 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap Between Semantic and User Preference Spaces for Multi-modal Music Representation Learning
May 29, 2025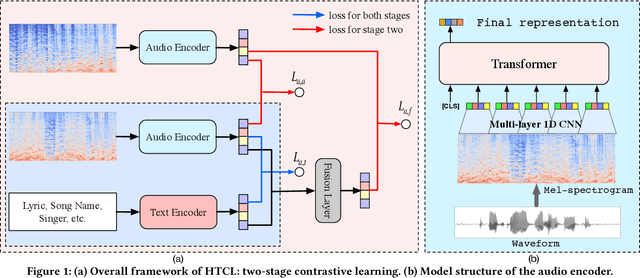
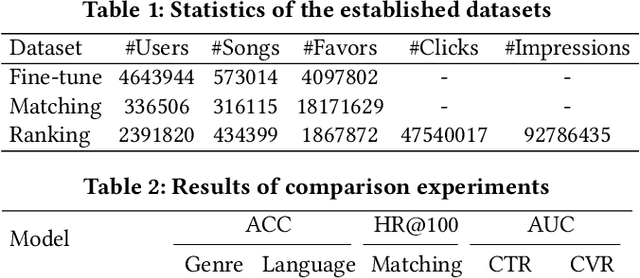
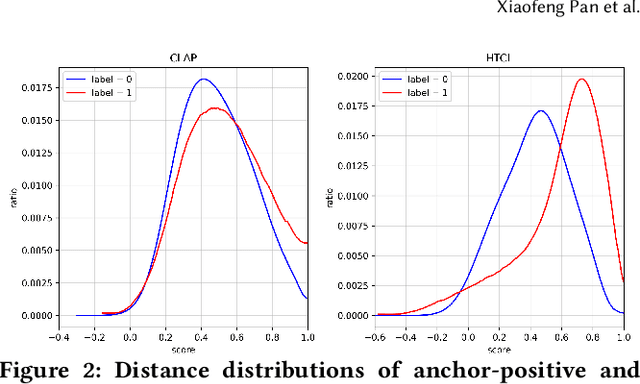
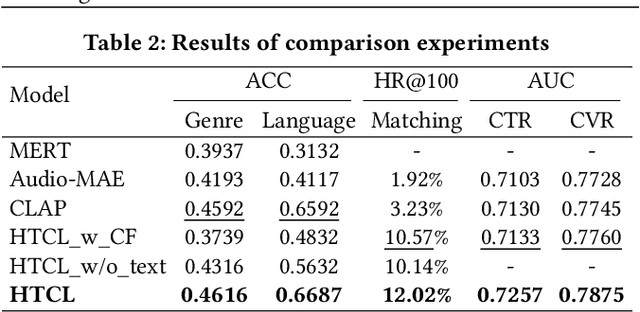
Recent works of music representation learning mainly focus on learning acoustic music representations with unlabeled audios or further attempt to acquire multi-modal music representations with scarce annotated audio-text pairs. They either ignore the language semantics or rely on labeled audio datasets that are difficult and expensive to create. Moreover, merely modeling semantic space usually fails to achieve satisfactory performance on music recommendation tasks since the user preference space is ignored. In this paper, we propose a novel Hierarchical Two-stage Contrastive Learning (HTCL) method that models similarity from the semantic perspective to the user perspective hierarchically to learn a comprehensive music representation bridging the gap between semantic and user preference spaces. We devise a scalable audio encoder and leverage a pre-trained BERT model as the text encoder to learn audio-text semantics via large-scale contrastive pre-training. Further, we explore a simple yet effective way to exploit interaction data from our online music platform to adapt the semantic space to user preference space via contrastive fine-tuning, which differs from previous works that follow the idea of collaborative filtering. As a result, we obtain a powerful audio encoder that not only distills language semantics from the text encoder but also models similarity in user preference space with the integrity of semantic space preserved. Experimental results on both music semantic and recommendation tasks confirm the effectiveness of our method.
Improving Emotional Expression and Cohesion in Image-Based Playlist Description and Music Topics: A Continuous Parameterization Approach
Oct 12, 2023Text generation in image-based platforms, particularly for music-related content, requires precise control over text styles and the incorporation of emotional expression. However, existing approaches often need help to control the proportion of external factors in generated text and rely on discrete inputs, lacking continuous control conditions for desired text generation. This study proposes Continuous Parameterization for Controlled Text Generation (CPCTG) to overcome these limitations. Our approach leverages a Language Model (LM) as a style learner, integrating Semantic Cohesion (SC) and Emotional Expression Proportion (EEP) considerations. By enhancing the reward method and manipulating the CPCTG level, our experiments on playlist description and music topic generation tasks demonstrate significant improvements in ROUGE scores, indicating enhanced relevance and coherence in the generated text.