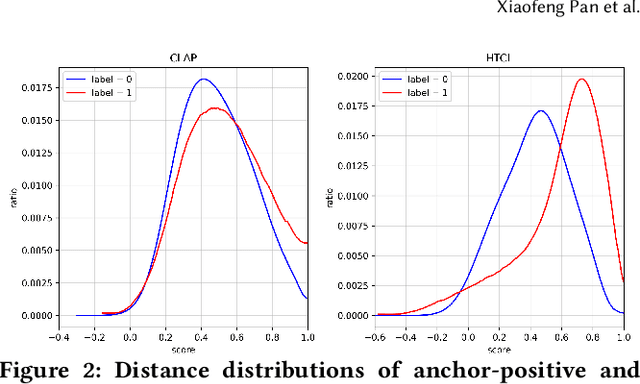
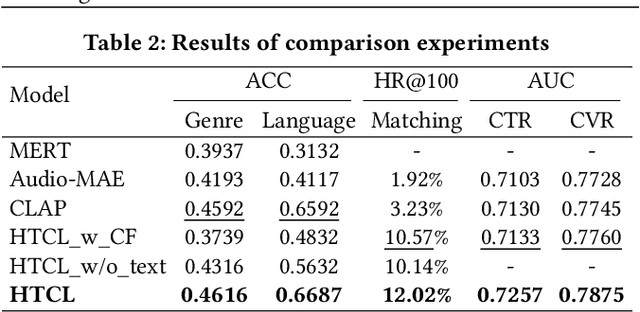
Recent works of music representation learning mainly focus on learning acoustic music representations with unlabeled audios or further attempt to acquire multi-modal music representations with scarce annotated audio-text pairs. They either ignore the language semantics or rely on labeled audio datasets that are difficult and expensive to create. Moreover, merely modeling semantic space usually fails to achieve satisfactory performance on music recommendation tasks since the user preference space is ignored. In this paper, we propose a novel Hierarchical Two-stage Contrastive Learning (HTCL) method that models similarity from the semantic perspective to the user perspective hierarchically to learn a comprehensive music representation bridging the gap between semantic and user preference spaces. We devise a scalable audio encoder and leverage a pre-trained BERT model as the text encoder to learn audio-text semantics via large-scale contrastive pre-training. Further, we explore a simple yet effective way to exploit interaction data from our online music platform to adapt the semantic space to user preference space via contrastive fine-tuning, which differs from previous works that follow the idea of collaborative filtering. As a result, we obtain a powerful audio encoder that not only distills language semantics from the text encoder but also models similarity in user preference space with the integrity of semantic space preserved. Experimental results on both music semantic and recommendation tasks confirm the effectiveness of our method.
Coeditor: Leveraging Contextual Changes for Multi-round Code Auto-editing
May 29, 2023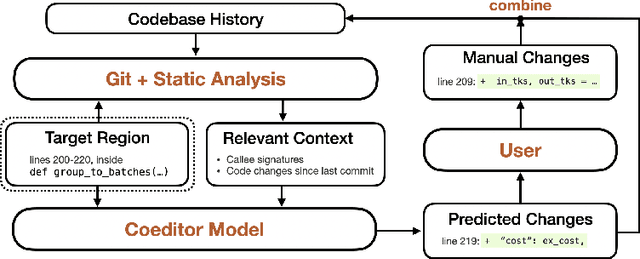
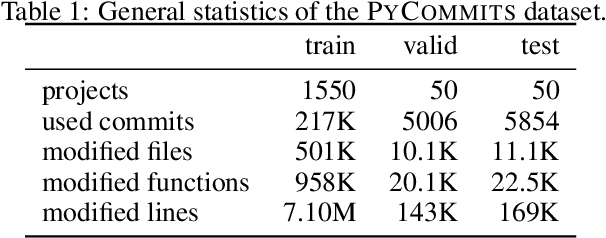
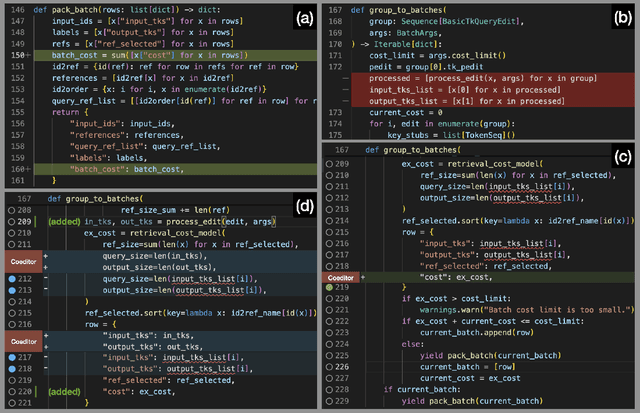

Developers often dedicate significant time to maintaining and refactoring existing code. However, most prior work on generative models for code focuses solely on creating new code, neglecting the unique requirements of editing existing code. In this work, we explore a multi-round code auto-editing setting, aiming to predict edits to a code region based on recent changes within the same codebase. Our model, Coeditor, is a fine-tuned CodeT5 model with enhancements specifically designed for code editing tasks. We encode code changes using a line diff format and employ static analysis to form large customized model contexts, ensuring appropriate information for prediction. We collect a code editing dataset from the commit histories of 1650 open-source Python projects for training and evaluation. In a simplified single-round, single-edit task, Coeditor significantly outperforms the best code completion approach -- nearly doubling its