 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap Between Semantic and User Preference Spaces for Multi-modal Music Representation Learning
May 29, 2025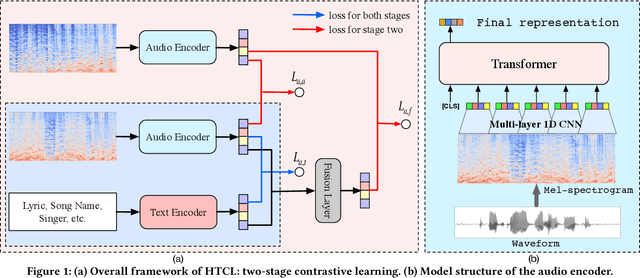
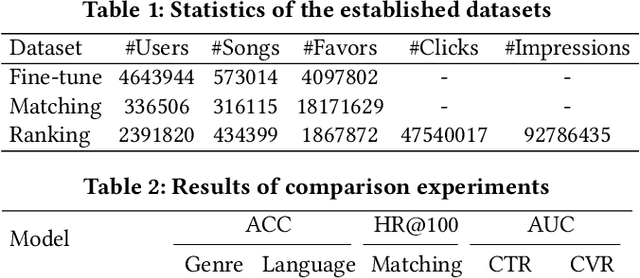
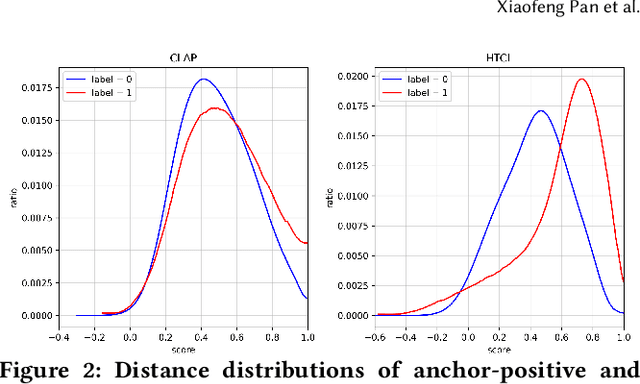
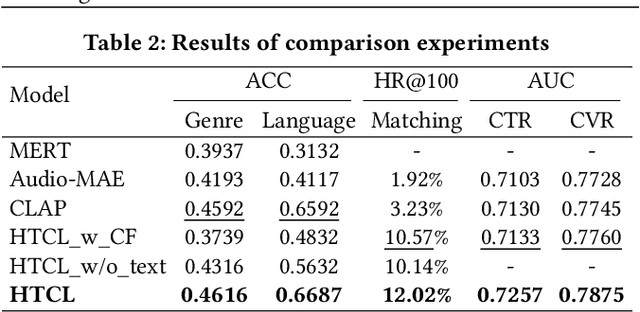
Recent works of music representation learning mainly focus on learning acoustic music representations with unlabeled audios or further attempt to acquire multi-modal music representations with scarce annotated audio-text pairs. They either ignore the language semantics or rely on labeled audio datasets that are difficult and expensive to create. Moreover, merely modeling semantic space usually fails to achieve satisfactory performance on music recommendation tasks since the user preference space is ignored. In this paper, we propose a novel Hierarchical Two-stage Contrastive Learning (HTCL) method that models similarity from the semantic perspective to the user perspective hierarchically to learn a comprehensive music representation bridging the gap between semantic and user preference spaces. We devise a scalable audio encoder and leverage a pre-trained BERT model as the text encoder to learn audio-text semantics via large-scale contrastive pre-training. Further, we explore a simple yet effective way to exploit interaction data from our online music platform to adapt the semantic space to user preference space via contrastive fine-tuning, which differs from previous works that follow the idea of collaborative filtering. As a result, we obtain a powerful audio encoder that not only distills language semantics from the text encoder but also models similarity in user preference space with the integrity of semantic space preserved. Experimental results on both music semantic and recommendation tasks confirm the effectiveness of our method.
