 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust and Generalizable Lensless Imaging with Modular Learned Reconstruction
Feb 03, 2025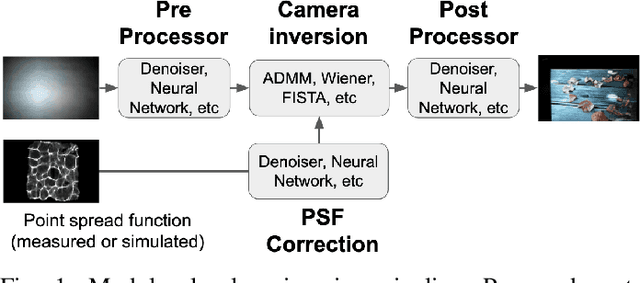



Lensless cameras disregard the conventional design that imaging should mimic the human eye. This is done by replacing the lens with a thin mask, and moving image formation to the digital post-processing. State-of-the-art lensless imaging techniques use learned approaches that combine physical modeling and neural networks. However, these approaches make simplifying modeling assumptions for ease of calibration and computation. Moreover, the generalizability of learned approaches to lensless measurements of new masks has not been studied. To this end, we utilize a modular learned reconstruction in which a key component is a pre-processor prior to image recovery. We theoretically demonstrate the pre-processor's necessity for standard image recovery techniques (Wiener filtering and iterative algorithms), and through extensive experiments show its effectiveness for multiple lensless imaging approaches and across datasets of different mask types (amplitude and phase). We also perform the first generalization benchmark across mask types to evaluate how well reconstructions trained with one system generalize to others. Our modular reconstruction enables us to use pre-trained components and transfer learning on new systems to cut down weeks of tedious measurements and training. As part of our work, we open-source four datasets, and software for measuring datasets and for training our modular reconstruction.
Let There Be Light: Robust Lensless Imaging Under External Illumination With Deep Learning
Sep 25, 2024Lensless cameras relax the design constraints of traditional cameras by shifting image formation from analog optics to digital post-processing. While new camera designs and applications can be enabled, lensless imaging is very sensitive to unwanted interference (other sources, noise, etc.). In this work, we address a prevalent noise source that has not been studied for lensless imaging: external illumination e.g. from ambient and direct lighting. Being robust to a variety of lighting conditions would increase the practicality and adoption of lensless imaging. To this end, we propose multiple recovery approaches that account for external illumination by incorporating its estimate into the image recovery process. At the core is a physics-based reconstruction that combines learnable image recovery and denoisers, all of whose parameters are trained using experimentally gathered data. Compared to standard reconstruction methods, our approach yields significant qualitative and quantitative improvements. We open-source our implementations and a 25K dataset of measurements under multiple lighting conditions.
A Modular and Robust Physics-Based Approach for Lensless Image Reconstruction
Mar 01, 2024



In this paper, we present a modular approach for reconstructing lensless measurements. It consists of three components: a newly-proposed pre-processor, a physics-based camera inverter to undo the multiplexing of lensless imaging, and a post-processor. The pre- and post-processors address noise and artifacts unique to lensless imaging before and after camera inversion respectively. By training the three components end-to-end, we obtain a 1.9 dB increase in PSNR and a 14% relative improvement in a perceptual image metric (LPIPS) with respect to previously proposed physics-based methods. We also demonstrate how the proposed pre-processor provides more robustness to input noise, and how an auxiliary loss can improve interpretability.
