 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual embedding and model weighting by fusing domain knowledge on Biomedical Question Answering
Jun 26, 2022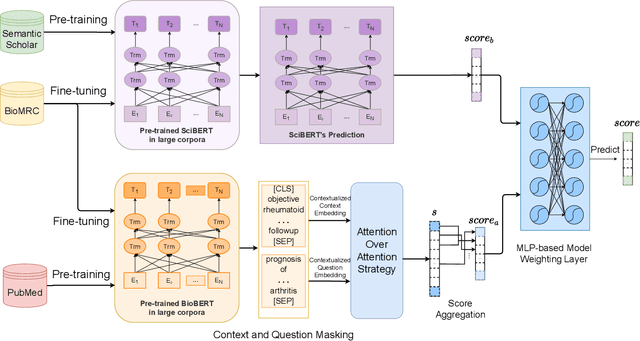
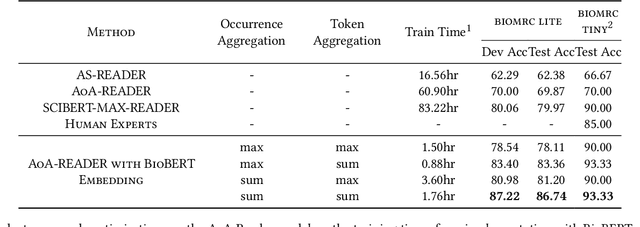

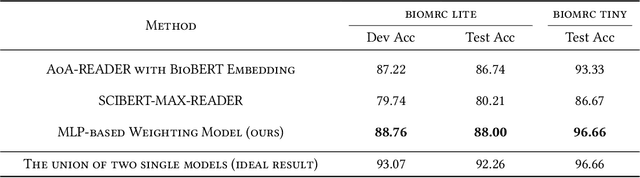
Biomedical Question Answering aims to obtain an answer to the given question from the biomedical domain. Due to its high requirement of biomedical domain knowledge, it is difficult for the model to learn domain knowledge from limited training data. We propose a contextual embedding method that combines open-domain QA model \aoa and \biobert model pre-trained on biomedical domain data. We adopt unsupervised pre-training on large biomedical corpus and supervised fine-tuning on biomedical question answering dataset. Additionally, we adopt an MLP-based model weighting layer to automatically exploit the advantages of two models to provide the correct answer. The public dataset \biomrc constructed from PubMed corpus is used to evaluate our method. Experimental results show that our model outperforms state-of-the-art system by a large margin.
Improving Interpretability of Word Embeddings by Generating Definition and Usage
Dec 12, 2019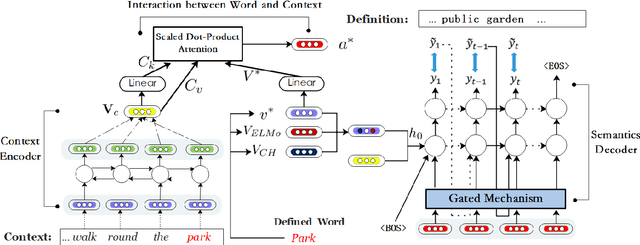
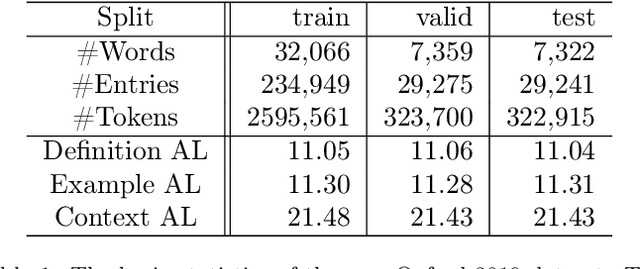
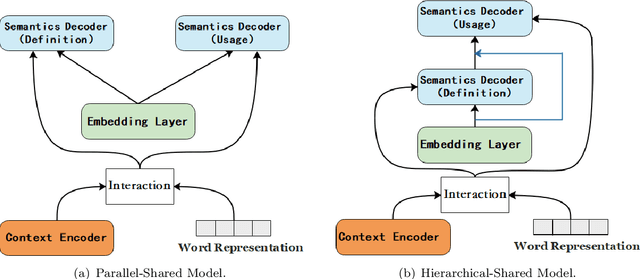
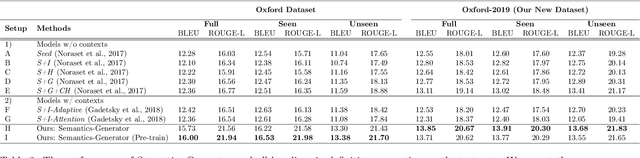
Word Embeddings, which encode semantic and syntactic features, have achieved success in many natural language processing tasks recently. However, the lexical semantics captured by these embeddings are difficult to interpret due to the dense vector representations. In order to improve the interpretability of word vectors, we explore definition modeling task and propose a novel framework (Semantics-Generator) to generate more reasonable and understandable context-dependent definitions. Moreover, we introduce usage modeling and study whether it is possible to utilize distributed representations to generate example sentences of words. These ways of semantics generation are a more direct and explicit expression of embedding's semantics. Two multi-task learning methods are used to combine usage modeling and definition modeling. To verify our approach, we construct Oxford-2019 dataset, where each entry contains word, context, example sentence and corresponding definition. Experimental results show that Semantics-Generator achieves the state-of-the-art result in definition modeling and the multi-task learning methods are helpful for two tasks to improve the performance.
Controllable Data Synthesis Method for Grammatical Error Correction
Oct 02, 2019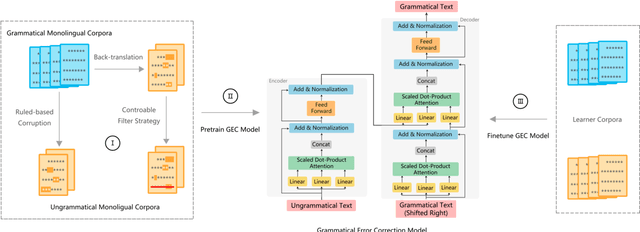


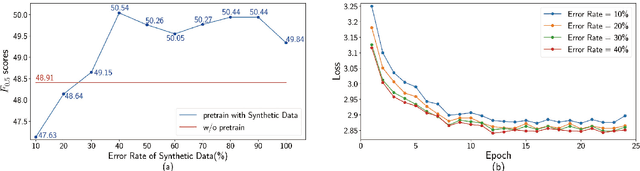
Due to the lack of parallel data in current Grammatical Error Correction (GEC) task, models based on Sequence to Sequence framework cannot be adequately trained to obtain higher performance. We propose two data synthesis methods which can control the error rate and the ratio of error types on synthetic data. The first approach is to corrupt each word in the monolingual corpus with a fixed probability, including replacement, insertion and deletion. Another approach is to train error generation models and further filtering the decoding results of the models. The experiments on different synthetic data show that the error rate is 40% and the ratio of error types is the same can improve the model performance better. Finally, we synthesize about 100 million data and achieve comparable performance as the state of the art, which uses twice as much data as we use.