 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind as a bat: audible echolocation on small robots
Jan 19, 2023
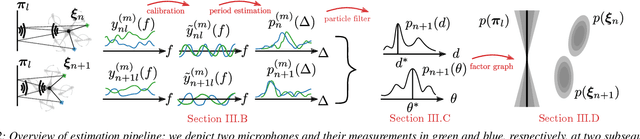
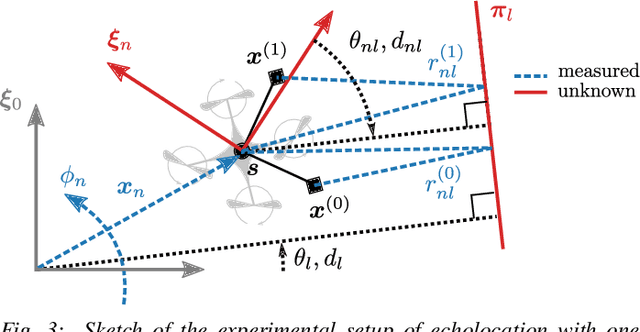
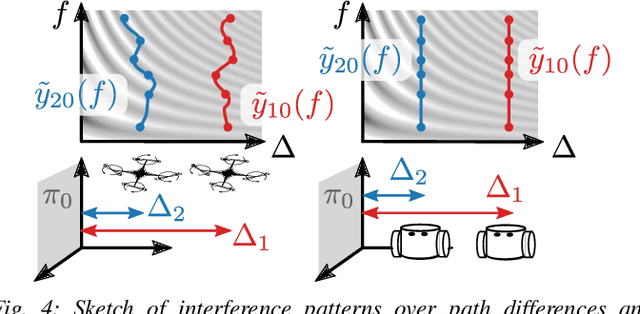
For safe and efficient operation, mobile robots need to perceive their environment, and in particular, perform tasks such as obstacle detection, localization, and mapping. Although robots are often equipped with microphones and speakers, the audio modality is rarely used for these tasks. Compared to the localization of sound sources, for which many practical solutions exist, algorithms for active echolocation are less developed and often rely on hardware requirements that are out of reach for small robots. We propose an end-to-end pipeline for sound-based localization and mapping that is targeted at, but not limited to, robots equipped with only simple buzzers and low-end microphones. The method is model-based, runs in real time, and requires no prior calibration or training. We successfully test the algorithm on the e-puck robot with its integrated audio hardware, and on the Crazyflie drone, for which we design a reproducible audio extension deck. We achieve centimeter-level wall localization on both platforms when the robots are static during the measurement process. Even in the more challenging setting of a flying drone, we can successfully localize walls, which we demonstrate in a proof-of-concept multi-wall localization and mapping demo.
Lippmann Photography: A Signal Processing Perspective
Jul 13, 2022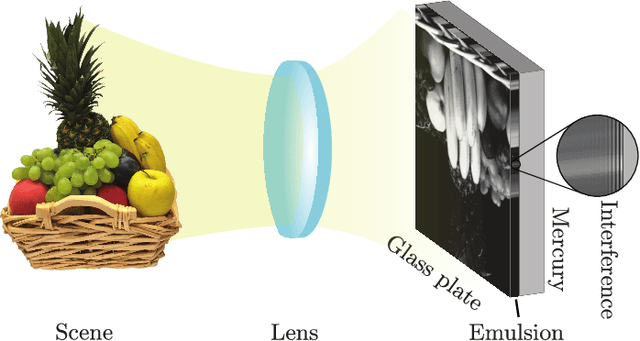

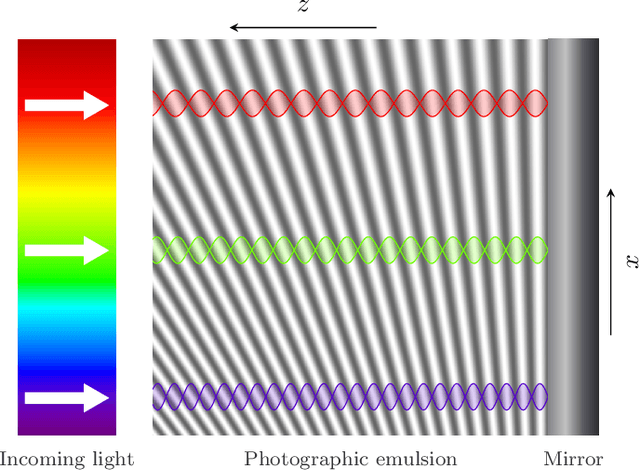
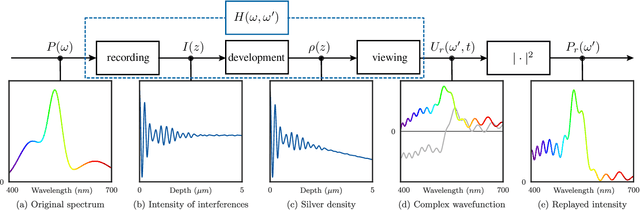
Lippmann (or interferential) photography is the first and only analog photography method that can capture the full color spectrum of a scene in a single take. This technique, invented more than a hundred years ago, records the colors by creating interference patterns inside the photosensitive plate. Lippmann photography provides a great opportunity to demonstrate several fundamental concepts in signal processing. Conversely, a signal processing perspective