Blind as a bat: audible echolocation on small robots
Jan 19, 2023
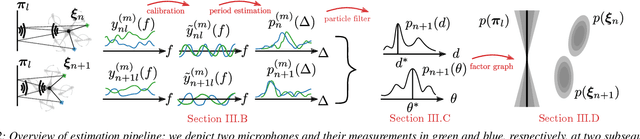
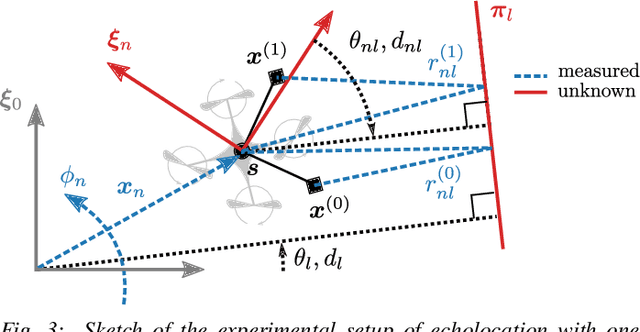
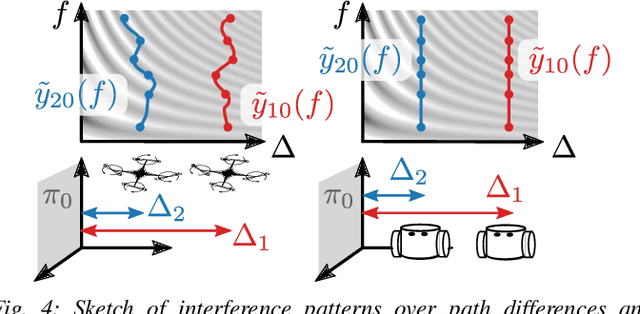
For safe and efficient operation, mobile robots need to perceive their environment, and in particular, perform tasks such as obstacle detection, localization, and mapping. Although robots are often equipped with microphones and speakers, the audio modality is rarely used for these tasks. Compared to the localization of sound sources, for which many practical solutions exist, algorithms for active echolocation are less developed and often rely on hardware requirements that are out of reach for small robots. We propose an end-to-end pipeline for sound-based localization and mapping that is targeted at, but not limited to, robots equipped with only simple buzzers and low-end microphones. The method is model-based, runs in real time, and requires no prior calibration or training. We successfully test the algorithm on the e-puck robot with its integrated audio hardware, and on the Crazyflie drone, for which we design a reproducible audio extension deck. We achieve centimeter-level wall localization on both platforms when the robots are static during the measurement process. Even in the more challenging setting of a flying drone, we can successfully localize walls, which we demonstrate in a proof-of-concept multi-wall localization and mapping demo.
Privacy-Enhancing Optical Embeddings for Lensless Classification
Nov 23, 2022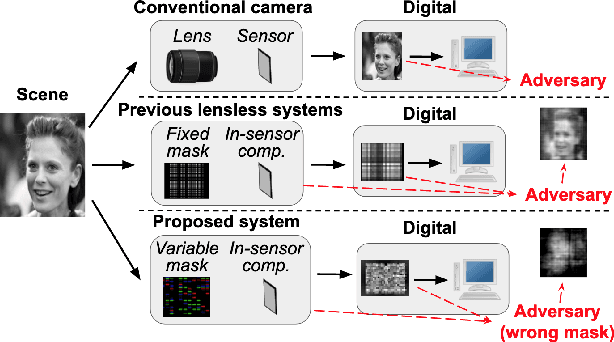
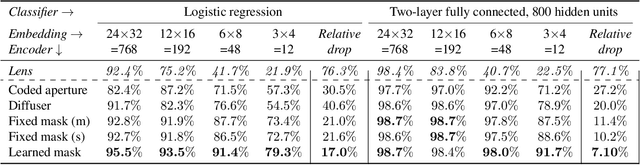
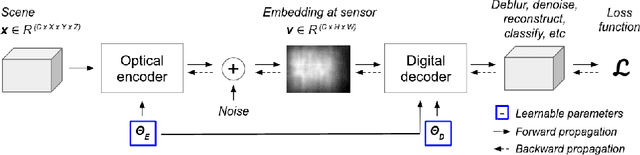
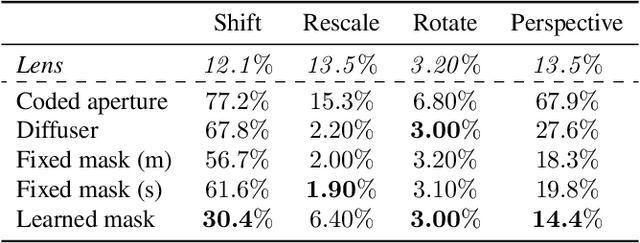
Lensless imaging can provide visual privacy due to the highly multiplexed characteristic of its measurements. However, this alone is a weak form of security, as various adversarial attacks can be designed to invert the one-to-many scene mapping of such cameras. In this work, we enhance the privacy provided by lensless imaging by (1) downsampling at the sensor and (2) using a programmable mask with variable patterns as our optical encoder. We build a prototype from a low-cost LCD and Raspberry Pi components, for a total cost of around 100 USD. This very low price point allows our system to be deployed and leveraged in a broad range of applications. In our experiments, we first demonstrate the viability and reconfigurability of our system by applying it to various classification tasks: MNIST, CelebA (face attributes), and CIFAR10. By jointly optimizing the mask pattern and a digital classifier in an end-to-end fashion, low-dimensional, privacy-enhancing embeddings are learned directly at the sensor. Secondly, we show how the proposed system, through variable mask patterns, can thwart adversaries that attempt to invert the system (1) via plaintext attacks or (2) in the event of camera parameters leaks. We demonstrate the defense of our system to both risks, with 55% and 26% drops in image quality metrics for attacks based on model-based convex optimization and generative neural networks respectively. We open-source a wave propagation and camera simulator needed for end-to-end optimization, the training software, and a library for interfacing with the camera.