DGC-vector: A new speaker embedding for zero-shot voice conversion
Mar 18, 2022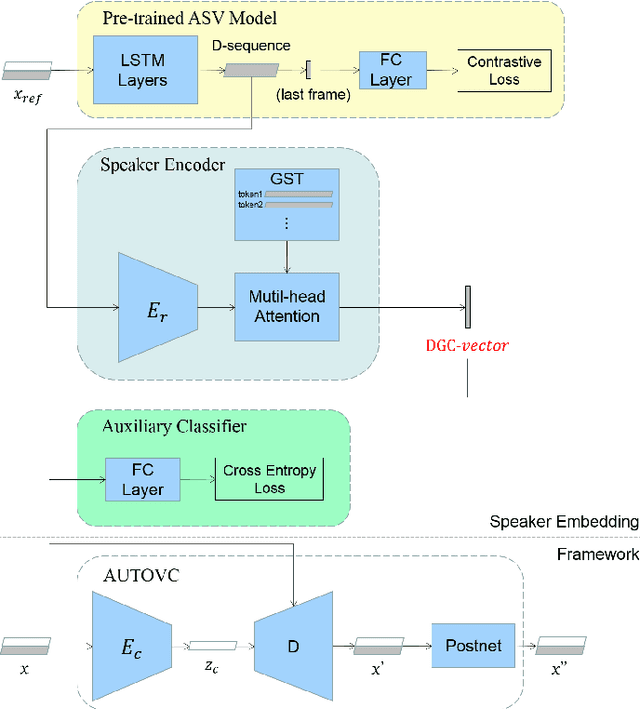
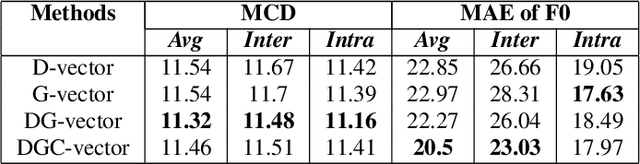
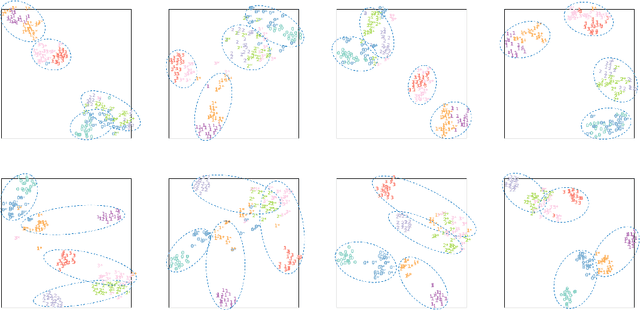
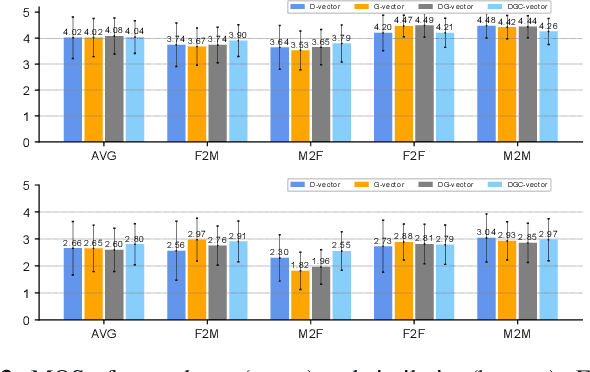
Recently, more and more zero-shot voice conversion algorithms have been proposed. As a fundamental part of zero-shot voice conversion, speaker embeddings are the key to improving the converted speech's speaker similarity. In this paper, we study the impact of speaker embeddings on zero-shot voice conversion performance. To better represent the characteristics of the target speaker and improve the speaker similarity in zero-shot voice conversion, we propose a novel speaker representation method in this paper. Our method combines the advantages of D-vector, global style token (GST) based speaker representation and auxiliary supervision. Objective and subjective evaluations show that the proposed method achieves a decent performance on zero-shot voice conversion and significantly improves speaker similarity over D-vector and GST-based speaker embedding.
