 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Diffusion Duality
Jun 12, 2025Uniform-state discrete diffusion models hold the promise of fast text generation due to their inherent ability to self-correct. However, they are typically outperformed by autoregressive models and masked diffusion models. In this work, we narrow this performance gap by leveraging a key insight: Uniform-state diffusion processes naturally emerge from an underlying Gaussian diffusion. Our method, Duo, transfers powerful techniques from Gaussian diffusion to improve both training and sampling. First, we introduce a curriculum learning strategy guided by the Gaussian process, doubling training speed by reducing variance. Models trained with curriculum learning surpass autoregressive models in zero-shot perplexity on 3 of 7 benchmarks. Second, we present Discrete Consistency Distillation, which adapts consistency distillation from the continuous to the discrete setting. This algorithm unlocks few-step generation in diffusion language models by accelerating sampling by two orders of magnitude. We provide the code and model checkpoints on the project page: http://s-sahoo.github.io/duo
RakutenAI-7B: Extending Large Language Models for Japanese
Mar 21, 2024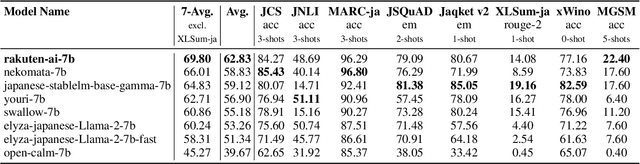
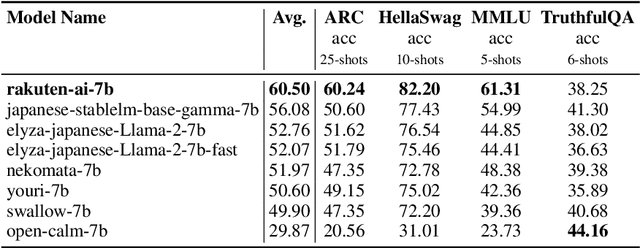
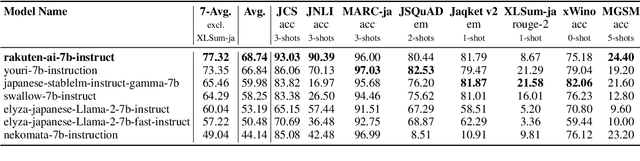
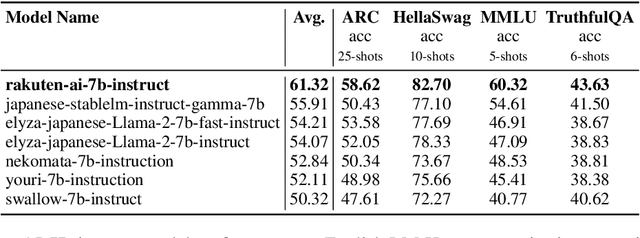
We introduce RakutenAI-7B, a suite of Japanese-oriented large language models that achieve the best performance on the Japanese LM Harness benchmarks among the open 7B models. Along with the foundation model, we release instruction- and chat-tuned models, RakutenAI-7B-instruct and RakutenAI-7B-chat respectively, under the Apache 2.0 license.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
A Simple Recipe for Contrastively Pre-training Video-First Encoders Beyond 16 Frames
Dec 12, 2023



Understanding long, real-world videos requires modeling of long-range visual dependencies. To this end, we explore video-first architectures, building on the common paradigm of transferring large-scale, image--text models to video via shallow temporal fusion. However, we expose two limitations to the approach: (1) decreased spatial capabilities, likely due to poor video--language alignment in standard video datasets, and (2) higher memory consumption, bottlenecking the number of frames that can be processed. To mitigate the memory bottleneck, we systematically analyze the memory/accuracy trade-off of various efficient methods: factorized attention, parameter-efficient image-to-video adaptation, input masking, and multi-resolution patchification. Surprisingly, simply masking large portions of the video (up to 75%) during contrastive pre-training proves to be one of the most robust ways to scale encoders to videos up to 4.3 minutes at 1 FPS. Our simple approach for training long video-to-text models, which scales to 1B parameters, does not add new architectural complexity and is able to outperform the popular paradigm of using much larger LLMs as an information aggregator over segment-based information on benchmarks with long-range temporal dependencies (YouCook2, EgoSchema).
