 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Speech Chain to Multimodal Chain: Leveraging Cross-modal Data Augmentation for Semi-supervised Learning
Paper and Code
Jun 03, 2019


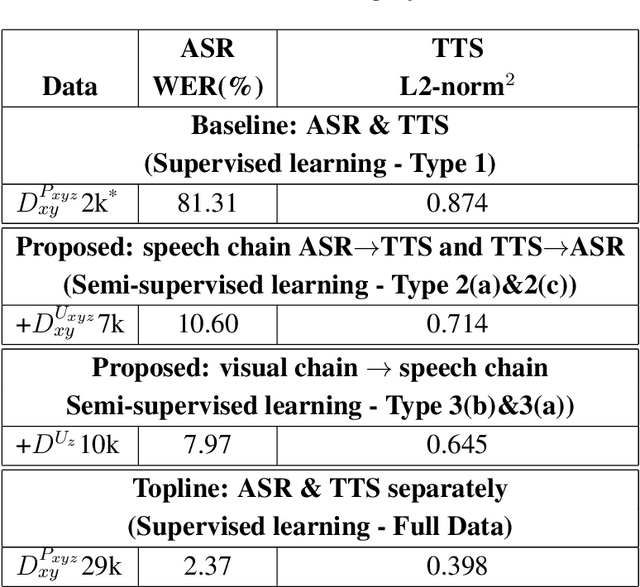
The most common way for humans to communicate is by speech. But perhaps a language system cannot know what it is communicating without a connection to the real world by image perception. In fact, humans perceive these multiple sources of information together to build a general concept. However, constructing a machine that can alleviate these modalities together in a supervised learning fashion is difficult, because a parallel dataset is required among speech, image, and text modalities altogether that is often unavailable. A machine speech chain based on sequence-to-sequence deep learning was previously proposed to achieve semi-supervised learning that enabled automatic speech recognition (ASR) and text-to-speech synthesis (TTS) to teach each other when they receive unpaired data. In this research, we take a further step by expanding the speech chain into a multimodal chain and design a closely knit chain architecture that connects ASR, TTS, image captioning (IC), and image retrieval (IR) models into a single framework. ASR, TTS, IC, and IR components can be trained in a semi-supervised fashion by assisting each other given incomplete datasets and leveraging cross-modal data augmentation within the chain.