Improve few-shot voice cloning using multi-modal learning
Mar 18, 2022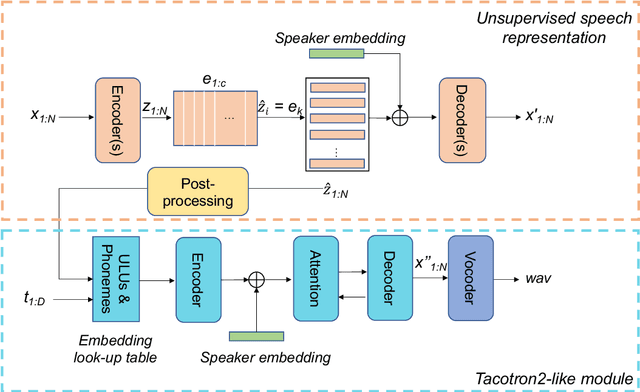
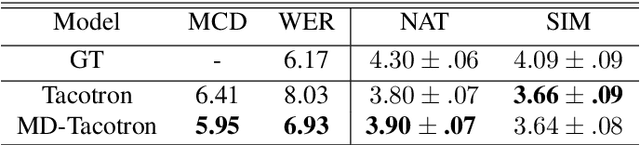
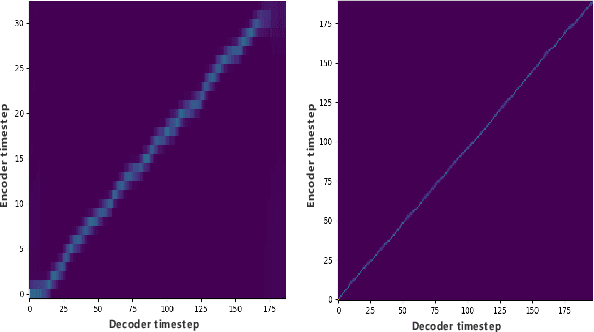

Recently, few-shot voice cloning has achieved a significant improvement. However, most models for few-shot voice cloning are single-modal, and multi-modal few-shot voice cloning has been understudied. In this paper, we propose to use multi-modal learning to improve the few-shot voice cloning performance. Inspired by the recent works on unsupervised speech representation, the proposed multi-modal system is built by extending Tacotron2 with an unsupervised speech representation module. We evaluate our proposed system in two few-shot voice cloning scenarios, namely few-shot text-to-speech(TTS) and voice conversion(VC). Experimental results demonstrate that the proposed multi-modal learning can significantly improve the few-shot voice cloning performance over their counterpart single-modal systems.
Revisiting IPA-based Cross-lingual Text-to-speech
Oct 18, 2021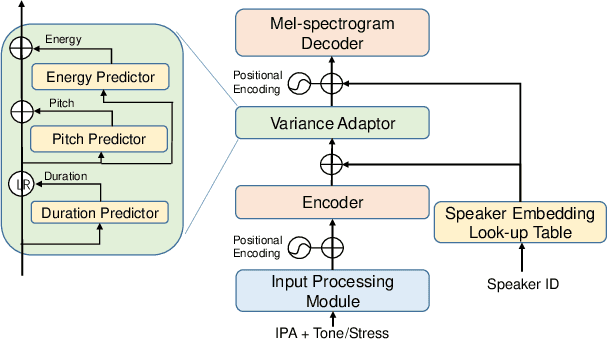
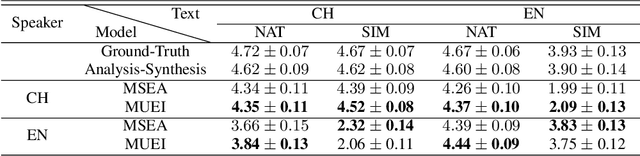
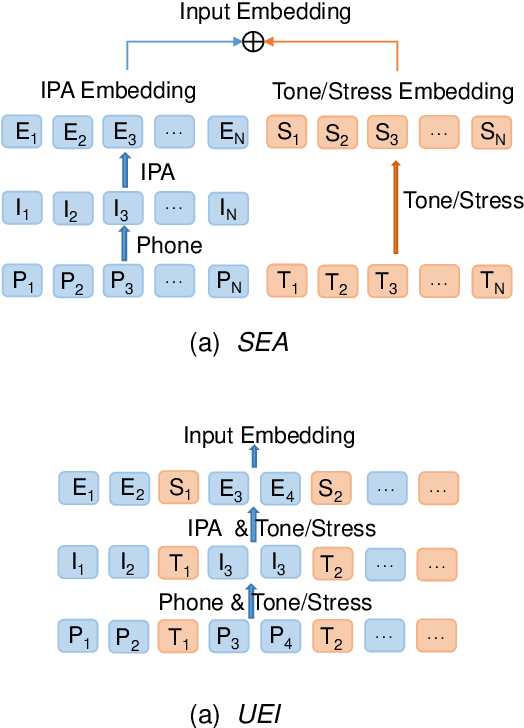
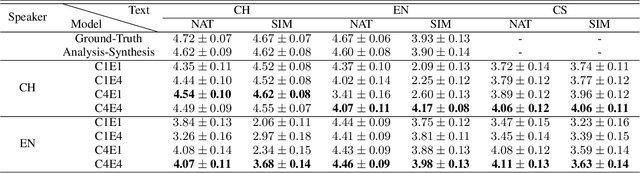
International Phonetic Alphabet (IPA) has been widely used in cross-lingual text-to-speech (TTS) to achieve cross-lingual voice cloning (CL VC). However, IPA itself has been understudied in cross-lingual TTS. In this paper, we report some empirical findings of building a cross-lingual TTS model using IPA as inputs. Experiments show