 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Off-policy Baselines for Memory-based Continuous Control
Paper and Code
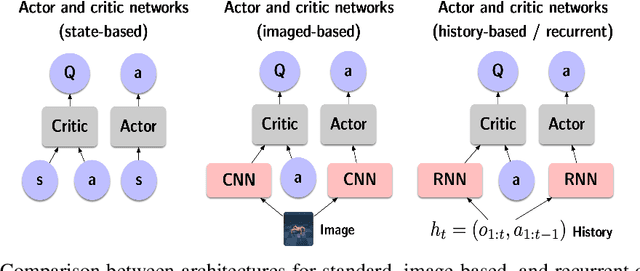
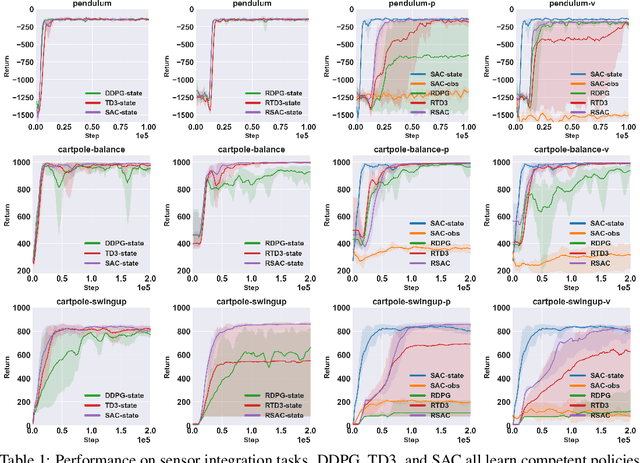


When the environment is partially observable (PO), a deep reinforcement learning (RL) agent must learn a suitable temporal representation of the entire history in addition to a strategy to control. This problem is not novel, and there have been model-free and model-based algorithms proposed for this problem. However, inspired by recent success in model-free image-based RL, we noticed the absence of a model-free baseline for history-based RL that (1) uses full history and (2) incorporates recent advances in off-policy continuous control. Therefore, we implement recurrent versions of DDPG, TD3, and SAC (RDPG, RTD3, and RSAC) in this work, evaluate them on short-term and long-term PO domains, and investigate key design choices. Our experiments show that RDPG and RTD3 can surprisingly fail on some domains and that RSAC is the most reliable, reaching near-optimal performance on nearly all domains. However, one task that requires systematic exploration still proved to be difficult, even for RSAC. These results show that model-free RL can learn good temporal representation using only reward signals; the primary difficulty seems to be computational cost and exploration. To facilitate future research, we have made our PyTorch implementation publicly available at https://github.com/zhihanyang2022/off-policy-continuous-control.