exact-match accuracy, despite using a much smaller model -- demonstrating the benefits of incorporating editing history for code completion. In a multi-round, multi-edit setting, we observe substantial gains by iteratively prompting the model with additional user edits. We open-source our code, data, and model weights to encourage future research and release a VSCode extension powered by our model for interactive usage.
TypeT5: Seq2seq Type Inference using Static Analysis
Mar 16, 2023There has been growing interest in automatically predicting missing type annotations in programs written in Python and JavaScript. While prior methods have achieved impressive accuracy when predicting the most common types, they often perform poorly on rare or complex types. In this paper, we present a new type inference method that treats type prediction as a code infilling task by leveraging CodeT5, a state-of-the-art seq2seq pre-trained language model for code. Our method uses static analysis to construct dynamic contexts for each code element whose type signature is to be predicted by the model. We also propose an iterative decoding scheme that incorporates previous type predictions in the model's input context, allowing information exchange between related code elements. Our evaluation shows that the proposed approach, TypeT5, not only achieves a higher overall accuracy (particularly on rare and complex types) but also produces more coherent results with fewer type errors -- while enabling easy user intervention.
PLUNDER: Probabilistic Program Synthesis for Learning from Unlabeled and Noisy Demonstrations
Mar 02, 2023
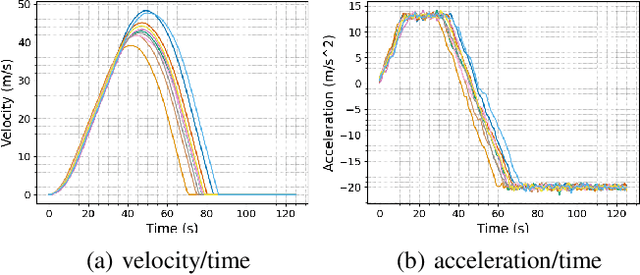


Learning from demonstration (LfD) is a widely researched paradigm for teaching robots to perform novel tasks. LfD works particularly well with program synthesis since the resulting programmatic policy is data efficient, interpretable, and amenable to formal verification. However, existing synthesis approaches to LfD rely on precise and labeled demonstrations and are incapable of reasoning about the uncertainty inherent in human decision-making. In this paper, we propose PLUNDER, a new LfD approach that integrates a probabilistic program synthesizer in an expectation-maximization (EM) loop to overcome these limitations. PLUNDER only requires unlabeled low-level demonstrations of the intended task (e.g., remote-controlled motion trajectories), which liberates end-users from providing explicit labels and facilitates a more intuitive LfD experience. PLUNDER also generates a probabilistic policy that captures actuation errors and the uncertainties inherent in human decision making. Our experiments compare PLUNDER with state-of the-art LfD techniques and demonstrate its advantages across different robotic tasks.
