 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Diffusion Scales Competitively with Discrete Diffusion for Language
May 18, 2026While diffusion has drawn considerable recent attention from the language modeling community, continuous diffusion has appeared less scalable than discrete approaches. To challenge this belief we revisit Plaid, a likelihood-based continuous diffusion language model (DLM), and construct RePlaid by aligning the architecture of Plaid with modern discrete DLMs. In this unified setting, we establish the first scaling law for continuous DLMs that rivals discrete DLMs: RePlaid exhibits a compute gap of only $20\times$ compared to autoregressive models, outperforms Duo while using fewer parameters, and outperforms MDLM in the over-trained regime. We benchmark RePlaid against recent continuous DLMs: on OpenWebText, RePlaid achieves a new state-of-the-art PPL bound of $22.1$ among continuous DLMs and superior generation quality. These results suggest that continuous diffusion, when trained via likelihood, is a highly competitive and scalable alternative to discrete DLMs. Moreover, we offer theoretical insights to understand the advantage of likelihood-based training. We show that optimizing the noise schedule to minimize the ELBO's variance naturally yields linear cross-entropy (information loss) over time. This evenly distributes denoising difficulty without any case-specific time reparameterization. In addition, we find that optimizing embeddings via likelihood creates structured geometries and drives the most significant likelihood gain.
The Diffusion Duality, Chapter II: $Ψ$-Samplers and Efficient Curriculum
Feb 24, 2026Uniform-state discrete diffusion models excel at few-step generation and guidance due to their ability to self-correct, making them preferred over autoregressive or Masked diffusion models in these settings. However, their sampling quality plateaus with ancestral samplers as the number of steps increases. We introduce a family of Predictor-Corrector (PC) samplers for discrete diffusion that generalize prior methods and apply to arbitrary noise processes. When paired with uniform-state diffusion, our samplers outperform ancestral sampling on both language and image modeling, achieving lower generative perplexity at matched unigram entropy on OpenWebText and better FID/IS scores on CIFAR10. Crucially, unlike conventional samplers, our PC methods continue to improve with more sampling steps. Taken together, these findings call into question the assumption that Masked diffusion is the inevitable future of diffusion-based language modeling. Beyond sampling, we develop a memory-efficient curriculum for the Gaussian relaxation training phase, reducing training time by 25% and memory by 33% compared to Duo while maintaining comparable perplexity on OpenWebText and LM1B and strong downstream performance. We release code, checkpoints, and a video-tutorial on: https://s-sahoo.com/duo-ch2
Scaling Beyond Masked Diffusion Language Models
Feb 16, 2026Diffusion language models are a promising alternative to autoregressive models due to their potential for faster generation. Among discrete diffusion approaches, Masked diffusion currently dominates, largely driven by strong perplexity on language modeling benchmarks. In this work, we present the first scaling law study of uniform-state and interpolating discrete diffusion methods. We also show that Masked diffusion models can be made approximately 12% more FLOPs-efficient when trained with a simple cross-entropy objective. We find that perplexity is informative within a diffusion family but can be misleading across families, where models with worse likelihood scaling may be preferable due to faster and more practical sampling, as reflected by the speed-quality Pareto frontier. These results challenge the view that Masked diffusion is categorically the future of diffusion language modeling and that perplexity alone suffices for cross-algorithm comparison. Scaling all methods to 1.7B parameters, we show that uniform-state diffusion remains competitive on likelihood-based benchmarks and outperforms autoregressive and Masked diffusion models on GSM8K, despite worse validation perplexity. We provide the code, model checkpoints, and video tutorials on the project page: http://s-sahoo.github.io/scaling-dllms