Lippmann Photography: A Signal Processing Perspective
Jul 13, 2022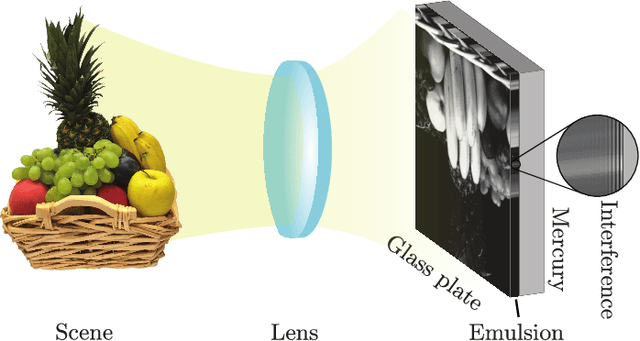

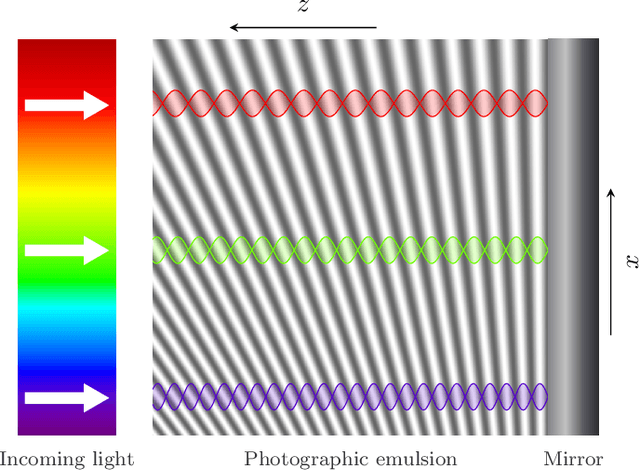
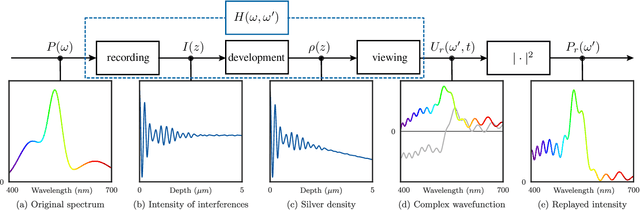
Lippmann (or interferential) photography is the first and only analog photography method that can capture the full color spectrum of a scene in a single take. This technique, invented more than a hundred years ago, records the colors by creating interference patterns inside the photosensitive plate. Lippmann photography provides a great opportunity to demonstrate several fundamental concepts in signal processing. Conversely, a signal processing perspective enables us to shed new light on the technique. In our previous work, we analyzed the spectra of historical Lippmann plates using our own mathematical model. In this paper, we provide the derivation of this model and validate it experimentally. We highlight new behaviors whose explanations were ignored by physicists to date. In particular, we show that the spectra generated by Lippmann plates are in fact distorted versions of the original spectra. We also show that these distortions are influenced by the thickness of the plate and the reflection coefficient of the reflective medium used in the capture of the photographs. We verify our model with extensive experiments on our own Lippmann photographs.
