 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Guidance Mechanisms for Discrete Diffusion Models
Dec 13, 2024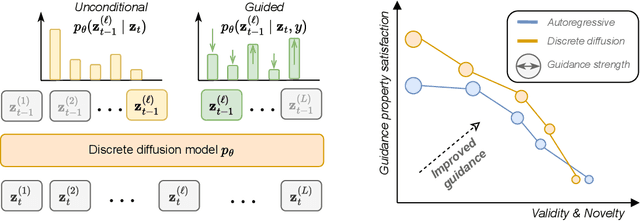
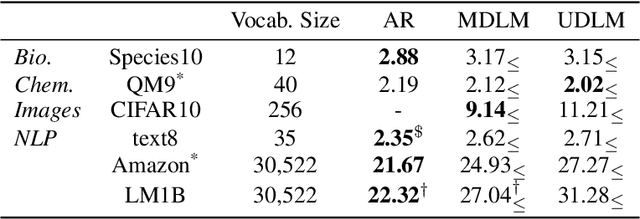
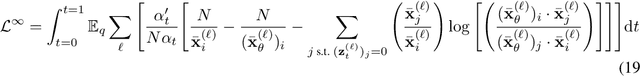
Diffusion models for continuous data gained widespread adoption owing to their high quality generation and control mechanisms. However, controllable diffusion on discrete data faces challenges given that continuous guidance methods do not directly apply to discrete diffusion. Here, we provide a straightforward derivation of classifier-free and classifier-based guidance for discrete diffusion, as well as a new class of diffusion models that leverage uniform noise and that are more guidable because they can continuously edit their outputs. We improve the quality of these models with a novel continuous-time variational lower bound that yields state-of-the-art performance, especially in settings involving guidance or fast generation. Empirically, we demonstrate that our guidance mechanisms combined with uniform noise diffusion improve controllable generation relative to autoregressive and diffusion baselines on several discrete data domains, including genomic sequences, small molecule design, and discretized image generation.
Simple and Effective Masked Diffusion Language Models
Jun 11, 2024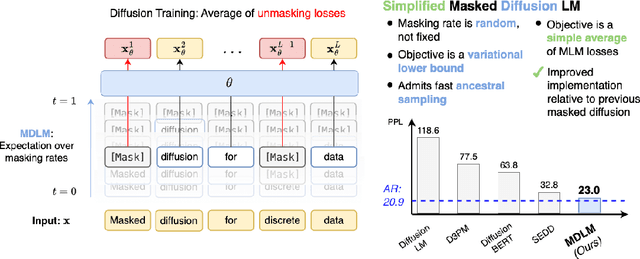
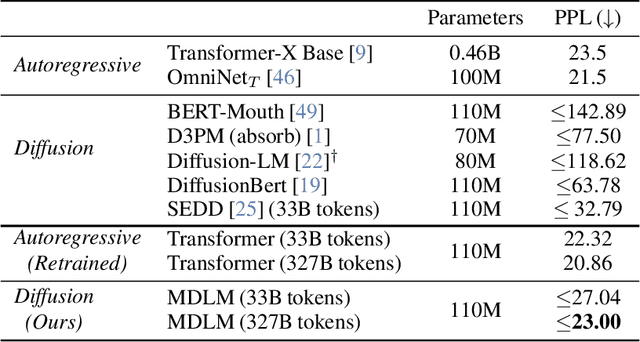
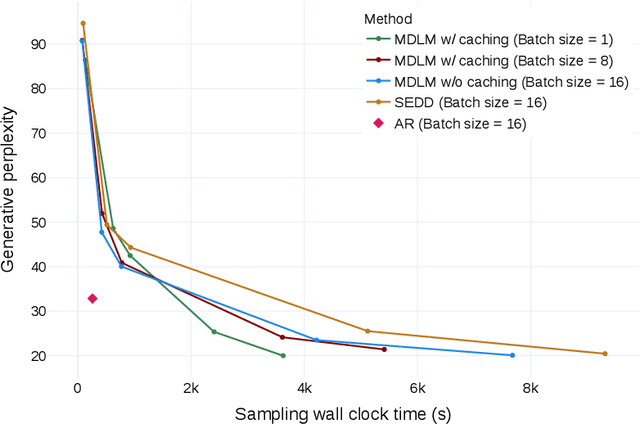

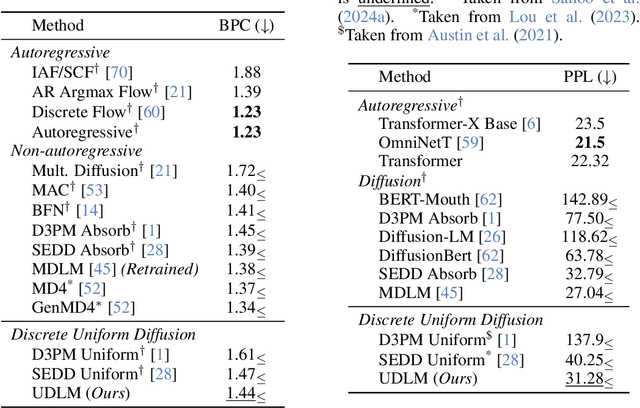
While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling. In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements. Our objective has a simple form -- it is a mixture of classical masked language modeling losses -- and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model. On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We release our code at: https://github.com/kuleshov-group/mdlm
