 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Mar 12, 2025Diffusion language models offer unique benefits over autoregressive models due to their potential for parallelized generation and controllability, yet they lag in likelihood modeling and are limited to fixed-length generation. In this work, we introduce a class of block diffusion language models that interpolate between discrete denoising diffusion and autoregressive models. Block diffusion overcomes key limitations of both approaches by supporting flexible-length generation and improving inference efficiency with KV caching and parallel token sampling. We propose a recipe for building effective block diffusion models that includes an efficient training algorithm, estimators of gradient variance, and data-driven noise schedules to minimize the variance. Block diffusion sets a new state-of-the-art performance among diffusion models on language modeling benchmarks and enables generation of arbitrary-length sequences. We provide the code, along with the model weights and blog post on the project page: https://m-arriola.com/bd3lms/
Eyes on the Streets: Leveraging Street-Level Imaging to Model Urban Crime Dynamics
Apr 15, 2024This study addresses the challenge of urban safety in New York City by examining the relationship between the built environment and crime rates using machine learning and a comprehensive dataset of street view images. We aim to identify how urban landscapes correlate with crime statistics, focusing on the characteristics of street views and their association with crime rates. The findings offer insights for urban planning and crime prevention, highlighting the potential of environmental design in enhancing public safety.
Contextual embedding and model weighting by fusing domain knowledge on Biomedical Question Answering
Jun 26, 2022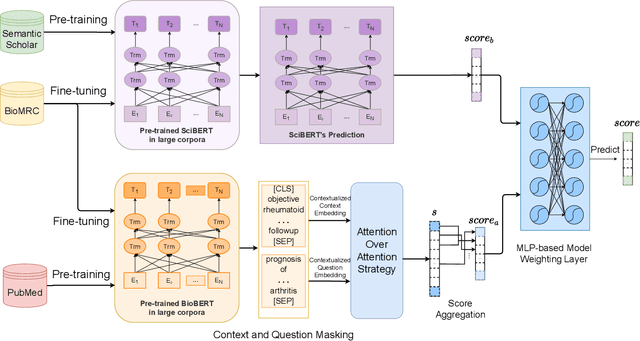
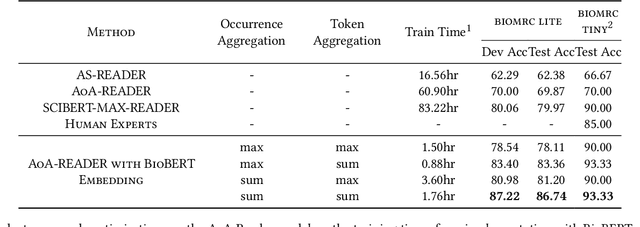

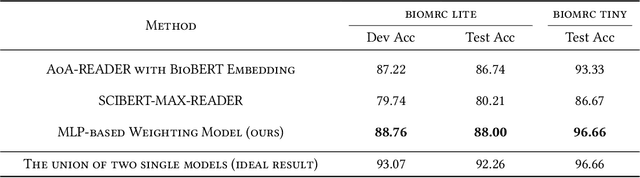
Biomedical Question Answering aims to obtain an answer to the given question from the biomedical domain. Due to its high requirement of biomedical domain knowledge, it is difficult for the model to learn domain knowledge from limited training data. We propose a contextual embedding method that combines open-domain QA model \aoa and \biobert model pre-trained on biomedical domain data. We adopt unsupervised pre-training on large biomedical corpus and supervised fine-tuning on biomedical question answering dataset. Additionally, we adopt an MLP-based model weighting layer to automatically exploit the advantages of two models to provide the correct answer. The public dataset \biomrc constructed from PubMed corpus is used to evaluate our method. Experimental results show that our model outperforms state-of-the-art system by a large margin.