 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORESTLLM: Large Language Models Make Random Forest Great on Few-shot Tabular Learning
Jan 16, 2026Tabular data high-stakes critical decision-making in domains such as finance, healthcare, and scientific discovery. Yet, learning effectively from tabular data in few-shot settings, where labeled examples are scarce, remains a fundamental challenge. Traditional tree-based methods often falter in these regimes due to their reliance on statistical purity metrics, which become unstable and prone to overfitting with limited supervision. At the same time, direct applications of large language models (LLMs) often overlook its inherent structure, leading to suboptimal performance. To overcome these limitations, we propose FORESTLLM, a novel framework that unifies the structural inductive biases of decision forests with the semantic reasoning capabilities of LLMs. Crucially, FORESTLLM leverages the LLM only during training, treating it as an offline model designer that encodes rich, contextual knowledge into a lightweight, interpretable forest model, eliminating the need for LLM inference at test time. Our method is two-fold. First, we introduce a semantic splitting criterion in which the LLM evaluates candidate partitions based on their coherence over both labeled and unlabeled data, enabling the induction of more robust and generalizable tree structures under few-shot supervision. Second, we propose a one-time in-context inference mechanism for leaf node stabilization, where the LLM distills the decision path and its supporting examples into a concise, deterministic prediction, replacing noisy empirical estimates with semantically informed outputs. Across a diverse suite of few-shot classification and regression benchmarks, FORESTLLM achieves state-of-the-art performance.
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Mar 12, 2025Diffusion language models offer unique benefits over autoregressive models due to their potential for parallelized generation and controllability, yet they lag in likelihood modeling and are limited to fixed-length generation. In this work, we introduce a class of block diffusion language models that interpolate between discrete denoising diffusion and autoregressive models. Block diffusion overcomes key limitations of both approaches by supporting flexible-length generation and improving inference efficiency with KV caching and parallel token sampling. We propose a recipe for building effective block diffusion models that includes an efficient training algorithm, estimators of gradient variance, and data-driven noise schedules to minimize the variance. Block diffusion sets a new state-of-the-art performance among diffusion models on language modeling benchmarks and enables generation of arbitrary-length sequences. We provide the code, along with the model weights and blog post on the project page: https://m-arriola.com/bd3lms/
Unveiling the Potential of Multimodal Retrieval Augmented Generation with Planning
Jan 26, 2025Multimodal Retrieval Augmented Generation (MRAG) systems, while promising for enhancing Multimodal Large Language Models (MLLMs), often rely on rigid, single-step retrieval methods. This limitation hinders their ability to effectively address real-world scenarios that demand adaptive information acquisition and query refinement. To overcome this, we introduce the novel task of Multimodal Retrieval Augmented Generation Planning (MRAG Planning), focusing on optimizing MLLM performance while minimizing computational overhead. We present CogPlanner, a versatile framework inspired by human cognitive processes. CogPlanner iteratively refines queries and selects retrieval strategies, enabling both parallel and sequential modeling approaches. To rigorously evaluate MRAG Planning, we introduce CogBench, a new benchmark specifically designed for this task. CogBench facilitates the integration of lightweight CogPlanner with resource-efficient MLLMs. Our experimental findings demonstrate that CogPlanner surpasses existing MRAG baselines, achieving significant improvements in both accuracy and efficiency with minimal computational overhead.
CMViM: Contrastive Masked Vim Autoencoder for 3D Multi-modal Representation Learning for AD classification
Mar 25, 2024Alzheimer's disease (AD) is an incurable neurodegenerative condition leading to cognitive and functional deterioration. Given the lack of a cure, prompt and precise AD diagnosis is vital, a complex process dependent on multiple factors and multi-modal data. While successful efforts have been made to integrate multi-modal representation learning into medical datasets, scant attention has been given to 3D medical images. In this paper, we propose Contrastive Masked Vim Autoencoder (CMViM), the first efficient representation learning method tailored for 3D multi-modal data. Our proposed framework is built on a masked Vim autoencoder to learn a unified multi-modal representation and long-dependencies contained in 3D medical images. We also introduce an intra-modal contrastive learning module to enhance the capability of the multi-modal Vim encoder for modeling the discriminative features in the same modality, and an inter-modal contrastive learning module to alleviate misaligned representation among modalities. Our framework consists of two main steps: 1) incorporate the Vision Mamba (Vim) into the mask autoencoder to reconstruct 3D masked multi-modal data efficiently. 2) align the multi-modal representations with contrastive learning mechanisms from both intra-modal and inter-modal aspects. Our framework is pre-trained and validated ADNI2 dataset and validated on the downstream task for AD classification. The proposed CMViM yields 2.7\% AUC performance improvement compared with other state-of-the-art methods.
PMP-Swin: Multi-Scale Patch Message Passing Swin Transformer for Retinal Disease Classification
Nov 20, 2023Retinal disease is one of the primary causes of visual impairment, and early diagnosis is essential for preventing further deterioration. Nowadays, many works have explored Transformers for diagnosing diseases due to their strong visual representation capabilities. However, retinal diseases exhibit milder forms and often present with overlapping signs, which pose great difficulties for accurate multi-class classification. Therefore, we propose a new framework named Multi-Scale Patch Message Passing Swin Transformer for multi-class retinal disease classification. Specifically, we design a Patch Message Passing (PMP) module based on the Message Passing mechanism to establish global interaction for pathological semantic features and to exploit the subtle differences further between different diseases. Moreover, considering the various scale of pathological features we integrate multiple PMP modules for different patch sizes. For evaluation, we have constructed a new dataset, named OPTOS dataset, consisting of 1,033 high-resolution fundus images photographed by Optos camera and conducted comprehensive experiments to validate the efficacy of our proposed method. And the results on both the public dataset and our dataset demonstrate that our method achieves remarkable performance compared to state-of-the-art methods.
DASA: Difficulty-Aware Semantic Augmentation for Speaker Verification
Oct 18, 2023
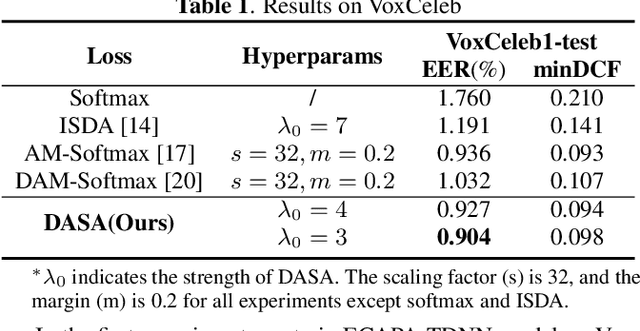