Developmental Stage Classification of Embryos Using Two-Stream Neural Network with Linear-Chain Conditional Random Field
Jul 13, 2021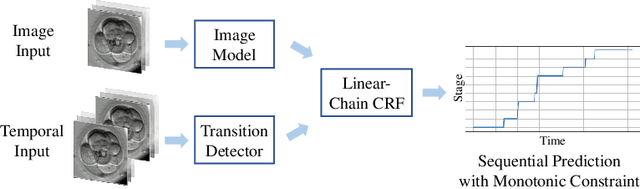
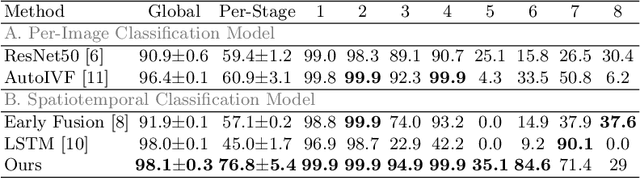

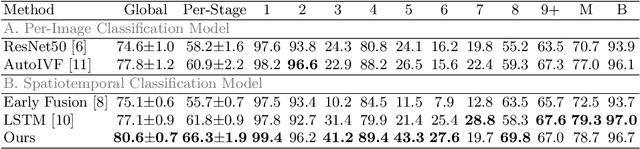
The developmental process of embryos follows a monotonic order. An embryo can progressively cleave from one cell to multiple cells and finally transform to morula and blastocyst. For time-lapse videos of embryos, most existing developmental stage classification methods conduct per-frame predictions using an image frame at each time step. However, classification using only images suffers from overlapping between cells and imbalance between stages. Temporal information can be valuable in addressing this problem by capturing movements between neighboring frames. In this work, we propose a two-stream model for developmental stage classification. Unlike previous methods, our two-stream model accepts both temporal and image information. We develop a linear-chain conditional random field (CRF) on top of neural network features extracted from the temporal and image streams to make use of both modalities. The linear-chain CRF formulation enables tractable training of global sequential models over multiple frames while also making it possible to inject monotonic development order constraints into the learning process explicitly. We demonstrate our algorithm on two time-lapse embryo video datasets: i) mouse and ii) human embryo datasets. Our method achieves 98.1 % and 80.6 % for mouse and human embryo stage classification, respectively. Our approach will enable more profound clinical and biological studies and suggests a new direction for developmental stage classification by utilizing temporal information.
