 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Document Derendering: SVG Reconstruction via Vision-Language Modeling
Nov 17, 2025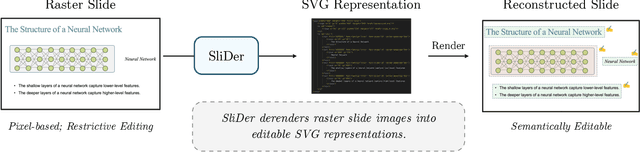
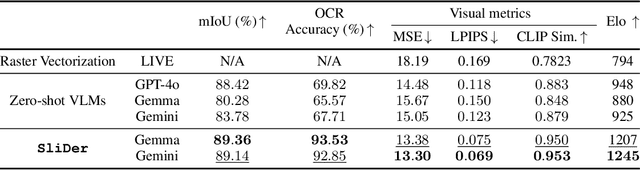
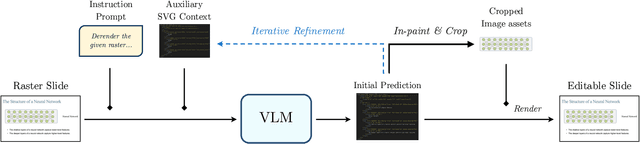
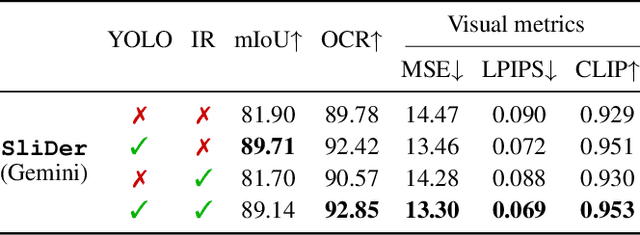
Multimedia documents such as slide presentations and posters are designed to be interactive and easy to modify. Yet, they are often distributed in a static raster format, which limits editing and customization. Restoring their editability requires converting these raster images back into structured vector formats. However, existing geometric raster-vectorization methods, which rely on low-level primitives like curves and polygons, fall short at this task. Specifically, when applied to complex documents like slides, they fail to preserve the high-level structure, resulting in a flat collection of shapes where the semantic distinction between image and text elements is lost. To overcome this limitation, we address the problem of semantic document derendering by introducing SliDer, a novel framework that uses Vision-Language Models (VLMs) to derender slide images as compact and editable Scalable Vector Graphic (SVG) representations. SliDer detects and extracts attributes from individual image and text elements in a raster input and organizes them into a coherent SVG format. Crucially, the model iteratively refines its predictions during inference in a process analogous to human design, generating SVG code that more faithfully reconstructs the original raster upon rendering. Furthermore, we introduce Slide2SVG, a novel dataset comprising raster-SVG pairs of slide documents curated from real-world scientific presentations, to facilitate future research in this domain. Our results demonstrate that SliDer achieves a reconstruction LPIPS of 0.069 and is favored by human evaluators in 82.9% of cases compared to the strongest zero-shot VLM baseline.
Chart-based Reasoning: Transferring Capabilities from LLMs to VLMs
Mar 19, 2024



Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of large-language models (LLMs) have seen numerous improvements. We propose a technique to transfer capabilities from LLMs to VLMs. On the recently introduced ChartQA, our method obtains state-of-the-art performance when applied on the PaLI3-5B VLM by \citet{chen2023pali3}, while also enabling much better performance on PlotQA and FigureQA. We first improve the chart representation by continuing the pre-training stage using an improved version of the chart-to-table translation task by \citet{liu2023deplot}. We then propose constructing a 20x larger dataset than the original training set. To improve general reasoning capabilities and improve numerical operations, we synthesize reasoning traces using the table representation of charts. Lastly, our model is fine-tuned using the multitask loss introduced by \citet{hsieh2023distilling}. Our variant ChartPaLI-5B outperforms even 10x larger models such as PaLIX-55B without using an upstream OCR system, while keeping inference time constant compared to the PaLI3-5B baseline. When rationales are further refined with a simple program-of-thought prompt \cite{chen2023program}, our model outperforms the recently introduced Gemini Ultra and GPT-4V.
ScreenAI: A Vision-Language Model for UI and Infographics Understanding
Feb 19, 2024