Zero redundancy distributed learning with differential privacy
Nov 20, 2023
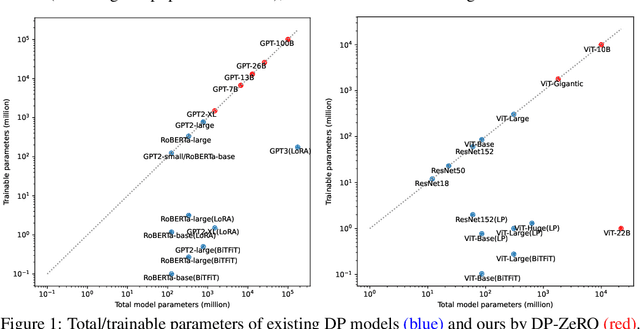

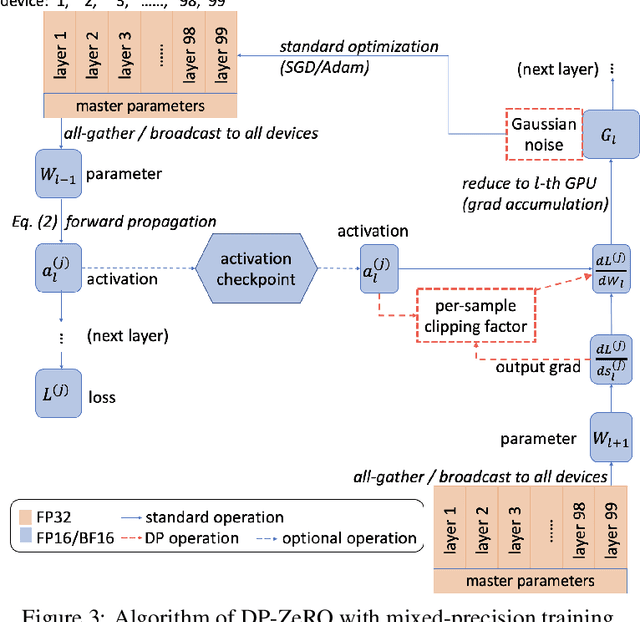
Deep learning using large models have achieved great success in a wide range of domains. However, training these models on billions of parameters is very challenging in terms of the training speed, memory cost, and communication efficiency, especially under the privacy-preserving regime with differential privacy (DP). On the one hand, DP optimization has comparable efficiency to the standard non-private optimization on a single GPU, but on multiple GPUs, existing DP distributed learning (such as pipeline parallel) has suffered from significantly worse efficiency. On the other hand, the Zero Redundancy Optimizer (ZeRO) is a state-of-the-art solution to the standard distributed learning, exhibiting excellent training efficiency on large models, but to work compatibly with DP is technically complicated. In this work, we develop a new systematic solution, DP-ZeRO, (I) to scale up the trainable DP model size, e.g. to GPT-100B, (II) to obtain the same computation and communication efficiency as the standard ZeRO, and (III) to enable mixed-precision DP training. Our DP-ZeRO, like the standard ZeRO, has the potential to train models with arbitrary size and is evaluated on the world's largest DP models in terms of the number of trainable parameters.
Multi-output Headed Ensembles for Product Item Classification
Jul 29, 2023



In this paper, we revisit the problem of product item classification for large-scale e-commerce catalogs. The taxonomy of e-commerce catalogs consists of thousands of genres to which are assigned items that are uploaded by merchants on a continuous basis. The genre assignments by merchants are often wrong but treated as ground truth labels in automatically generated training sets, thus creating a feedback loop that leads to poorer model quality over time. This problem of taxonomy classification becomes highly pronounced due to the unavailability of sizable curated training sets. Under such a scenario it is common to combine multiple classifiers to combat poor generalization performance from a single classifier. We propose an extensible deep learning based classification model framework that benefits from the simplicity and robustness of averaging ensembles and fusion based classifiers. We are also able to use metadata features and low-level feature engineering to boost classification performance. We show these improvements against robust industry standard baseline models that employ hyperparameter optimization. Additionally, due to continuous insertion, deletion and updates to real-world high-volume e-commerce catalogs, assessing model performance for deployment using A/B testing and/or manual annotation becomes a bottleneck. To this end, we also propose a novel way to evaluate model performance using user sessions that provides better insights in addition to traditional measures of precision and recall.