Data augmentation is vital to the generalization ability and robustness of deep neural networks (DNNs) models. Existing augmentation methods for speaker verification manipulate the raw signal, which are time-consuming and the augmented samples lack diversity. In this paper, we present a novel difficulty-aware semantic augmentation (DASA) approach for speaker verification, which can generate diversified training samples in speaker embedding space with negligible extra computing cost. Firstly, we augment training samples by perturbing speaker embeddings along semantic directions, which are obtained from speaker-wise covariance matrices. Secondly, accurate covariance matrices are estimated from robust speaker embeddings during training, so we introduce difficultyaware additive margin softmax (DAAM-Softmax) to obtain optimal speaker embeddings. Finally, we assume the number of augmented samples goes to infinity and derive a closed-form upper bound of the expected loss with DASA, which achieves compatibility and efficiency. Extensive experiments demonstrate the proposed approach can achieve a remarkable performance improvement. The best result achieves a 14.6% relative reduction in EER metric on CN-Celeb evaluation set.
Hierarchical Reinforcement Learning under Mixed Observability
Apr 05, 2022

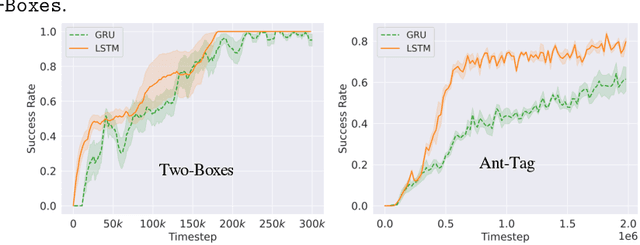
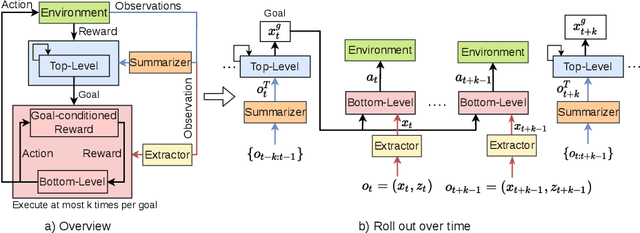
The framework of mixed observable Markov decision processes (MOMDP) models many robotic domains in which some state variables are fully observable while others are not. In this work, we identify a significant subclass of MOMDPs defined by how actions influence the fully observable components of the state and how those, in turn, influence the partially observable components and the rewards. This unique property allows for a two-level hierarchical approach we call HIerarchical Reinforcement Learning under Mixed Observability (HILMO), which restricts partial observability to the top level while the bottom level remains fully observable, enabling higher learning efficiency. The top level produces desired goals to be reached by the bottom level until the task is solved. We further develop theoretical guarantees to show that our approach can achieve optimal and quasi-optimal behavior under mild assumptions. Empirical results on long-horizon continuous control tasks demonstrate the efficacy and efficiency of our approach in terms of improved success rate, sample efficiency, and wall-clock training time. We also deploy policies learned in simulation on a real robot.
Recurrent Off-policy Baselines for Memory-based Continuous Control
Oct 25, 2021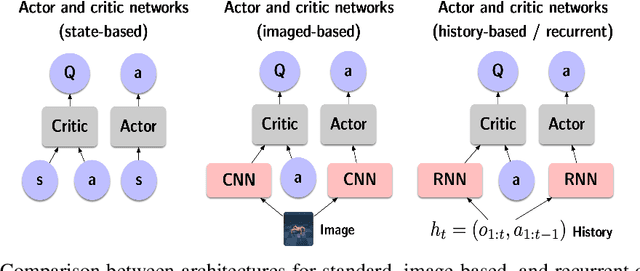
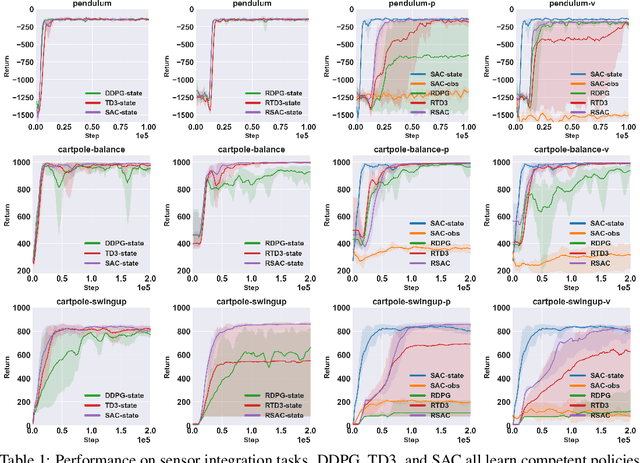