Screen user interfaces (UIs) and infographics, sharing similar visual language and design principles, play important roles in human communication and human-machine interaction. We introduce ScreenAI, a vision-language model that specializes in UI and infographics understanding. Our model improves upon the PaLI architecture with the flexible patching strategy of pix2struct and is trained on a unique mixture of datasets. At the heart of this mixture is a novel screen annotation task in which the model has to identify the type and location of UI elements. We use these text annotations to describe screens to Large Language Models and automatically generate question-answering (QA), UI navigation, and summarization training datasets at scale. We run ablation studies to demonstrate the impact of these design choices. At only 5B parameters, ScreenAI achieves new state-of-the-artresults on UI- and infographics-based tasks (Multi-page DocVQA, WebSRC, MoTIF and Widget Captioning), and new best-in-class performance on others (Chart QA, DocVQA, and InfographicVQA) compared to models of similar size. Finally, we release three new datasets: one focused on the screen annotation task and two others focused on question answering.
Towards Better Semantic Understanding of Mobile Interfaces
Oct 06, 2022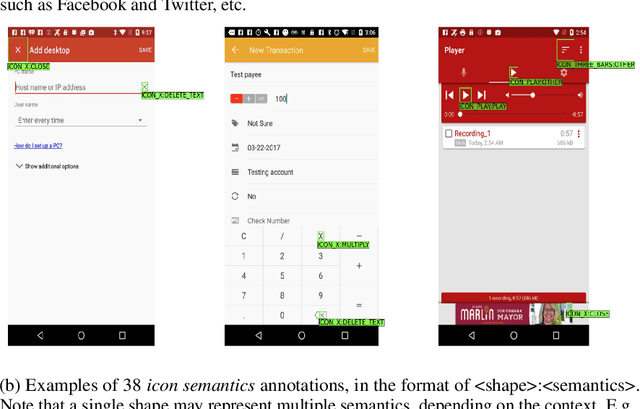

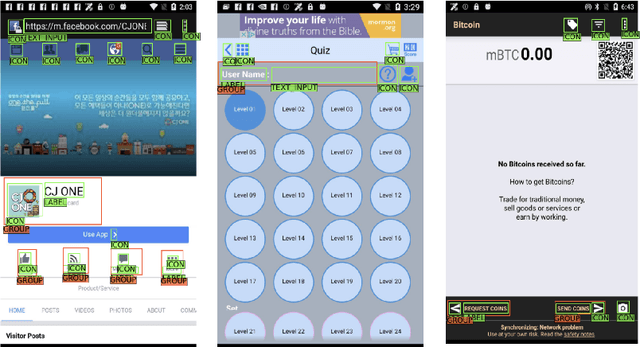

Improving the accessibility and automation capabilities of mobile devices can have a significant positive impact on the daily lives of countless users. To stimulate research in this direction, we release a human-annotated dataset with approximately 500k unique annotations aimed at increasing the understanding of the functionality of UI elements. This dataset augments images and view hierarchies from RICO, a large dataset of mobile UIs, with annotations for icons based on their shapes and semantics, and associations between different elements and their corresponding text labels, resulting in a significant increase in the number of UI elements and the categories assigned to them. We also release models using image-only and multimodal inputs; we experiment with various architectures and study the benefits of using multimodal inputs on the new dataset. Our models demonstrate strong performance on an evaluation set of unseen apps, indicating their generalizability to newer screens. These models, combined with the new dataset, can enable innovative functionalities like referring to UI elements by their labels, improved coverage and better semantics for icons etc., which would go a long way in making UIs more usable for everyone.
Lippmann Photography: A Signal Processing Perspective
Jul 13, 2022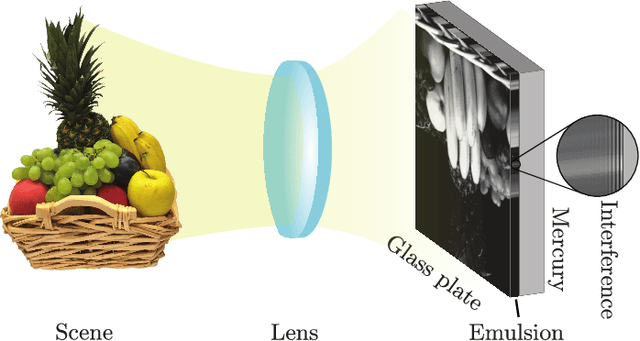