Visual Encoding and Debiasing for CTR Prediction
May 09, 2022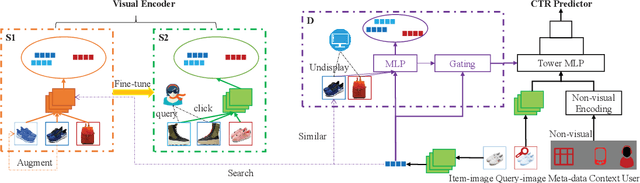
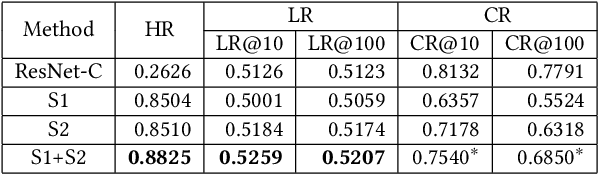

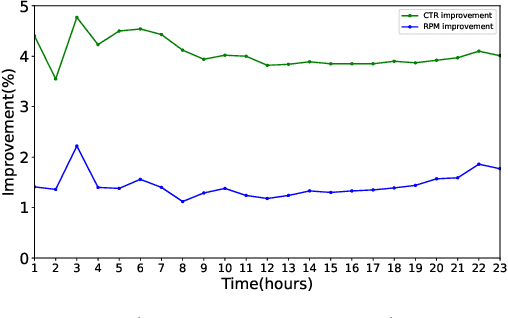
Extracting expressive visual features is crucial for accurate Click-Through-Rate (CTR) prediction in visual search advertising systems. Current commercial systems use off-the-shelf visual encoders to facilitate fast online service. However, the extracted visual features are coarse-grained and/or biased. In this paper, we present a visual encoding framework for CTR prediction to overcome these problems. The framework is based on contrastive learning which pulls positive pairs closer and pushes negative pairs apart in the visual feature space. To obtain fine-grained visual features,we present contrastive learning supervised by click through data to fine-tune the visual encoder. To reduce sample selection bias, firstly we train the visual encoder offline by leveraging both unbiased self-supervision and click supervision signals. Secondly, we incorporate a debiasing network in the online CTR predictor to adjust the visual features by contrasting high impression items with selected items with lower impressions.We deploy the framework in the visual sponsor search system at Alibaba. Offline experiments on billion-scale datasets and online experiments demonstrate that the proposed framework can make accurate and unbiased predictions.
STEADY: Simultaneous State Estimation and Dynamics Learning from Indirect Observations
Mar 02, 2022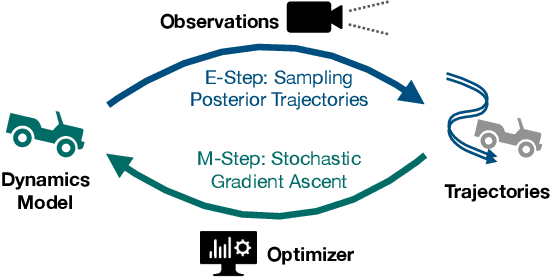
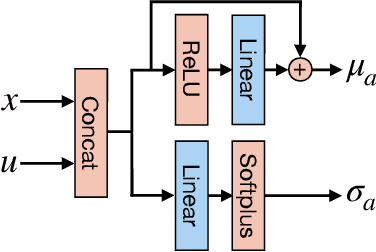
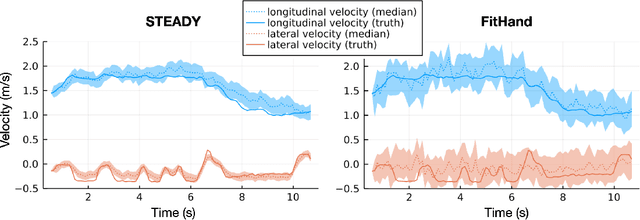
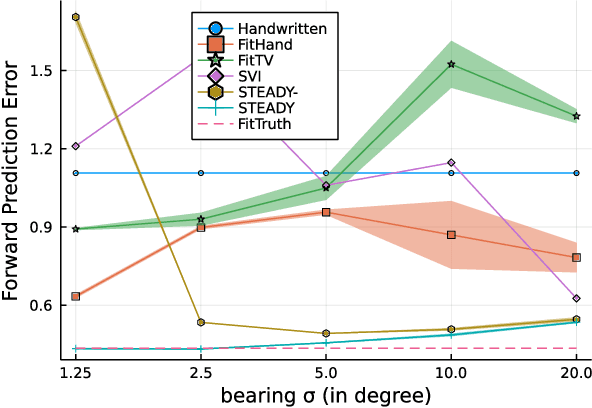
Accurate kinodynamic models play a crucial role in many robotics applications such as off-road navigation and high-speed driving. Many state-of-the-art approaches in learning stochastic kinodynamic models, however, require precise measurements of robot states as labeled input/output examples, which can be hard to obtain in outdoor settings due to limited sensor capabilities and the absence of ground truth. In this work, we propose a new technique for learning neural stochastic kinodynamic models from noisy and indirect observations by performing simultaneous state estimation and dynamics learning. The proposed technique iteratively improves the kinodynamic model in an expectation-maximization loop, where the E Step samples posterior state trajectories using particle filtering, and the M Step updates the dynamics to be more consistent with the sampled trajectories via stochastic gradient ascent. We evaluate our approach on both simulation and real-world benchmarks and compare it with several baseline techniques. Our approach not only achieves significantly higher accuracy but is also more robust to observation noise, thereby showing promise for boosting the performance of many other robotics applications.