Tensor Variable Elimination for Plated Factor Graphs
Feb 08, 2019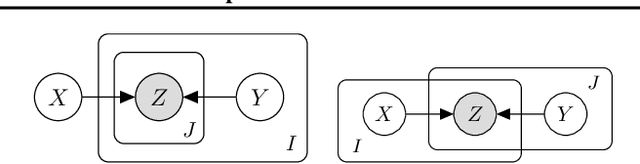
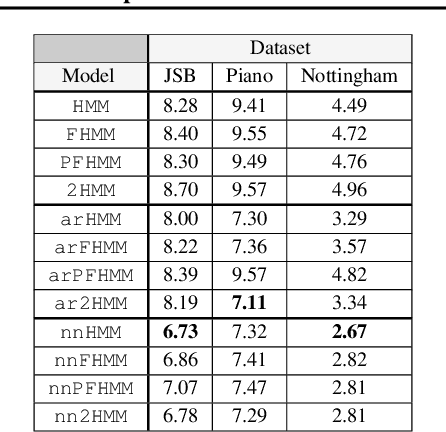
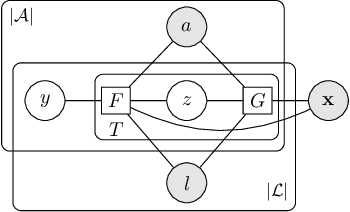
A wide class of machine learning algorithms can be reduced to variable elimination on factor graphs. While factor graphs provide a unifying notation for these algorithms, they do not provide a compact way to express repeated structure when compared to plate diagrams for directed graphical models. To exploit efficient tensor algebra in graphs with plates of variables, we generalize undirected factor graphs to plated factor graphs and variable elimination to a tensor variable elimination algorithm that operates directly on plated factor graphs. Moreover, we generalize complexity bounds based on treewidth and characterize the class of plated factor graphs for which inference is tractable. As an application, we integrate tensor variable elimination into the Pyro probabilistic programming language to enable exact inference in discrete latent variable models with repeated structure. We validate our methods with experiments on both directed and undirected graphical models, including applications to polyphonic music modeling, animal movement modeling, and latent sentiment analysis.
Latent Alignment and Variational Attention
Jul 10, 2018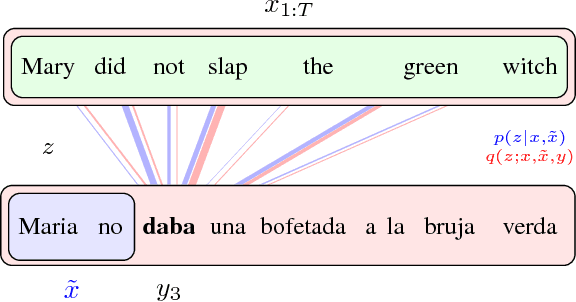
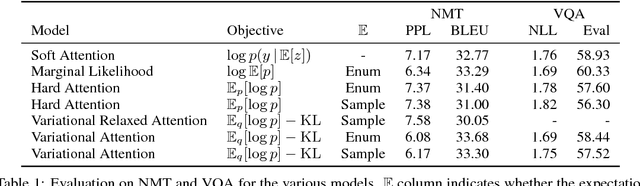
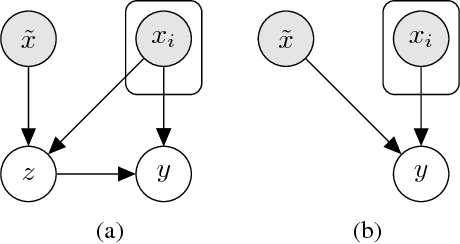
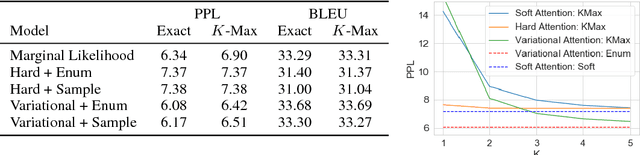
Neural attention has become central to many state-of-the-art models in natural language processing and related domains. Attention networks are an easy-to-train and effective method for softly simulating alignment; however, the approach does not marginalize over latent alignments in a probabilistic sense. This property makes it difficult to compare attention to other alignment approaches, to compose it with probabilistic models, and to perform posterior inference conditioned on observed data. A related latent approach, hard attention, fixes these issues, but is generally harder to train and less accurate. This work considers variational attention networks, alternatives to soft and hard attention for learning latent variable alignment models, with tighter approximation bounds based on amortized variational inference. We further propose methods for reducing the variance of gradients to make these approaches computationally feasible. Experiments show that for machine translation and visual question answering, inefficient exact latent variable models outperform standard neural attention, but these gains go away when using hard attention based training. On the other hand, variational attention retains most of the performance gain but with training speed comparable to neural attention.