that the way to process the IPA and suprasegmental sequence has a negligible impact on the CL VC performance. Furthermore, we find that using a dataset including one speaker per language to build an IPA-based TTS system would fail CL VC since the language-unique IPA and tone/stress symbols could leak the speaker information. In addition, we experiment with different combinations of speakers in the training dataset to further investigate the effect of the number of speakers on the CL VC performance.
Improve Cross-lingual Voice Cloning Using Low-quality Code-switched Data
Oct 14, 2021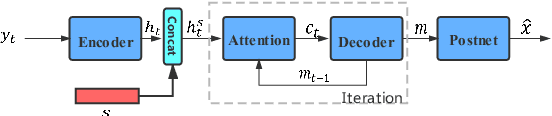
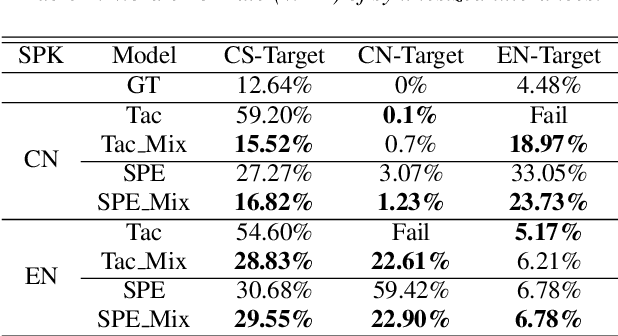
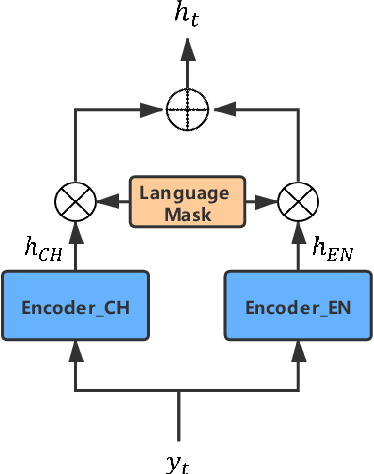
Recently, sequence-to-sequence (seq-to-seq) models have been successfully applied in text-to-speech (TTS) to synthesize speech for single-language text. To synthesize speech for multiple languages usually requires multi-lingual speech from the target speaker. However, it is both laborious and expensive to collect high-quality multi-lingual TTS data for the target speakers. In this paper, we proposed to use low-quality code-switched found data from the non-target speakers to achieve cross-lingual voice cloning for the target speakers. Experiments show that our proposed method can generate high-quality code-switched speech in the target voices in terms of both naturalness and speaker consistency. More importantly, we find that our method can achieve a comparable result to the state-of-the-art (SOTA) performance in cross-lingual voice cloning.
