 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous SpO2 Monitoring Using Reflectance Pulse Oximetry at the Wrist and Upper Arm During Overnight Sleep Apnea Recordings
May 27, 2025Sleep apnea (SA) is a chronic sleep-related disorder consisting of repetitive pauses or restrictions in airflow during sleep and is known to be a risk factor for cerebro- and cardiovascular disease. It is generally diagnosed using polysomnography (PSG) recorded overnight in an in-lab setting at the hospital. This includes the measurement of blood oxygen saturation (SpO2), which exhibits fluctuations caused by SA events. In this paper, we investigate the accuracy and utility of reflectance pulse oximetry from a wearable device as a means to continuously monitor SpO2 during sleep. To this end, we analyzed data from a cohort of 134 patients with suspected SA undergoing overnight PSG and wearing the watch-like device at two measurement locations (upper arm and wrist). Our data show that standard requirements for pulse oximetry measurements are met at both measurement locations, with an accuracy (root mean squared error) of 1.9% at the upper arm and 3.2% at the wrist. With a rejection rate of 3.1%, the upper arm yielded better results in terms of data quality when compared to the wrist location which had 30.4% of data rejected.
How Asynchronous Events Encode Video
Jun 09, 2022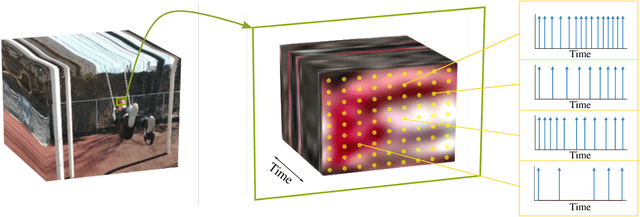
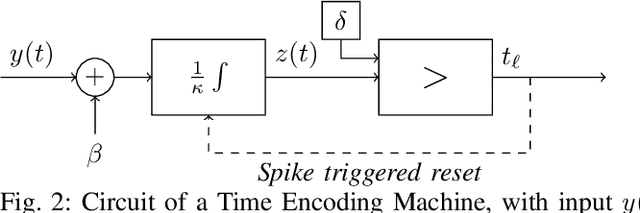
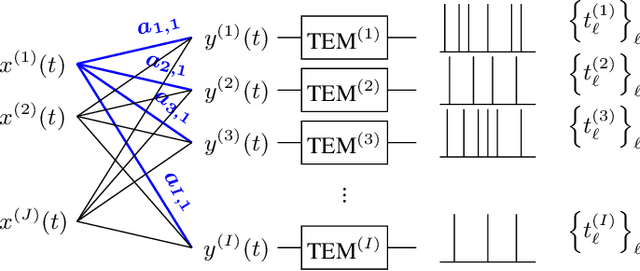
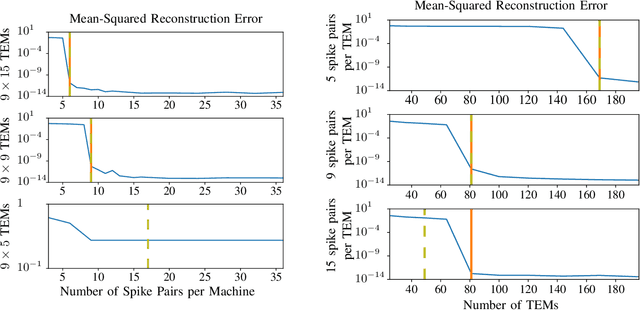
As event-based sensing gains in popularity, theoretical understanding is needed to harness this technology's potential. Instead of recording video by capturing frames, event-based cameras have sensors that emit events when their inputs change, thus encoding information in the timing of events. This creates new challenges in establishing reconstruction guarantees and algorithms, but also provides advantages over frame-based video. We use time encoding machines to model event-based sensors: TEMs also encode their inputs by emitting events characterized by their timing and reconstruction from time encodings is well understood. We consider the case of time encoding bandlimited video and demonstrate a dependence between spatial sensor density and overall spatial and temporal resolution. Such a dependence does not occur in frame-based video, where temporal resolution depends solely on the frame rate of the video and spatial resolution depends solely on the pixel grid. However, this dependence arises naturally in event-based video and allows oversampling in space to provide better time resolution. As such, event-based vision encourages using more sensors that emit fewer events over time.
