 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScreenAI: A Vision-Language Model for UI and Infographics Understanding
Feb 19, 2024



Screen user interfaces (UIs) and infographics, sharing similar visual language and design principles, play important roles in human communication and human-machine interaction. We introduce ScreenAI, a vision-language model that specializes in UI and infographics understanding. Our model improves upon the PaLI architecture with the flexible patching strategy of pix2struct and is trained on a unique mixture of datasets. At the heart of this mixture is a novel screen annotation task in which the model has to identify the type and location of UI elements. We use these text annotations to describe screens to Large Language Models and automatically generate question-answering (QA), UI navigation, and summarization training datasets at scale. We run ablation studies to demonstrate the impact of these design choices. At only 5B parameters, ScreenAI achieves new state-of-the-artresults on UI- and infographics-based tasks (Multi-page DocVQA, WebSRC, MoTIF and Widget Captioning), and new best-in-class performance on others (Chart QA, DocVQA, and InfographicVQA) compared to models of similar size. Finally, we release three new datasets: one focused on the screen annotation task and two others focused on question answering.
Explore, Establish, Exploit: Red Teaming Language Models from Scratch
Jun 21, 2023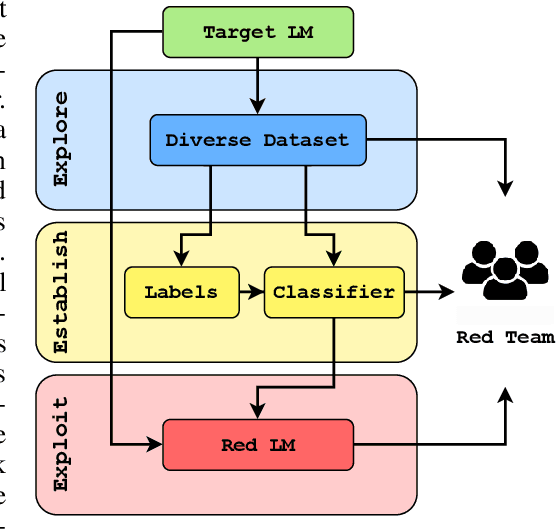

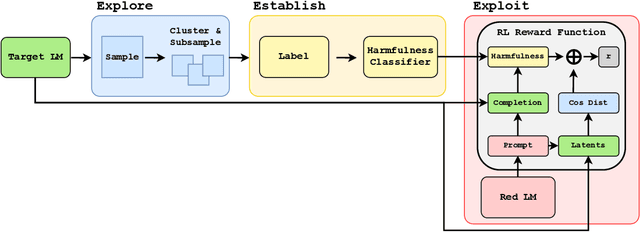

Deploying Large language models (LLMs) can pose hazards from harmful outputs such as toxic or dishonest speech. Prior work has introduced tools that elicit harmful outputs in order to identify and mitigate these risks. While this is a valuable step toward securing language models, these approaches typically rely on a pre-existing classifier for undesired outputs. This limits their application to situations where the type of harmful behavior is known with precision beforehand. However, this skips a central challenge of red teaming: developing a contextual understanding of the behaviors that a model can exhibit. Furthermore, when such a classifier already exists, red teaming has limited marginal value because the classifier could simply be used to filter training data or model outputs. In this work, we consider red teaming under the assumption that the adversary is working from a high-level, abstract specification of undesired behavior. The red team is expected to refine/extend this specification and identify methods to elicit this behavior from the model. Our red teaming framework consists of three steps: 1) Exploring the model's behavior in the desired context; 2) Establishing a measurement of undesired behavior (e.g., a classifier trained to reflect human evaluations); and 3) Exploiting the model's flaws using this measure and an established red teaming methodology. We apply this approach to red team GPT-2 and GPT-3 models to systematically discover classes of prompts that elicit toxic and dishonest statements. In doing so, we also construct and release the CommonClaim dataset of 20,000 statements that have been labeled by human subjects as common-knowledge-true, common-knowledge-false, or neither. Code is available at https://github.com/thestephencasper/explore_establish_exploit_llms. CommonClaim is available at https://github.com/Algorithmic-Alignment-Lab/CommonClaim.
Zorro: the masked multimodal transformer
Jan 23, 2023



Attention-based models are appealing for multimodal processing because inputs from multiple modalities can be concatenated and fed to a single backbone network - thus requiring very little fusion engineering. The resulting representations are however fully entangled throughout the network, which may not always be desirable: in learning, contrastive audio-visual self-supervised learning requires independent audio and visual features to operate, otherwise learning collapses; in inference, evaluation of audio-visual models should be possible on benchmarks having just audio or just video. In this paper, we introduce Zorro, a technique that uses masks to control how inputs from each modality are routed inside Transformers, keeping some parts of the representation modality-pure. We apply this technique to three popular transformer-based architectures (ViT, Swin and HiP) and show that with contrastive pre-training Zorro achieves state-of-the-art results on most relevant benchmarks for multimodal tasks (AudioSet and VGGSound). Furthermore, the resulting models are able to perform unimodal inference on both video and audio benchmarks such as Kinetics-400 or ESC-50.
Interactive Classification for Deep Learning Interpretation
Jun 14, 2018
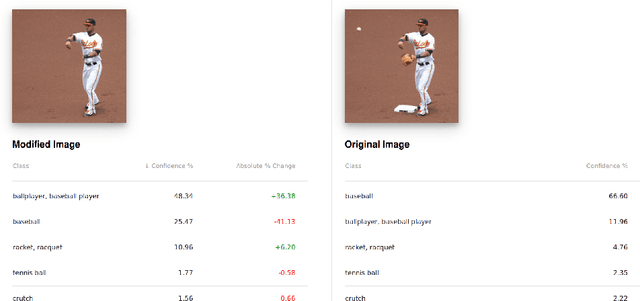
We present an interactive system enabling users to manipulate images to explore the robustness and sensitivity of deep learning image classifiers. Using modern web technologies to run in-browser inference, users can remove image features using inpainting algorithms and obtain new classifications in real time, which allows them to ask a variety of "what if" questions by experimentally modifying images and seeing how the model reacts. Our system allows users to compare and contrast what image regions humans and machine learning models use for classification, revealing a wide range of surprising results ranging from spectacular failures (e.g., a "water bottle" image becomes a "concert" when removing a person) to impressive resilience (e.g., a "baseball player" image remains correctly classified even without a glove or base). We demonstrate our system at The 2018 Conference on Computer Vision and Pattern Recognition (CVPR) for the audience to try it live. Our system is open-sourced at https://github.com/poloclub/interactive-classification. A video demo is available at https://youtu.be/llub5GcOF6w.