Visual Question Rewriting for Increasing Response Rate
Jun 04, 2021
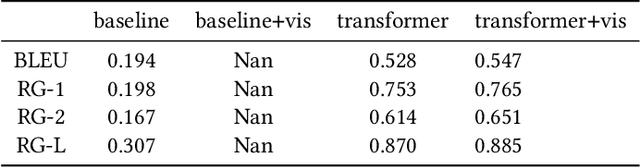
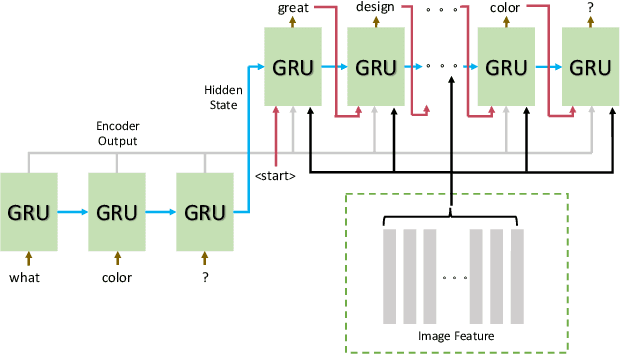
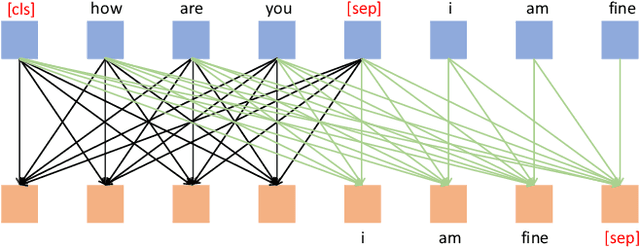
When a human asks questions online, or when a conversational virtual agent asks human questions, questions triggering emotions or with details might more likely to get responses or answers. we explore how to automatically rewrite natural language questions to improve the response rate from people. In particular, a new task of Visual Question Rewriting(VQR) task is introduced to explore how visual information can be used to improve the new questions. A data set containing around 4K bland questions, attractive questions and images triples is collected. We developed some baseline sequence to sequence models and more advanced transformer based models, which take a bland question and a related image as input and output a rewritten question that is expected to be more attractive. Offline experiments and mechanical Turk based evaluations show that it is possible to rewrite bland questions in a more detailed and attractive way to increase the response rate, and images can be helpful.