The Diffusion Duality
Jun 12, 2025Uniform-state discrete diffusion models hold the promise of fast text generation due to their inherent ability to self-correct. However, they are typically outperformed by autoregressive models and masked diffusion models. In this work, we narrow this performance gap by leveraging a key insight: Uniform-state diffusion processes naturally emerge from an underlying Gaussian diffusion. Our method, Duo, transfers powerful techniques from Gaussian diffusion to improve both training and sampling. First, we introduce a curriculum learning strategy guided by the Gaussian process, doubling training speed by reducing variance. Models trained with curriculum learning surpass autoregressive models in zero-shot perplexity on 3 of 7 benchmarks. Second, we present Discrete Consistency Distillation, which adapts consistency distillation from the continuous to the discrete setting. This algorithm unlocks few-step generation in diffusion language models by accelerating sampling by two orders of magnitude. We provide the code and model checkpoints on the project page: http://s-sahoo.github.io/duo
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Mar 12, 2025Diffusion language models offer unique benefits over autoregressive models due to their potential for parallelized generation and controllability, yet they lag in likelihood modeling and are limited to fixed-length generation. In this work, we introduce a class of block diffusion language models that interpolate between discrete denoising diffusion and autoregressive models. Block diffusion overcomes key limitations of both approaches by supporting flexible-length generation and improving inference efficiency with KV caching and parallel token sampling. We propose a recipe for building effective block diffusion models that includes an efficient training algorithm, estimators of gradient variance, and data-driven noise schedules to minimize the variance. Block diffusion sets a new state-of-the-art performance among diffusion models on language modeling benchmarks and enables generation of arbitrary-length sequences. We provide the code, along with the model weights and blog post on the project page: https://m-arriola.com/bd3lms/
Simple Guidance Mechanisms for Discrete Diffusion Models
Dec 13, 2024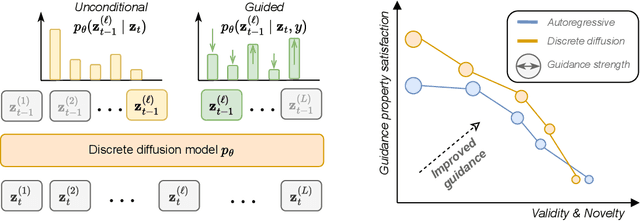
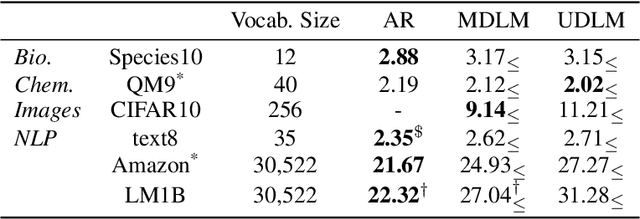
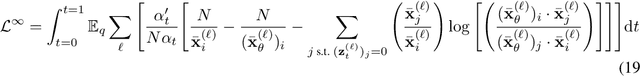
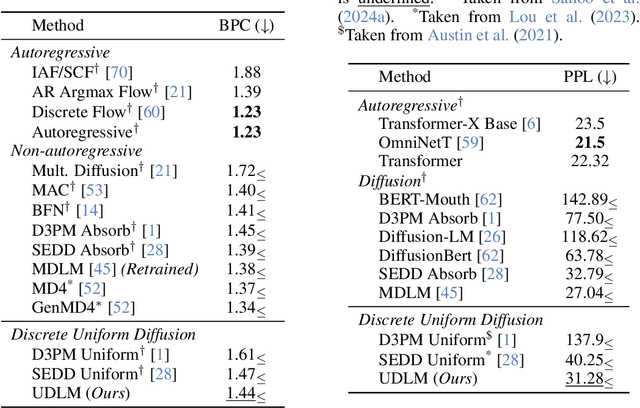
Diffusion models for continuous data gained widespread adoption owing to their high quality generation and control mechanisms. However, controllable diffusion on discrete data faces challenges given that continuous guidance methods do not directly apply to discrete diffusion. Here, we provide a straightforward derivation of classifier-free and classifier-based guidance for discrete diffusion, as well as a new class of diffusion models that leverage uniform noise and that are more guidable because they can continuously edit their outputs. We improve the quality of these models with a novel continuous-time variational lower bound that yields state-of-the-art performance, especially in settings involving guidance or fast generation. Empirically, we demonstrate that our guidance mechanisms combined with uniform noise diffusion improve controllable generation relative to autoregressive and diffusion baselines on several discrete data domains, including genomic sequences, small molecule design, and discretized image generation.
