 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
A Simple Recipe for Contrastively Pre-training Video-First Encoders Beyond 16 Frames
Dec 12, 2023



Understanding long, real-world videos requires modeling of long-range visual dependencies. To this end, we explore video-first architectures, building on the common paradigm of transferring large-scale, image--text models to video via shallow temporal fusion. However, we expose two limitations to the approach: (1) decreased spatial capabilities, likely due to poor video--language alignment in standard video datasets, and (2) higher memory consumption, bottlenecking the number of frames that can be processed. To mitigate the memory bottleneck, we systematically analyze the memory/accuracy trade-off of various efficient methods: factorized attention, parameter-efficient image-to-video adaptation, input masking, and multi-resolution patchification. Surprisingly, simply masking large portions of the video (up to 75%) during contrastive pre-training proves to be one of the most robust ways to scale encoders to videos up to 4.3 minutes at 1 FPS. Our simple approach for training long video-to-text models, which scales to 1B parameters, does not add new architectural complexity and is able to outperform the popular paradigm of using much larger LLMs as an information aggregator over segment-based information on benchmarks with long-range temporal dependencies (YouCook2, EgoSchema).
Perception Test: A Diagnostic Benchmark for Multimodal Video Models
May 23, 2023


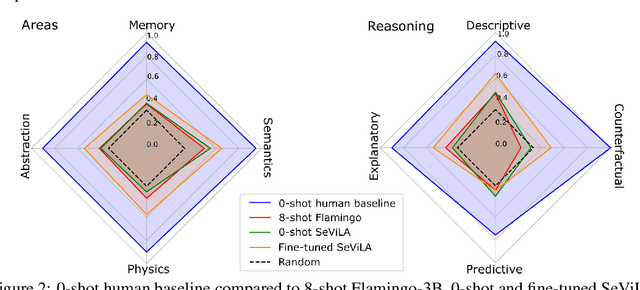
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, BEiT-3, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a significant gap in performance (91.4% vs 43.6%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baselines code, and challenge server are available at https://github.com/deepmind/perception_test
Making the Most of What You Have: Adapting Pre-trained Visual Language Models in the Low-data Regime
May 03, 2023



Large-scale visual language models are widely used as pre-trained models and then adapted for various downstream tasks. While humans are known to efficiently learn new tasks from a few examples, deep learning models struggle with adaptation from few examples. In this work, we look into task adaptation in the low-data regime, and provide a thorough study of the existing adaptation methods for generative Visual Language Models. And we show important benefits of self-labelling, i.e. using the model's own predictions to self-improve when having access to a larger number of unlabelled images of the same distribution. Our study demonstrates significant gains using our proposed task adaptation pipeline across a wide range of visual language tasks such as visual classification (ImageNet), visual captioning (COCO), detailed visual captioning (Localised Narratives) and visual question answering (VQAv2).
Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
Mar 21, 2023



In this work, we introduce Vid2Seq, a multi-modal single-stage dense event captioning model pretrained on narrated videos which are readily-available at scale. The Vid2Seq architecture augments a language model with special time tokens, allowing it to seamlessly predict event boundaries and textual descriptions in the same output sequence. Such a unified model requires large-scale training data, which is not available in current annotated datasets. We show that it is possible to leverage unlabeled narrated videos for dense video captioning, by reformulating sentence boundaries of transcribed speech as pseudo event boundaries, and using the transcribed speech sentences as pseudo event captions. The resulting Vid2Seq model pretrained on the YT-Temporal-1B dataset improves the state of the art on a variety of dense video captioning benchmarks including YouCook2, ViTT and ActivityNet Captions. Vid2Seq also generalizes well to the tasks of video paragraph captioning and video clip captioning, and to few-shot settings. Our code is publicly available at https://antoyang.github.io/vid2seq.html.
Zorro: the masked multimodal transformer
Jan 23, 2023