OneVision: Centralized to Distributed Controller Synthesis with Delay Compensation
Apr 14, 2021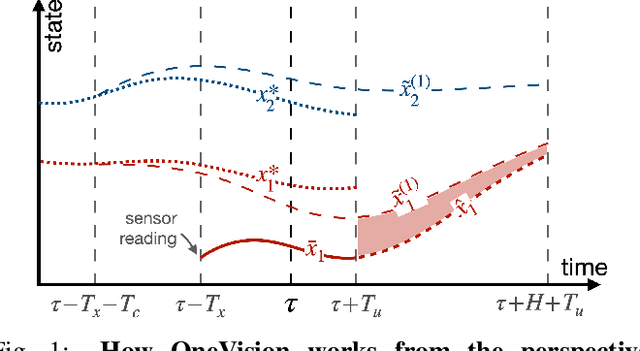
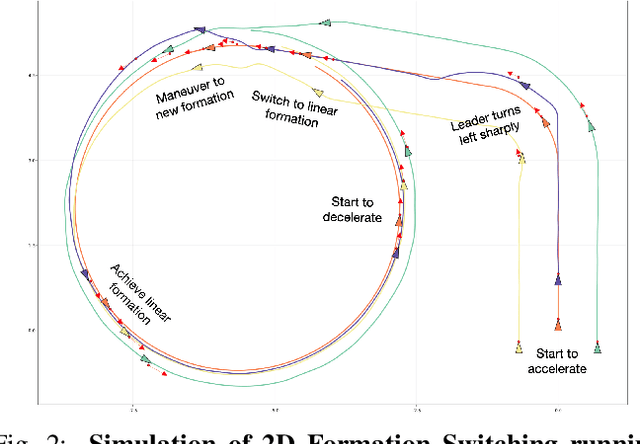
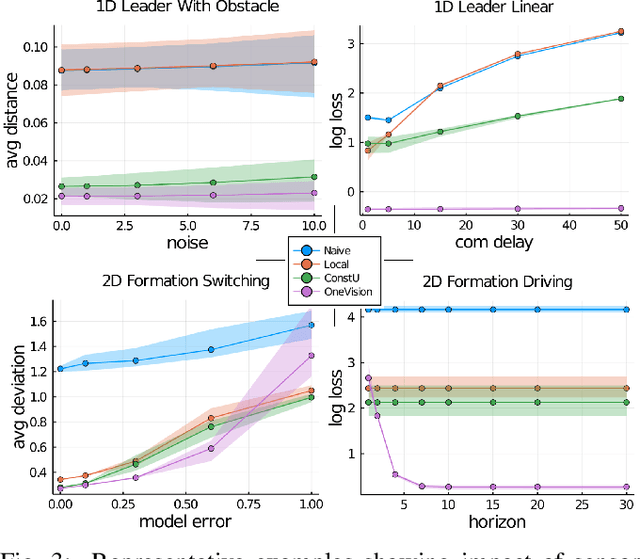
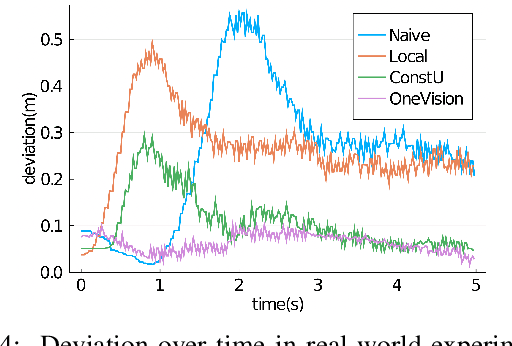
We propose a new algorithm to simplify the controller development for distributed robotic systems subject to external observations, disturbances, and communication delays. Unlike prior approaches that propose specialized solutions to handling communication latency for specific robotic applications, our algorithm uses an arbitrary centralized controller as the specification and automatically generates distributed controllers with communication management and delay compensation. We formulate our goal as nonlinear optimal control -- using a regret minimizing objective that measures how much the distributed agents behave differently from the delay-free centralized response -- and solve for optimal actions w.r.t. local estimations of this objective using gradient-based optimization. We analyze our proposed algorithm's behavior under a linear time-invariant special case and prove that the closed-loop dynamics satisfy a form of input-to-state stability w.r.t. unexpected disturbances and observations. Our experimental results on both simulated and real-world robotic tasks demonstrate the practical usefulness of our approach and show significant improvement over several baseline approaches.
LambdaNet: Probabilistic Type Inference using Graph Neural Networks
Apr 29, 2020



As gradual typing becomes increasingly popular in languages like Python and TypeScript, there is a growing need to infer type annotations automatically. While type annotations help with tasks like code completion and static error catching, these annotations cannot be fully determined by compilers and are tedious to annotate by hand. This paper proposes a probabilistic type inference scheme for TypeScript based on a graph neural network. Our approach first uses lightweight source code analysis to generate a program abstraction called a type dependency graph, which links type variables with logical constraints as well as name and usage information. Given this program abstraction, we then use a graph neural network to propagate information between related type variables and eventually make type predictions. Our neural architecture can predict both standard types, like number or string, as well as user-defined types that have not been encountered during training. Our experimental results show that our approach outperforms prior work in this space by $14\%$ (absolute) on library types, while having the ability to make type predictions that are out of scope for existing techniques.