Exploring Timbre Disentanglement in Non-Autoregressive Cross-Lingual Text-to-Speech
Oct 14, 2021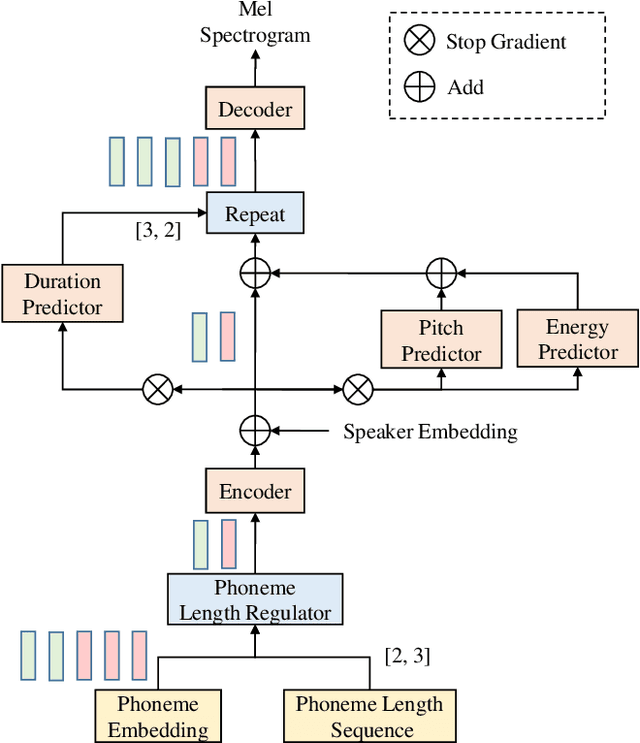
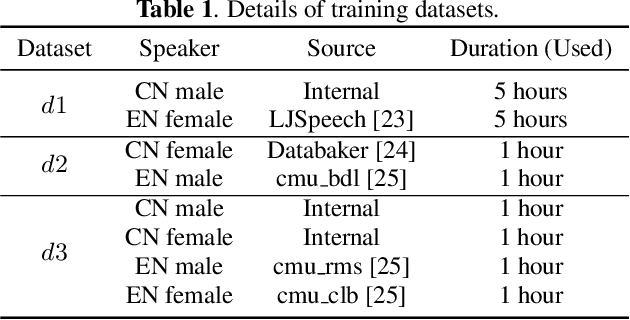

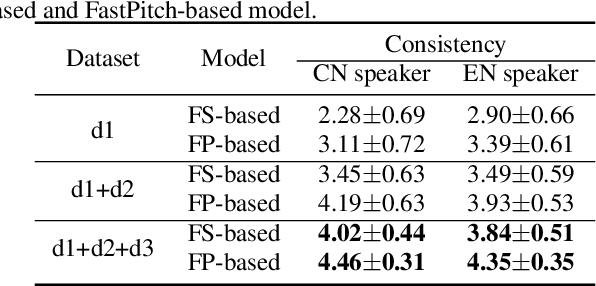
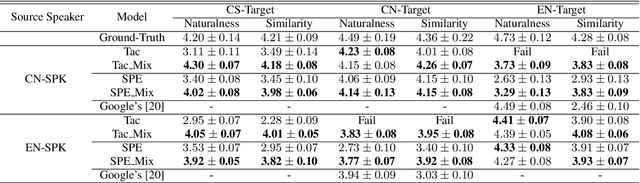
In this paper, we present a FastPitch-based non-autoregressive cross-lingual Text-to-Speech (TTS) model built with language independent input representation and monolingual force aligners. We propose a phoneme length regulator that solves the length mismatch problem between language-independent phonemes and monolingual alignment results. Our experiments show that (1) an increasing number of training speakers encourages non-autoregressive cross-lingual TTS model to disentangle speaker and language representations, and (2) variance adaptors of FastPitch model can help disentangle speaker identity from learned representations in cross-lingual TTS. The subjective evaluation shows that our proposed model is able to achieve decent speaker consistency and similarity. We further improve the naturalness of Mandarin-dominated mixed-lingual utterances by utilizing the controllability of our proposed model.