Improving Event Duration Prediction via Time-aware Pre-training
Nov 05, 2020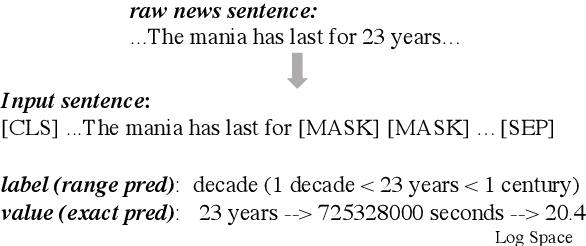
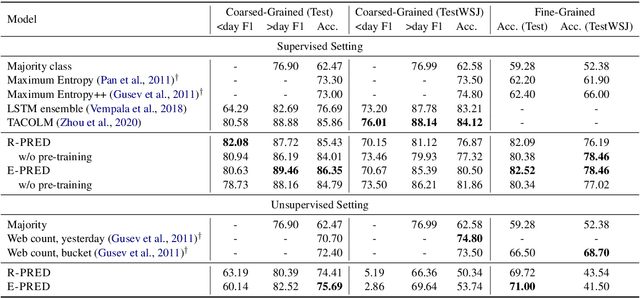
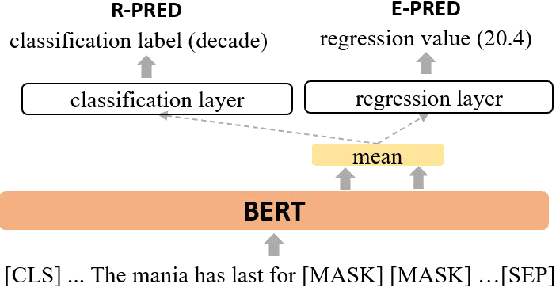
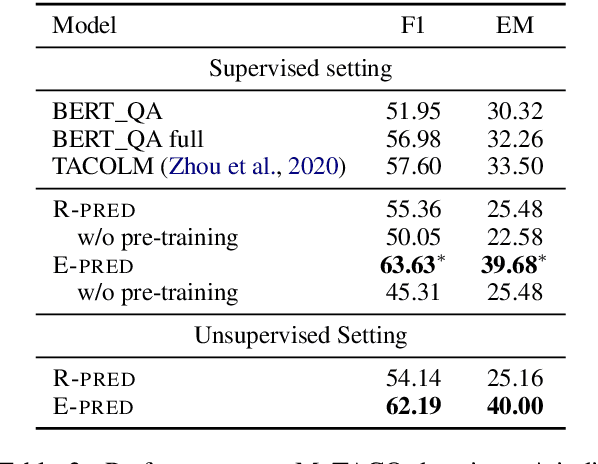
End-to-end models in NLP rarely encode external world knowledge about length of time. We introduce two effective models for duration prediction, which incorporate external knowledge by reading temporal-related news sentences (time-aware pre-training). Specifically, one model predicts the range/unit where the duration value falls in (R-pred); and the other predicts the exact duration value E-pred. Our best model -- E-pred, substantially outperforms previous work, and captures duration information more accurately than R-pred. We also demonstrate our models are capable of duration prediction in the unsupervised setting, outperforming the baselines.
Document-level Event-based Extraction Using Generative Template-filling Transformers
Aug 21, 2020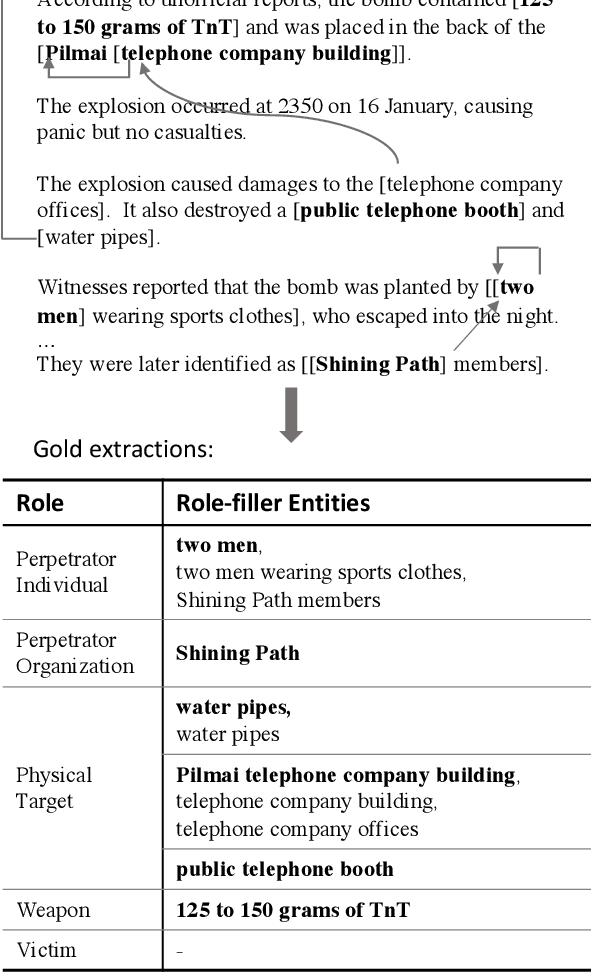

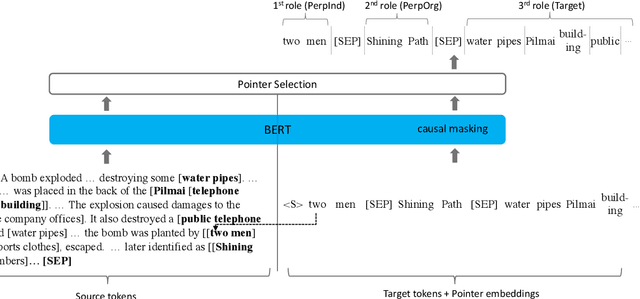
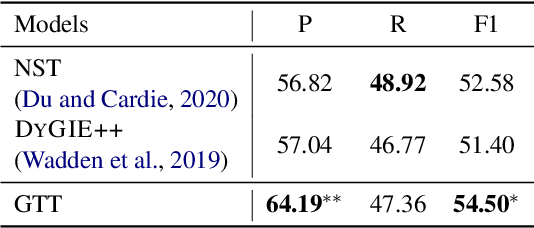
We revisit the classic information extraction problem of document-level template filling. We argue that sentence-level approaches are ill-suited to the task and introduce a generative transformer-based encoder-decoder framework that is designed to model context at the document level: it can make extraction decisions across sentence boundaries; is \emph{implicitly} aware of noun phrase coreference structure, and has the capacity to respect cross-role dependencies in the template structure. We evaluate our approach on the MUC-4 dataset, and show that our model performs substantially better than prior work. We