How Asynchronous Events Encode Video
Jun 09, 2022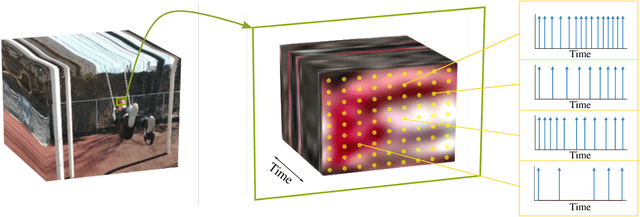
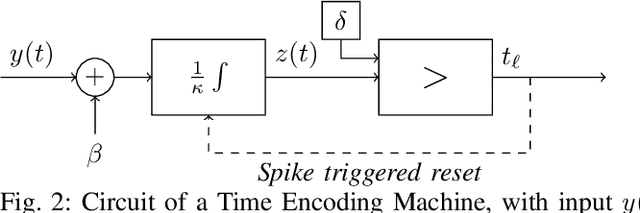
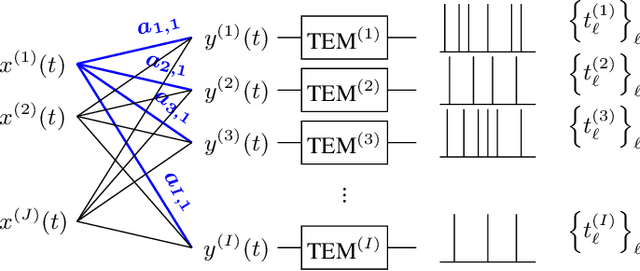
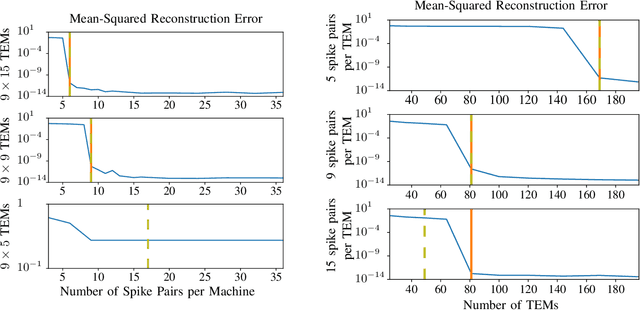
As event-based sensing gains in popularity, theoretical understanding is needed to harness this technology's potential. Instead of recording video by capturing frames, event-based cameras have sensors that emit events when their inputs change, thus encoding information in the timing of events. This creates new challenges in establishing reconstruction guarantees and algorithms, but also provides advantages over frame-based video. We use time encoding machines to model event-based sensors: TEMs also encode their inputs by emitting events characterized by their timing and reconstruction from time encodings is well understood. We consider the case of time encoding bandlimited video and demonstrate a dependence between spatial sensor density and overall spatial and temporal resolution. Such a dependence does not occur in frame-based video, where temporal resolution depends solely on the frame rate of the video and spatial resolution depends solely on the pixel grid. However, this dependence arises naturally in event-based video and allows oversampling in space to provide better time resolution. As such, event-based vision encourages using more sensors that emit fewer events over time.
* 6 pages, 4 figures
LenslessPiCam: A Hardware and Software Platform for Lensless Computational Imaging with a Raspberry Pi
Jun 03, 2022
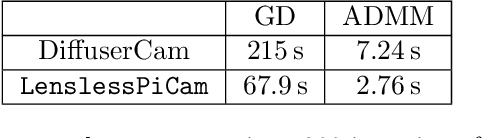


Lensless imaging seeks to replace/remove the lens in a conventional imaging system. The earliest cameras were in fact lensless, relying on long exposure times to form images on the other end of a small aperture in a darkened room/container (camera obscura). The introduction of a lens allowed for more light throughput and therefore shorter exposure times, while retaining sharp focus. The incorporation of digital sensors readily enabled the use of computational imaging techniques to post-process and enhance raw images (e.g. via deblurring, inpainting, denoising, sharpening). Recently, imaging scientists have started leveraging computational imaging as an integral part of lensless imaging systems, allowing them to form viewable images from the highly multiplexed raw measurements of lensless cameras (see [5] and references therein for a comprehensive treatment of lensless imaging). This represents a real paradigm shift in camera system design as there is more flexibility to cater the hardware to the application at hand (e.g. lightweight or flat designs). This increased flexibility comes however at the price of a more demanding post-processing of the raw digital recordings and a tighter integration of sensing and computation, often difficult to achieve in practice due to inefficient interactions between the various communities of scientists involved. With LenslessPiCam, we provide an easily accessible hardware and software framework to enable researchers, hobbyists, and students to implement and explore practical and computational aspects of lensless imaging. We also provide detailed guides and exercises so that LenslessPiCam can be used as an educational resource, and point to results from our graduate-level signal processing course.
Learning rich optical embeddings for privacy-preserving lensless image classification
Jun 03, 2022
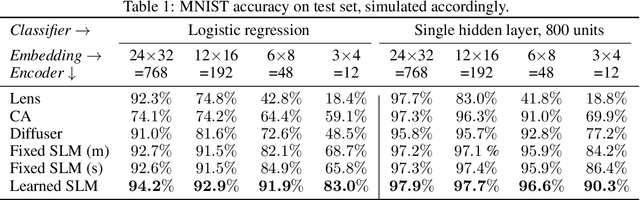
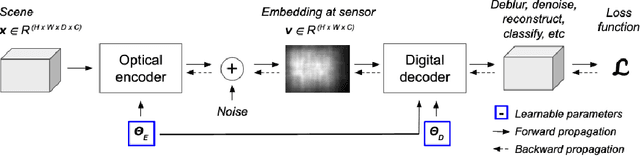

By replacing the lens with a thin optical element, lensless imaging enables new applications and solutions beyond those supported by traditional camera design and post-processing, e.g. compact and lightweight form factors and visual privacy. The latter arises from the highly multiplexed measurements of lensless cameras, which require knowledge of the imaging system to recover a recognizable image. In this work, we exploit this unique multiplexing property: casting the optics as an encoder that produces learned embeddings directly at the camera sensor. We do so in the context of image classification, where we jointly optimize the encoder's parameters and those of an image classifier in an end-to-end fashion. Our experiments show that jointly learning the lensless optical encoder and the digital processing allows for lower resolution embeddings at the sensor, and hence better privacy as it is much harder to recover meaningful images from these measurements. Additional experiments show that such an optimization allows for lensless measurements that are more robust to typical real-world image transformations. While this work focuses on classification, the proposed programmable lensless camera and end-to-end optimization can be applied to other computational imaging tasks.