Attention-based models are appealing for multimodal processing because inputs from multiple modalities can be concatenated and fed to a single backbone network - thus requiring very little fusion engineering. The resulting representations are however fully entangled throughout the network, which may not always be desirable: in learning, contrastive audio-visual self-supervised learning requires independent audio and visual features to operate, otherwise learning collapses; in inference, evaluation of audio-visual models should be possible on benchmarks having just audio or just video. In this paper, we introduce Zorro, a technique that uses masks to control how inputs from each modality are routed inside Transformers, keeping some parts of the representation modality-pure. We apply this technique to three popular transformer-based architectures (ViT, Swin and HiP) and show that with contrastive pre-training Zorro achieves state-of-the-art results on most relevant benchmarks for multimodal tasks (AudioSet and VGGSound). Furthermore, the resulting models are able to perform unimodal inference on both video and audio benchmarks such as Kinetics-400 or ESC-50.
Multi-Task Learning of Object State Changes from Uncurated Videos
Nov 24, 2022



We aim to learn to temporally localize object state changes and the corresponding state-modifying actions by observing people interacting with objects in long uncurated web videos. We introduce three principal contributions. First, we explore alternative multi-task network architectures and identify a model that enables efficient joint learning of multiple object states and actions such as pouring water and pouring coffee. Second, we design a multi-task self-supervised learning procedure that exploits different types of constraints between objects and state-modifying actions enabling end-to-end training of a model for temporal localization of object states and actions in videos from only noisy video-level supervision. Third, we report results on the large-scale ChangeIt and COIN datasets containing tens of thousands of long (un)curated web videos depicting various interactions such as hole drilling, cream whisking, or paper plane folding. We show that our multi-task model achieves a relative improvement of 40% over the prior single-task methods and significantly outperforms both image-based and video-based zero-shot models for this problem. We also test our method on long egocentric videos of the EPIC-KITCHENS and the Ego4D datasets in a zero-shot setup demonstrating the robustness of our learned model.
Zero-Shot Video Question Answering via Frozen Bidirectional Language Models
Jun 16, 2022

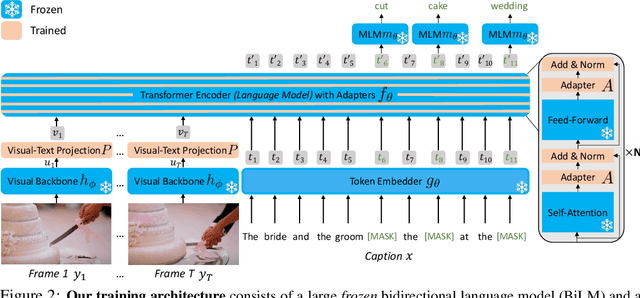

Video question answering (VideoQA) is a complex task that requires diverse multi-modal data for training. Manual annotation of question and answers for videos, however, is tedious and prohibits scalability. To tackle this problem, recent methods consider zero-shot settings with no manual annotation of visual question-answer. In particular, a promising approach adapts frozen autoregressive language models pretrained on Web-scale text-only data to multi-modal inputs. In contrast, we here build on frozen bidirectional language models (BiLM) and show that such an approach provides a stronger and cheaper alternative for zero-shot VideoQA. In particular, (i) we combine visual inputs with the frozen BiLM using light trainable modules, (ii) we train such modules using Web-scraped multi-modal data, and finally (iii) we perform zero-shot VideoQA inference through masked language modeling, where the masked text is the answer to a given question. Our proposed approach, FrozenBiLM, outperforms the state of the art in zero-shot VideoQA by a significant margin on a variety of datasets, including LSMDC-FiB, iVQA, MSRVTT-QA, MSVD-QA, ActivityNet-QA, TGIF-FrameQA, How2QA and TVQA. It also demonstrates competitive performance in the few-shot and fully-supervised setting. Our code and models will be made publicly available at https://antoyang.github.io/frozenbilm.html.