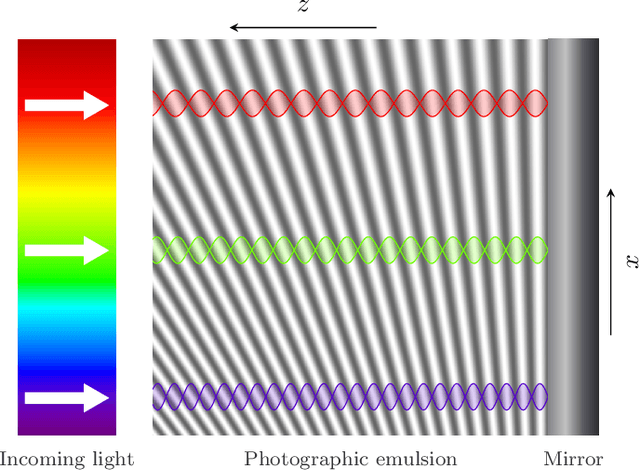
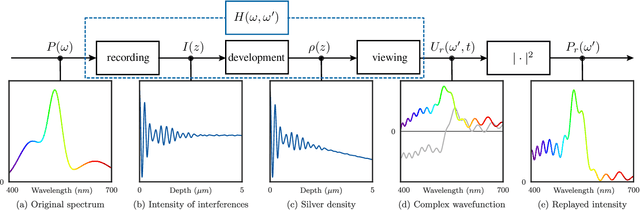
Lippmann (or interferential) photography is the first and only analog photography method that can capture the full color spectrum of a scene in a single take. This technique, invented more than a hundred years ago, records the colors by creating interference patterns inside the photosensitive plate. Lippmann photography provides a great opportunity to demonstrate several fundamental concepts in signal processing. Conversely, a signal processing perspective enables us to shed new light on the technique. In our previous work, we analyzed the spectra of historical Lippmann plates using our own mathematical model. In this paper, we provide the derivation of this model and validate it experimentally. We highlight new behaviors whose explanations were ignored by physicists to date. In particular, we show that the spectra generated by Lippmann plates are in fact distorted versions of the original spectra. We also show that these distortions are influenced by the thickness of the plate and the reflection coefficient of the reflective medium used in the capture of the photographs. We verify our model with extensive experiments on our own Lippmann photographs.
Learning to Denoise Raw Mobile UI Layouts for Improving Datasets at Scale
Jan 13, 2022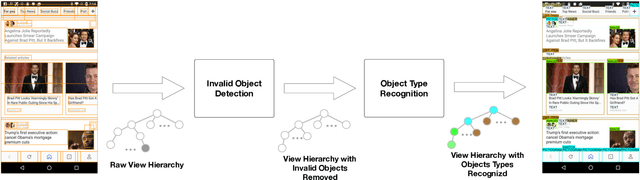
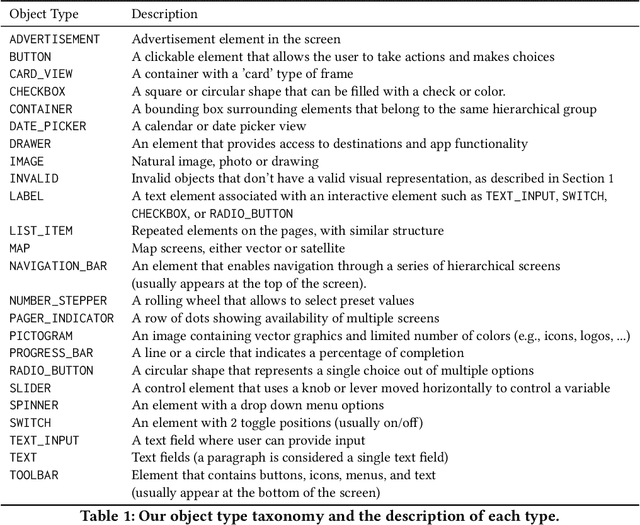
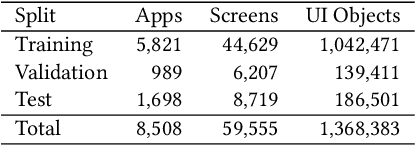
The layout of a mobile screen is a critical data source for UI design research and semantic understanding of the screen. However, UI layouts in existing datasets are often noisy, have mismatches with their visual representation, or consists of generic or app-specific types that are difficult to analyze and model. In this paper, we propose the CLAY pipeline that uses a deep learning approach for denoising UI layouts, allowing us to automatically improve existing mobile UI layout datasets at scale. Our pipeline takes both the screenshot and the raw UI layout, and annotates the raw layout by removing incorrect nodes and assigning a semantically meaningful type to each node. To experiment with our data-cleaning pipeline, we create the CLAY dataset of 59,555 human-annotated screen layouts, based on screenshots and raw layouts from Rico, a public mobile UI corpus. Our deep models achieve high accuracy with F1 scores of 82.7% for detecting layout objects that do not have a valid visual representation and 85.9% for recognizing object types, which significantly outperforms a heuristic baseline. Our work lays a foundation for creating large-scale high quality UI layout datasets for data-driven mobile UI research and reduces the need of manual labeling efforts that are prohibitively expensive.
Embedded polarizing filters to separate diffuse and specular reflection
Nov 06, 2018



Polarizing filters provide a powerful way to separate diffuse and specular reflection; however, traditional methods rely on several captures and require proper alignment of the filters. Recently, camera manufacturers have proposed to embed polarizing micro-filters in front of the sensor, creating a mosaic of pixels with different polarizations. In this paper, we investigate the advantages of such camera designs. In particular, we consider different design patterns for the filter arrays and propose an algorithm to demosaic an image generated by such cameras. This essentially allows us to separate the diffuse and specular components using a single image. The performance of our algorithm is compared with a color-based method using synthetic and real data. Finally, we demonstrate how we can recover the normals of a scene using the diffuse images estimated by our method.