Asynchrony Increases Efficiency: Time Encoding of Videos and Low-Rank Signals
Apr 29, 2021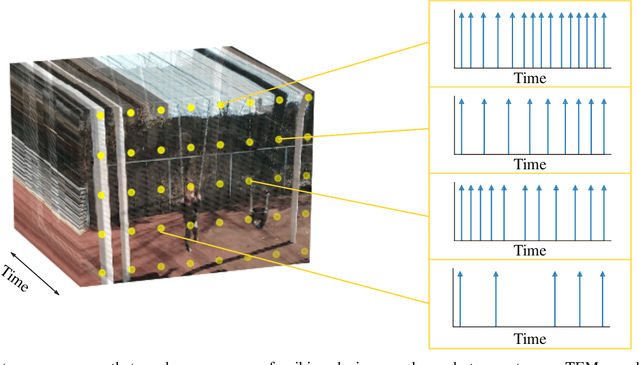
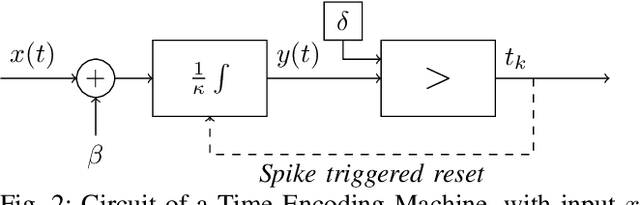
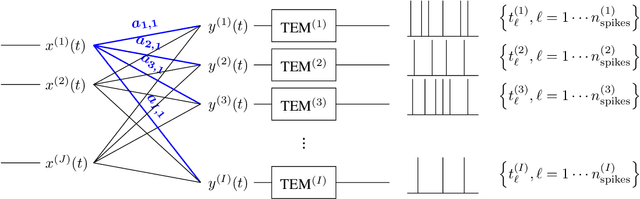
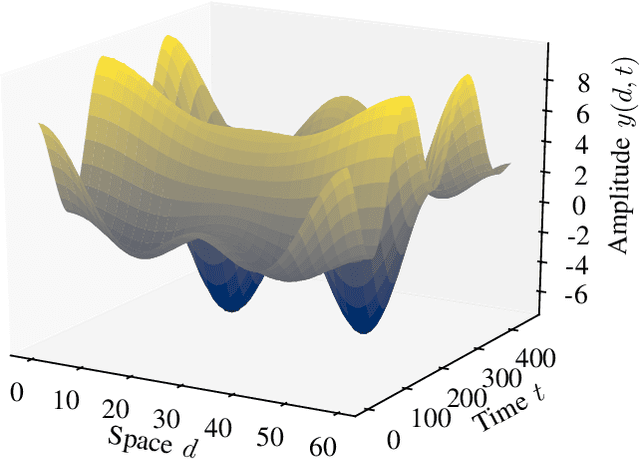
In event-based sensing, many sensors independently and asynchronously emit events when there is a change in their input. Event-based sensing can present significant improvements in power efficiency when compared to traditional sampling, because (1) the output is a stream of events where the important information lies in the timing of the events, and (2) the sensor can easily be controlled to output information only when interesting activity occurs at the input. Moreover, event-based sampling can often provide better resolution than standard uniform sampling. Not only does this occur because individual event-based sensors have higher temporal resolution, it also occurs because the asynchrony of events allows for less redundant and more informative encoding. We would like to explain how such curious results come about. To do so, we use ideal time encoding machines as a proxy for event-based sensors. We explore time encoding of signals with low rank structure, and apply the resulting theory to video. We then see how the asynchronous firing times of the time encoding machines allow for better reconstruction than in the standard sampling case, if we have a high spatial density of time encoding machines that fire less frequently.