* 6 pages, 4 figures
A Time Encoding approach to training Spiking Neural Networks
Oct 13, 2021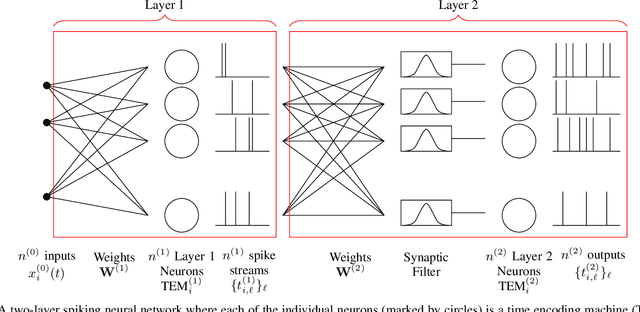


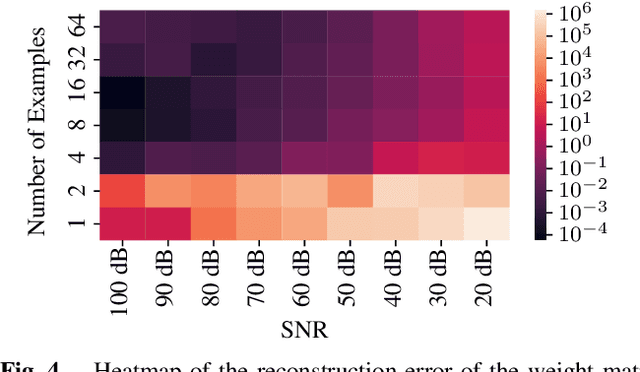
While Spiking Neural Networks (SNNs) have been gaining in popularity, it seems that the algorithms used to train them are not powerful enough to solve the same tasks as those tackled by classical Artificial Neural Networks (ANNs). In this paper, we provide an extra tool to help us understand and train SNNs by using theory from the field of time encoding. Time encoding machines (TEMs) can be used to model integrate-and-fire neurons and have well-understood reconstruction properties. We will see how one can take inspiration from the field of TEMs to interpret the spike times of SNNs as constraints on the SNNs' weight matrices. More specifically, we study how to train one-layer SNNs by solving a set of linear constraints, and how to train two-layer SNNs by leveraging the all-or-none and asynchronous properties of the spikes emitted by SNNs. These properties of spikes result in an alternative to backpropagation which is not possible in the case of simultaneous and graded activations as in classical ANNs.
Asynchrony Increases Efficiency: Time Encoding of Videos and Low-Rank Signals
Apr 29, 2021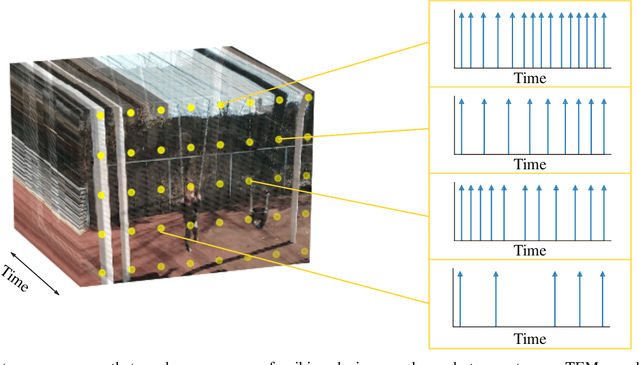
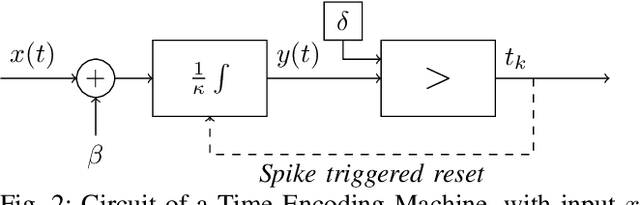
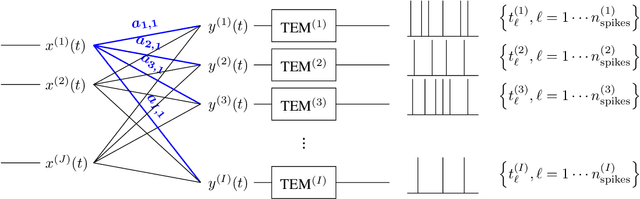
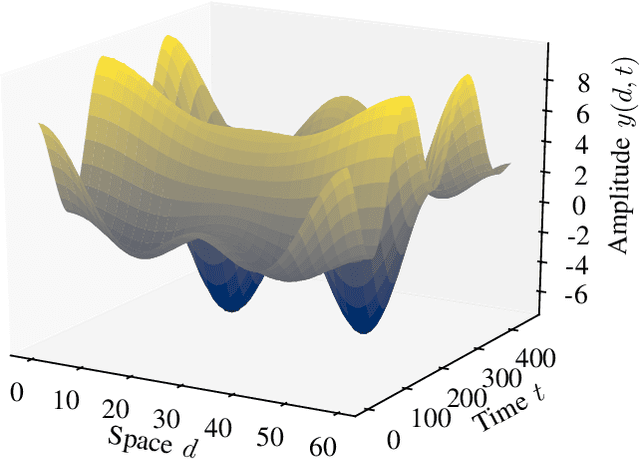
In event-based sensing, many sensors independently and asynchronously emit events when there is a change in their input. Event-based sensing can present significant improvements in power efficiency when compared to traditional sampling, because (1) the output is a stream of events where the important information lies in the timing of the events, and (2) the sensor can easily be controlled to output information only when interesting activity occurs at the input. Moreover, event-based sampling can often provide better resolution than standard uniform sampling. Not only does this occur because individual event-based sensors have higher temporal resolution, it also occurs because the asynchrony of events allows for less redundant and more informative encoding. We would like to explain how such curious results come about. To do so, we use ideal time encoding machines as a proxy for event-based sensors. We explore time encoding of signals with low rank structure, and apply the resulting theory to video. We then see how the asynchronous firing times of the time encoding machines allow for better reconstruction than in the standard sampling case, if we have a high spatial density of time encoding machines that fire less frequently.