 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spatiotemporal Epidemic Model to Quantify the Effects of Contact Tracing, Testing, and Containment
Apr 24, 2020
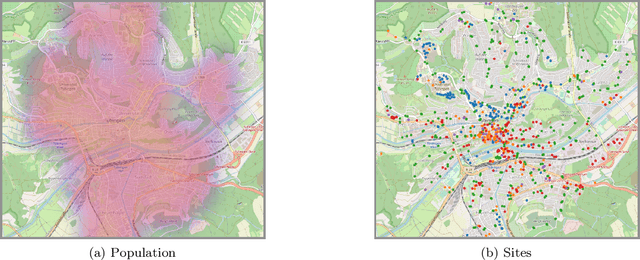

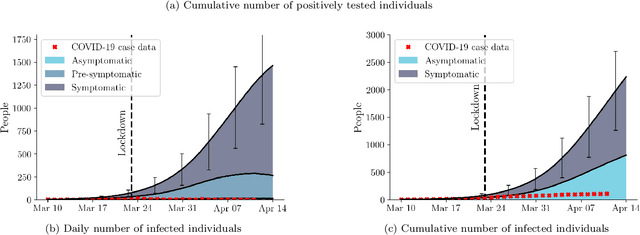
Motivated by the current COVID-19 outbreak, we introduce a novel epidemic model based on marked temporal point processes that is specifically designed to make fine-grained spatiotemporal predictions about the course of the disease in a population. Our model can make use and benefit from data gathered by a variety of contact tracing technologies and it can quantify the effects that different testing and tracing strategies, social distancing measures, and business restrictions may have on the course of the disease. Building on our model, we use Bayesian optimization to estimate the risk of exposure of each individual at the sites they visit, the percentage of symptomatic individuals, and the difference in transmission rate between asymptomatic and symptomatic individuals from historical longitudinal testing data. Experiments using real COVID-19 data and mobility patterns from T\"{u}bingen, a town in the southwest of Germany, demonstrate that our model can be used to quantify the effects of tracing, testing, and containment strategies at an unprecedented spatiotemporal resolution. To facilitate research and informed policy-making, particularly in the context of the current COVID-19 outbreak, we are releasing an open-source implementation of our framework at https://github.com/covid19-model.
A Kernel of Truth: Determining Rumor Veracity on Twitter by Diffusion Pattern Alone
Feb 06, 2020
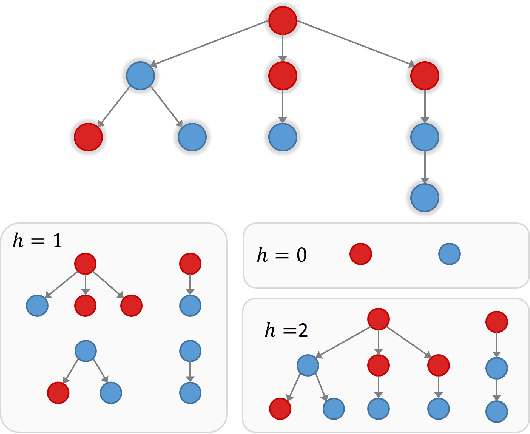


Recent work in the domain of misinformation detection has leveraged rich signals in the text and user identities associated with content on social media. But text can be strategically manipulated and accounts reopened under different aliases, suggesting that these approaches are inherently brittle. In this work, we investigate an alternative modality that is naturally robust: the pattern in which information propagates. Can the veracity of an unverified rumor spreading online be discerned solely on the basis of its pattern of diffusion through the social network? Using graph kernels to extract complex topological information from Twitter cascade structures, we train accurate predictive models that are blind to language, user identities, and time, demonstrating for the first time that such "sanitized" diffusion patterns are highly informative of veracity. Our results indicate that, with proper aggregation, the collective sharing pattern of the crowd may reveal powerful signals of rumor truth or falsehood, even in the early stages of propagation.
On the Flip Side: Identifying Counterexamples in Visual Question Answering
Jul 24, 2018
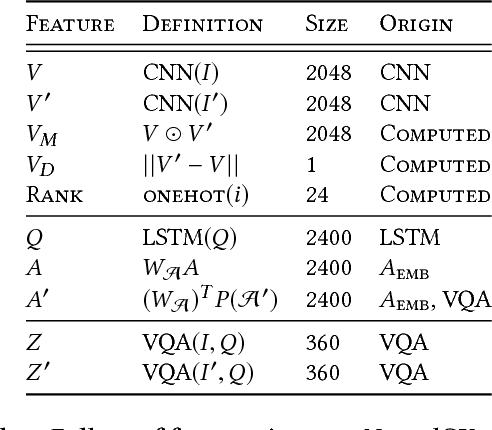
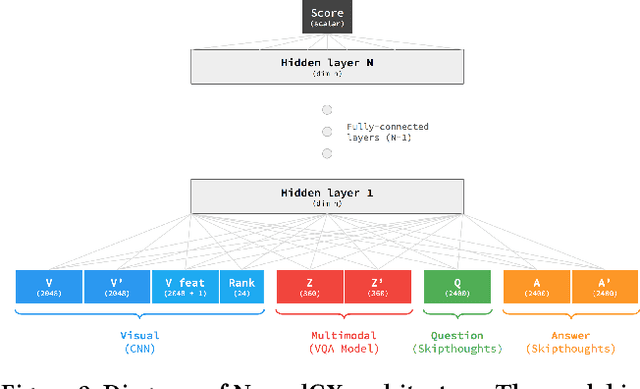

Visual question answering (VQA) models respond to open-ended natural language questions about images. While VQA is an increasingly popular area of research, it is unclear to what extent current VQA architectures learn key semantic distinctions between visually-similar images. To investigate this question, we explore a reformulation of the VQA task that challenges models to identify counterexamples: images that result in a different answer to the original question. We introduce two methods for evaluating existing VQA models against a supervised counterexample prediction task, VQA-CX. While our models surpass existing benchmarks on VQA-CX, we find that the multimodal representations learned by an existing state-of-the-art VQA model do not meaningfully contribute to performance on this task. These results call into question the assumption that successful performance on the VQA benchmark is indicative of general visual-semantic reasoning abilities.