also show that our modeling choices contribute to model performance, e.g., by implicitly capturing linguistic knowledge such as recognizing coreferent entity mentions. Our code for the evaluation script and models will be open-sourced at https://github.com/xinyadu/doc_event_entity for reproduction purposes.
AdaptivFloat: A Floating-point based Data Type for Resilient Deep Learning Inference
Oct 15, 2019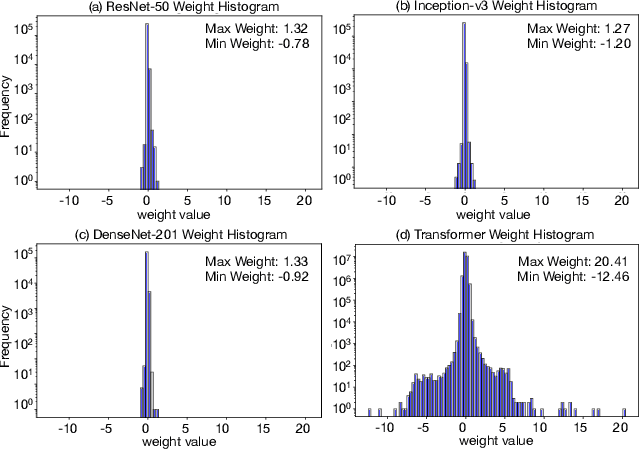

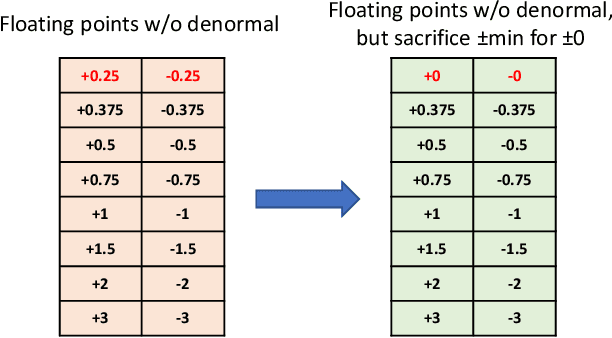

Conventional hardware-friendly quantization methods, such as fixed-point or integer, tend to perform poorly at very low word sizes as their shrinking dynamic ranges cannot adequately capture the wide data distributions commonly seen in sequence transduction models. We present AdaptivFloat, a floating-point inspired number representation format for deep learning that dynamically maximizes and optimally clips its available dynamic range, at a layer granularity, in order to create faithful encoding of neural network parameters. AdaptivFloat consistently produces higher inference accuracies compared to block floating-point, uniform, IEEE-like float or posit encodings at very low precision ($\leq$ 8-bit) across a diverse set of state-of-the-art neural network topologies. And notably, AdaptivFloat is seen surpassing baseline FP32 performance by up to +0.3 in BLEU score and -0.75 in word error rate at weight bit widths that are $\leq$ 8-bit. Experimental results on a deep neural network (DNN) hardware accelerator, exploiting AdaptivFloat logic in its computational datapath, demonstrate per-operation energy and area that is 0.9$\times$ and 1.14$\times$, respectively, that of equivalent bit width integer-based accelerator variants.
