 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRakutenAI-7B: Extending Large Language Models for Japanese
Mar 21, 2024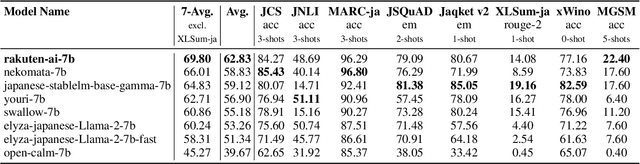
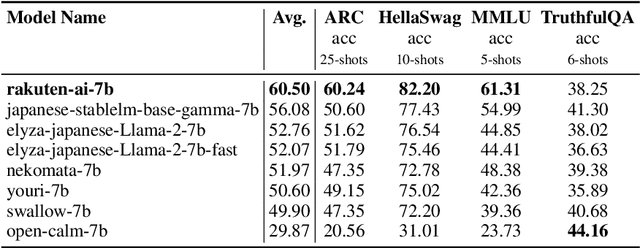
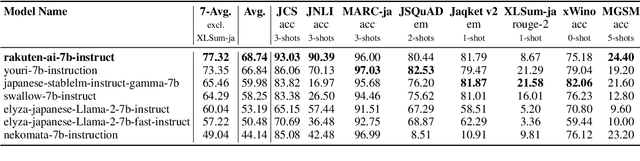
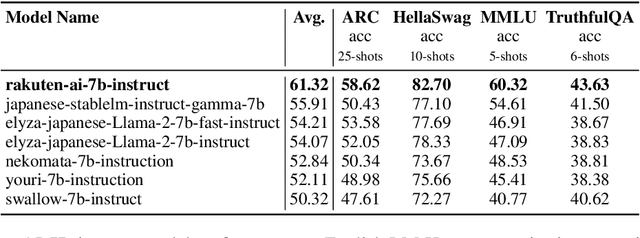
We introduce RakutenAI-7B, a suite of Japanese-oriented large language models that achieve the best performance on the Japanese LM Harness benchmarks among the open 7B models. Along with the foundation model, we release instruction- and chat-tuned models, RakutenAI-7B-instruct and RakutenAI-7B-chat respectively, under the Apache 2.0 license.
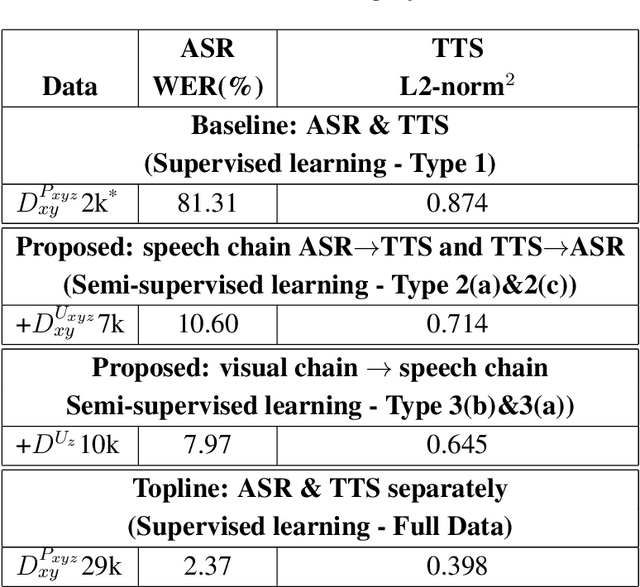
Augmenting Images for ASR and TTS through Single-loop and Dual-loop Multimodal Chain Framework
Nov 04, 2020



Previous research has proposed a machine speech chain to enable automatic speech recognition (ASR) and text-to-speech synthesis (TTS) to assist each other in semi-supervised learning and to avoid the need for a large amount of paired speech and text data. However, that framework still requires a large amount of unpaired (speech or text) data. A prototype multimodal machine chain was then explored to further reduce the need for a large amount of unpaired data, which could improve ASR or TTS even when no more speech or text data were available. Unfortunately, this framework relied on the image retrieval (IR) model, and thus it was limited to handling only those images that were already known during training. Furthermore, the performance of this framework was only investigated with single-speaker artificial speech data. In this study, we revamp the multimodal machine chain framework with image generation (IG) and investigate the possibility of augmenting image data for ASR and TTS using single-loop and dual-loop architectures on multispeaker natural speech data. Experimental results revealed that both single-loop and dual-loop multimodal chain frameworks enabled ASR and TTS to improve their performance using an image-only dataset.
From Speech Chain to Multimodal Chain: Leveraging Cross-modal Data Augmentation for Semi-supervised Learning
Jun 03, 2019


The most common way for humans to communicate is by speech. But perhaps a language system cannot know what it is communicating without a connection to the real world by image perception. In fact, humans perceive these multiple sources of information together to build a general concept. However, constructing a machine that can alleviate these modalities together in a supervised learning fashion is difficult, because a parallel dataset is required among speech, image, and text modalities altogether that is often unavailable. A machine speech chain based on sequence-to-sequence deep learning was previously proposed to achieve semi-supervised learning that enabled automatic speech recognition (ASR) and text-to-speech synthesis (TTS) to teach each other when they receive unpaired data. In this research, we take a further step by expanding the speech chain into a multimodal chain and design a closely knit chain architecture that connects ASR, TTS, image captioning (IC), and image retrieval (IR) models into a single framework. ASR, TTS, IC, and IR components can be trained in a semi-supervised fashion by assisting each other given incomplete datasets and leveraging cross-modal data augmentation within the chain.