When the environment is partially observable (PO), a deep reinforcement learning (RL) agent must learn a suitable temporal representation of the entire history in addition to a strategy to control. This problem is not novel, and there have been model-free and model-based algorithms proposed for this problem. However, inspired by recent success in model-free image-based RL, we noticed the absence of a model-free baseline for history-based RL that (1) uses full history and (2) incorporates recent advances in off-policy continuous control. Therefore, we implement recurrent versions of DDPG, TD3, and SAC (RDPG, RTD3, and RSAC) in this work, evaluate them on short-term and long-term PO domains, and investigate key design choices. Our experiments show that RDPG and RTD3 can surprisingly fail on some domains and that RSAC is the most reliable, reaching near-optimal performance on nearly all domains. However, one task that requires systematic exploration still proved to be difficult, even for RSAC. These results show that model-free RL can learn good temporal representation using only reward signals; the primary difficulty seems to be computational cost and exploration. To facilitate future research, we have made our PyTorch implementation publicly available at https://github.com/zhihanyang2022/off-policy-continuous-control.
Conditional Level Generation and Game Blending
Oct 13, 2020


Prior research has shown variational autoencoders (VAEs) to be useful for generating and blending game levels by learning latent representations of existing level data. We build on such models by exploring the level design affordances and applications enabled by conditional VAEs (CVAEs). CVAEs augment VAEs by allowing them to be trained using labeled data, thus enabling outputs to be generated conditioned on some input. We studied how increased control in the level generation process and the ability to produce desired outputs via training on labeled game level data could build on prior PCGML methods. Through our results of training CVAEs on levels from Super Mario Bros., Kid Icarus and Mega Man, we show that such models can assist in level design by generating levels with desired level elements and patterns as well as producing blended levels with desired combinations of games.
Game Level Clustering and Generation using Gaussian Mixture VAEs
Aug 22, 2020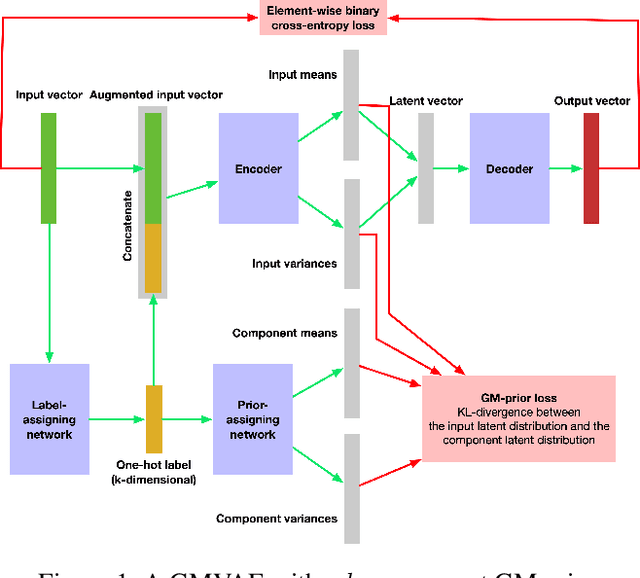



Variational autoencoders (VAEs) have been shown to be able to generate game levels but require manual exploration of the learned latent space to generate outputs with desired attributes. While conditional VAEs address this by allowing generation to be conditioned on labels, such labels have to be provided during training and thus require prior knowledge which may not always be available. In this paper, we apply Gaussian Mixture VAEs (GMVAEs), a variant of the VAE which imposes a mixture of Gaussians (GM) on the latent space, unlike regular VAEs which impose a unimodal Gaussian. This allows GMVAEs to cluster levels in an unsupervised manner using the components of the GM and then generate new levels using the learned components. We demonstrate our approach with levels from Super Mario Bros., Kid Icarus and Mega Man. Our results show that the learned components discover and cluster level structures and patterns and can be used to generate levels with desired characteristics.