Tensor Variable Elimination for Plated Factor Graphs
Feb 08, 2019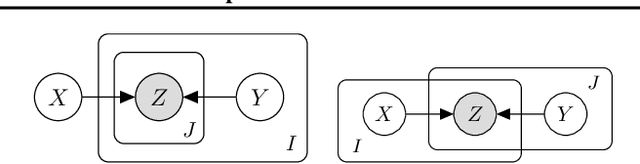
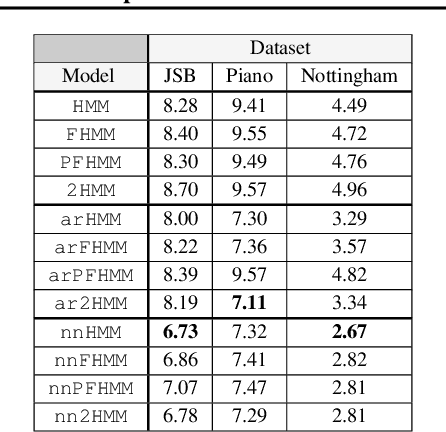
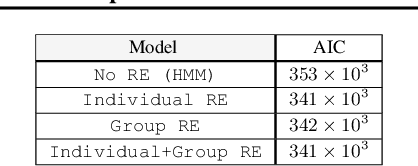
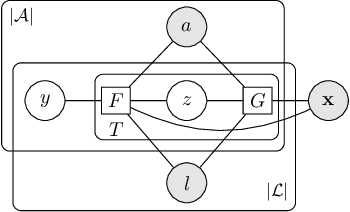
A wide class of machine learning algorithms can be reduced to variable elimination on factor graphs. While factor graphs provide a unifying notation for these algorithms, they do not provide a compact way to express repeated structure when compared to plate diagrams for directed graphical models. To exploit efficient tensor algebra in graphs with plates of variables, we generalize undirected factor graphs to plated factor graphs and variable elimination to a tensor variable elimination algorithm that operates directly on plated factor graphs. Moreover, we generalize complexity bounds based on treewidth and characterize the class of plated factor graphs for which inference is tractable. As an application, we integrate tensor variable elimination into the Pyro probabilistic programming language to enable exact inference in discrete latent variable models with repeated structure. We validate our methods with experiments on both directed and undirected graphical models, including applications to polyphonic music modeling, animal movement modeling, and latent sentiment analysis.
On the Flip Side: Identifying Counterexamples in Visual Question Answering
Jul 24, 2018
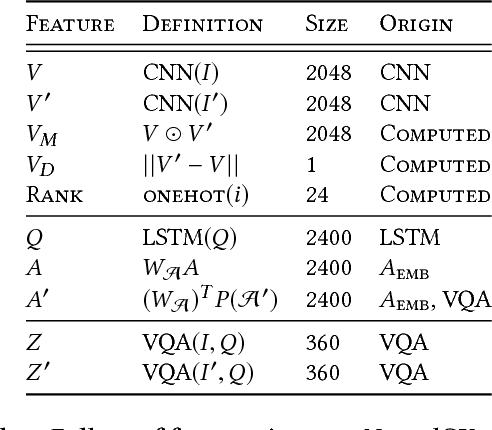
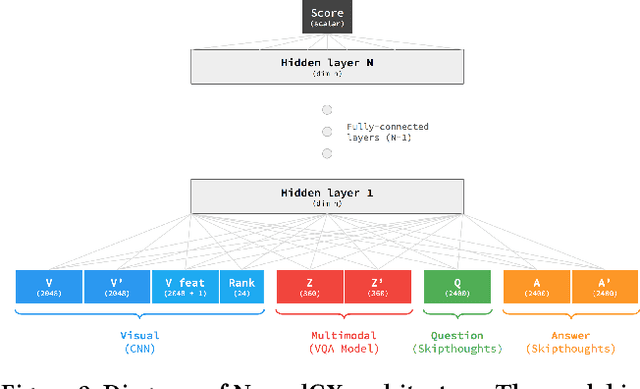

Visual question answering (VQA) models respond to open-ended natural language questions about images. While VQA is an increasingly popular area of research, it is unclear to what extent current VQA architectures learn key semantic distinctions between visually-similar images. To investigate this question, we explore a reformulation of the VQA task that challenges models to identify counterexamples: images that result in a different answer to the original question. We introduce two methods for evaluating existing VQA models against a supervised counterexample prediction task, VQA-CX. While our models surpass existing benchmarks on VQA-CX, we find that the multimodal representations learned by an existing state-of-the-art VQA model do not meaningfully contribute to performance on this task. These results call into question the assumption that successful performance on the VQA benchmark is indicative of general visual-semantic reasoning abilities.