Simple and Effective Masked Diffusion Language Models
Jun 11, 2024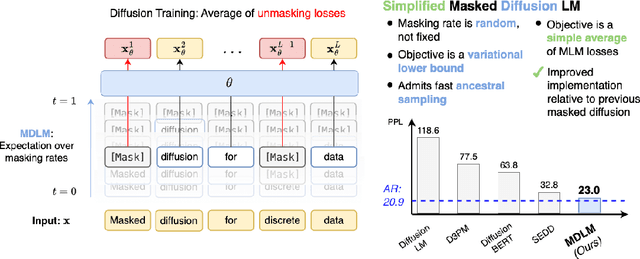
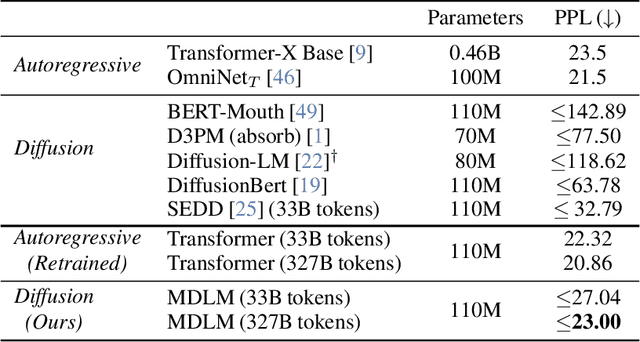
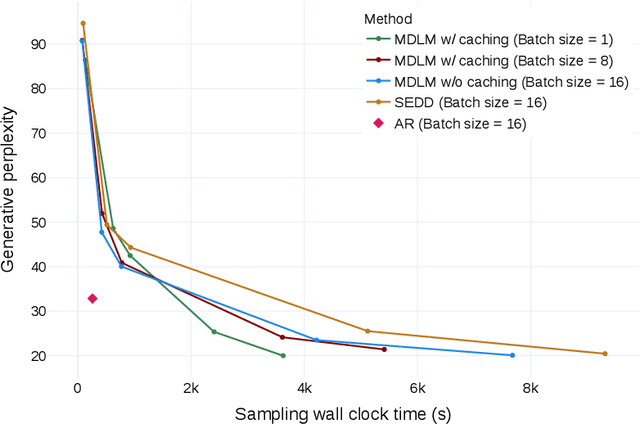

While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling. In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements. Our objective has a simple form -- it is a mixture of classical masked language modeling losses -- and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model. On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We release our code at: https://github.com/kuleshov-group/mdlm
Diffusion Models With Learned Adaptive Noise
Dec 20, 2023



Diffusion models have gained traction as powerful algorithms for synthesizing high-quality images. Central to these algorithms is the diffusion process, which maps data to noise according to equations inspired by thermodynamics and can significantly impact performance. A widely held assumption is that the ELBO objective of a diffusion model is invariant to the noise process (Kingma et al.,2021). In this work, we dispel this assumption -- we propose multivariate learned adaptive noise (MuLAN), a learned diffusion process that applies Gaussian noise at different rates across an image. Our method consists of three components -- a multivariate noise schedule, instance-conditional diffusion, and auxiliary variables -- which ensure that the learning objective is no longer invariant to the choice of the noise schedule as in previous works. Our work is grounded in Bayesian inference and casts the learned diffusion process as an approximate variational posterior that yields a tighter lower bound on marginal likelihood. Empirically, MuLAN sets a new state-of-the-art in density estimation on CIFAR-10 and ImageNet compared to classical diffusion. Code is available at https://github.com/s-sahoo/MuLAN
Gradient Backpropagation Through Combinatorial Algorithms: Identity with Projection Works
May 30, 2022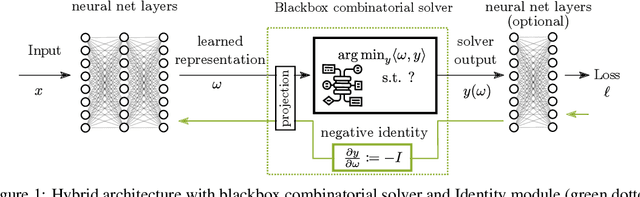
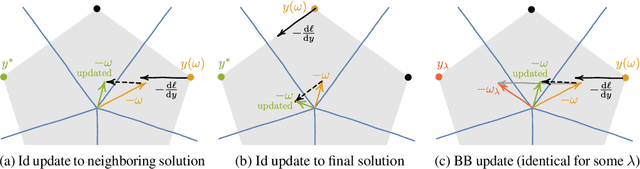
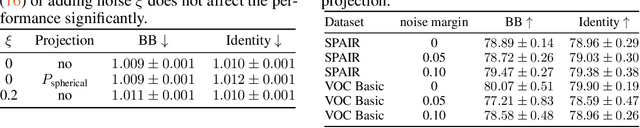
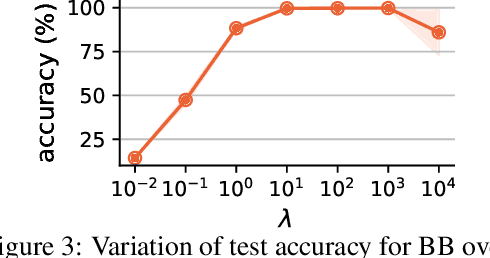
