 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument-level Event-based Extraction Using Generative Template-filling Transformers
Paper and Code
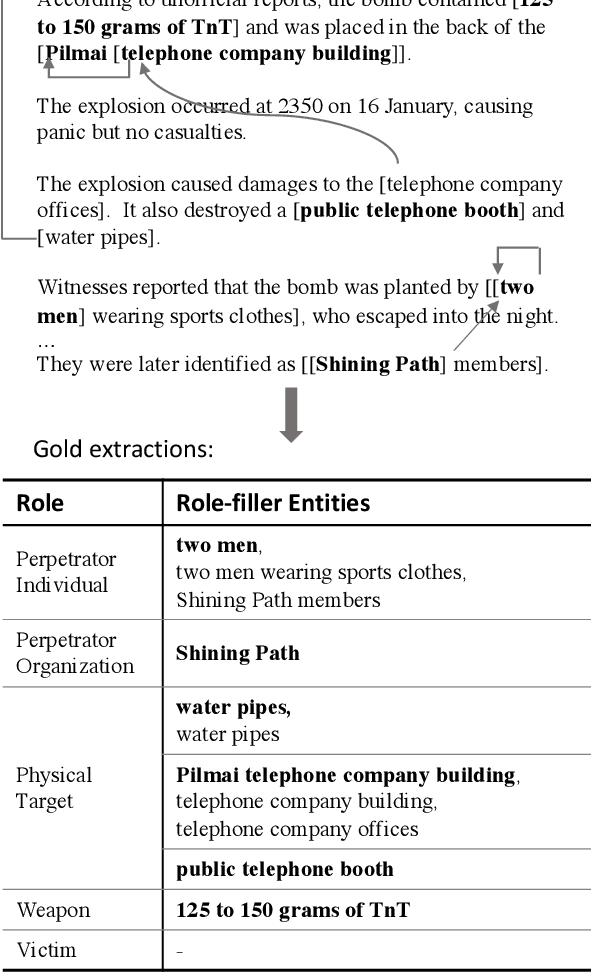

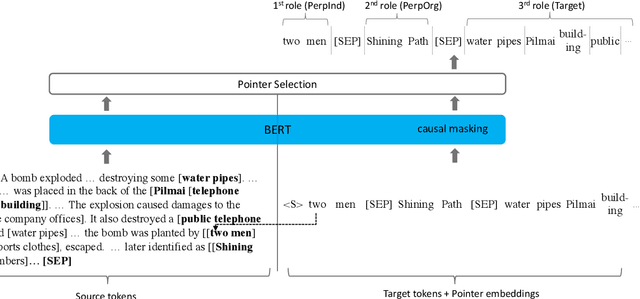
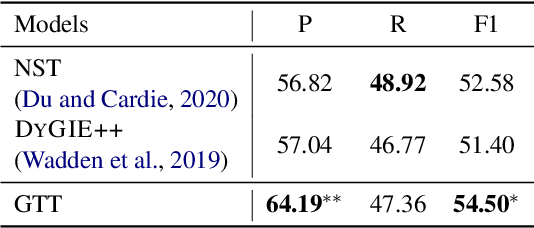
We revisit the classic information extraction problem of document-level template filling. We argue that sentence-level approaches are ill-suited to the task and introduce a generative transformer-based encoder-decoder framework that is designed to model context at the document level: it can make extraction decisions across sentence boundaries; is \emph{implicitly} aware of noun phrase coreference structure, and has the capacity to respect cross-role dependencies in the template structure. We evaluate our approach on the MUC-4 dataset, and show that our model performs substantially better than prior work. We also show that our modeling choices contribute to model performance, e.g., by implicitly capturing linguistic knowledge such as recognizing coreferent entity mentions. Our code for the evaluation script and models will be open-sourced at https://github.com/xinyadu/doc_event_entity for reproduction purposes.