Improving Interpretability of Word Embeddings by Generating Definition and Usage
Dec 12, 2019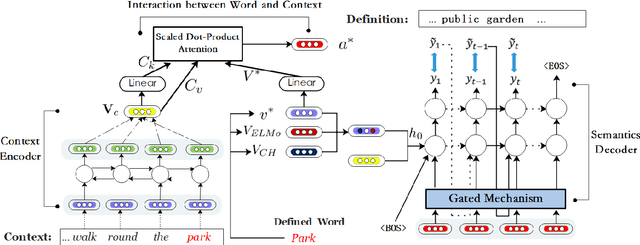
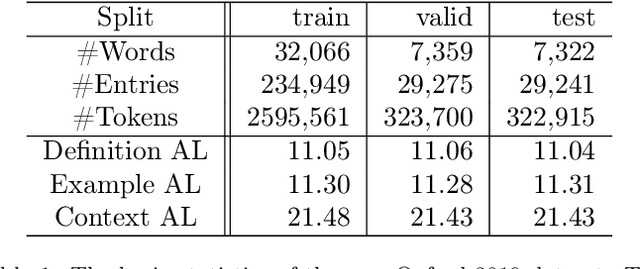
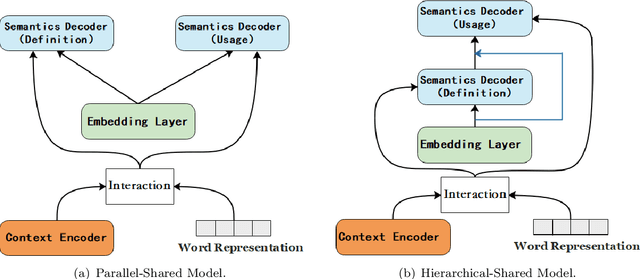
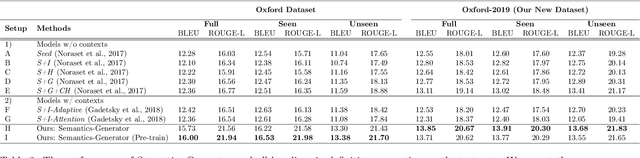
Word Embeddings, which encode semantic and syntactic features, have achieved success in many natural language processing tasks recently. However, the lexical semantics captured by these embeddings are difficult to interpret due to the dense vector representations. In order to improve the interpretability of word vectors, we explore definition modeling task and propose a novel framework (Semantics-Generator) to generate more reasonable and understandable context-dependent definitions. Moreover, we introduce usage modeling and study whether it is possible to utilize distributed representations to generate example sentences of words. These ways of semantics generation are a more direct and explicit expression of embedding's semantics. Two multi-task learning methods are used to combine usage modeling and definition modeling. To verify our approach, we construct Oxford-2019 dataset, where each entry contains word, context, example sentence and corresponding definition. Experimental results show that Semantics-Generator achieves the state-of-the-art result in definition modeling and the multi-task learning methods are helpful for two tasks to improve the performance.