Embedding discrete solvers as differentiable layers has given modern deep learning architectures combinatorial expressivity and discrete reasoning capabilities. The derivative of these solvers is zero or undefined, therefore a meaningful replacement is crucial for effective gradient-based learning. Prior works rely on smoothing the solver with input perturbations, relaxing the solver to continuous problems, or interpolating the loss landscape with techniques that typically require additional solver calls, introduce extra hyper-parameters or compromise performance. We propose a principled approach to exploit the geometry of the discrete solution space to treat the solver as a negative identity on the backward pass and further provide a theoretical justification. Our experiments demonstrate that such a straightforward hyper-parameter-free approach is on-par with or outperforms previous more complex methods on numerous experiments such as Traveling Salesman Problem, Shortest Path, Deep Graph Matching, and backpropagating through discrete samplers. Furthermore, we substitute the previously proposed problem-specific and label-dependent margin by a generic regularization procedure that prevents cost collapse and increases robustness.
Scaling Symbolic Methods using Gradients for Neural Model Explanation
Jun 29, 2020
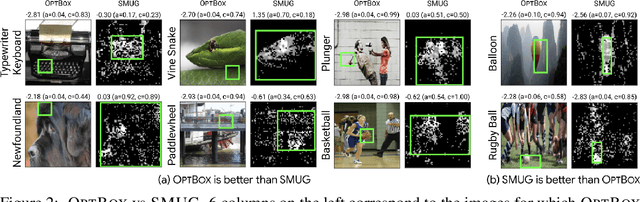
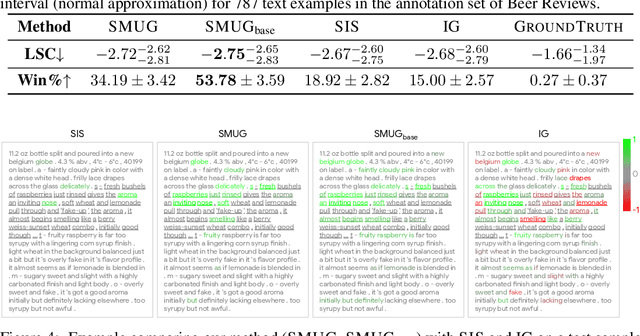

Symbolic techniques based on Satisfiability Modulo Theory (SMT) solvers have been proposed for analyzing and verifying neural network properties, but their usage has been fairly limited owing to their poor scalability with larger networks. In this work, we propose a technique for combining gradient-based methods with symbolic techniques to scale such analyses and demonstrate its application for model explanation. In particular, we apply this technique to identify minimal regions in an input that are most relevant for a neural network's prediction. Our approach uses gradient information (based on Integrated Gradients) to focus on a subset of neurons in the first layer, which allows our technique to scale to large networks. The corresponding SMT constraints encode the minimal input mask discovery problem such that after masking the input, the activations of the selected neurons are still above a threshold. After solving for the minimal masks, our approach scores the mask regions to generate a relative ordering of the features within the mask. This produces a saliency map which explains "where a model is looking" when making a prediction. We evaluate our technique on three datasets - MNIST, ImageNet, and Beer Reviews, and demonstrate both quantitatively and qualitatively that the regions generated by our approach are sparser and achieve higher saliency scores compared to the gradient-based methods alone.