RawNet: Fast End-to-End Neural Vocoder
Apr 10, 2019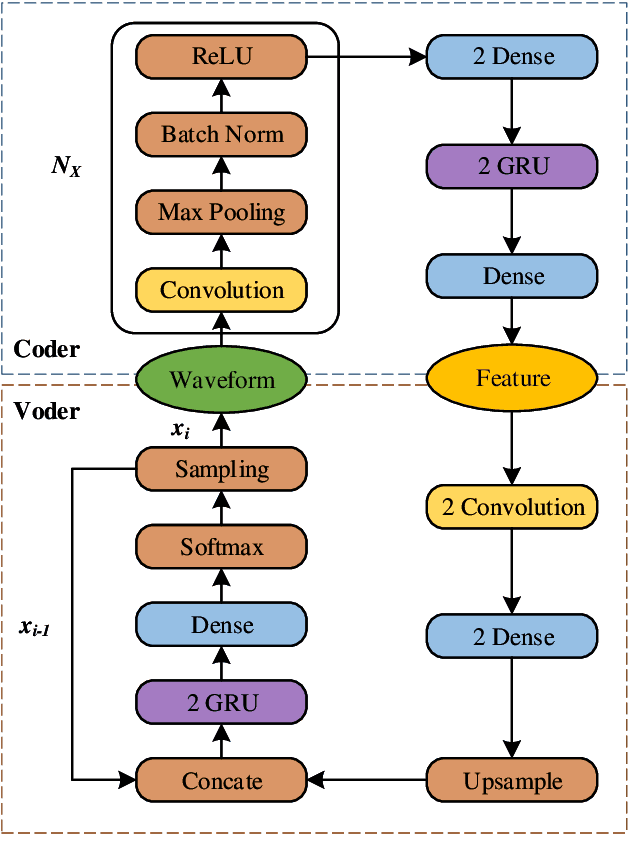
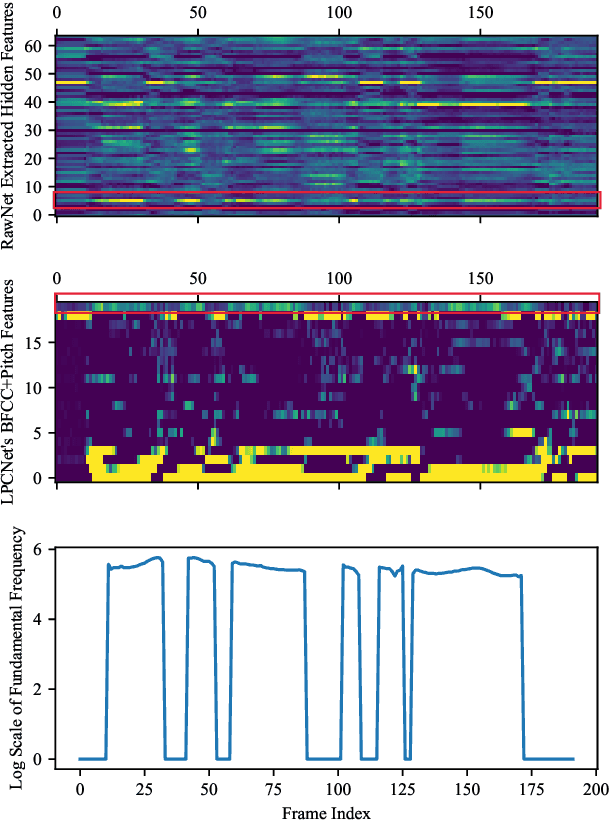
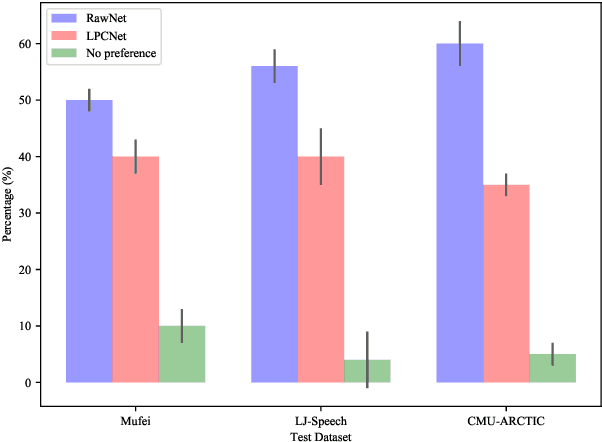

Neural networks based vocoders have recently demonstrated the powerful ability to synthesize high quality speech. These models usually generate samples by conditioning on some spectrum features, such as Mel-spectrum. However, these features are extracted by using speech analysis module including some processing based on the human knowledge. In this work, we proposed RawNet, a truly end-to-end neural vocoder, which use a coder network to learn the higher representation of signal, and an autoregressive voder network to generate speech sample by sample. The coder and voder together act like an auto-encoder network, and could be jointly trained directly on raw waveform without any human-designed features. The experiments on the Copy-Synthesis tasks show that RawNet can achieve the comparative synthesized speech quality with LPCNet, with a smaller model architecture and faster speech generation at the inference step.