enables us to shed new light on the technique. In our previous work, we analyzed the spectra of historical Lippmann plates using our own mathematical model. In this paper, we provide the derivation of this model and validate it experimentally. We highlight new behaviors whose explanations were ignored by physicists to date. In particular, we show that the spectra generated by Lippmann plates are in fact distorted versions of the original spectra. We also show that these distortions are influenced by the thickness of the plate and the reflection coefficient of the reflective medium used in the capture of the photographs. We verify our model with extensive experiments on our own Lippmann photographs.
How Asynchronous Events Encode Video
Jun 09, 2022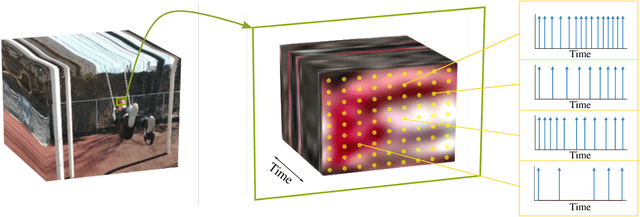
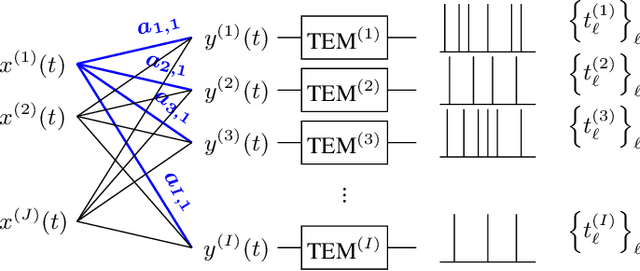
As event-based sensing gains in popularity, theoretical understanding is needed to harness this technology's potential. Instead of recording video by capturing frames, event-based cameras have sensors that emit events when their inputs change, thus encoding information in the timing of events. This creates new challenges in establishing reconstruction guarantees and algorithms, but also provides advantages over frame-based video. We use time encoding machines to model event-based sensors: TEMs also encode their inputs by emitting events characterized by their timing and reconstruction from time encodings is well understood. We consider the case of time encoding bandlimited video and demonstrate a dependence between spatial sensor density and overall spatial and temporal resolution. Such a dependence does not occur in frame-based video, where temporal resolution depends solely on the frame rate of the video and spatial resolution depends solely on the pixel grid. However, this dependence arises naturally in event-based video and allows oversampling in space to provide better time resolution. As such, event-based vision encourages using more sensors that emit fewer events over time.
* 6 pages, 4 figures
Asynchrony Increases Efficiency: Time Encoding of Videos and Low-Rank Signals
Apr 29, 2021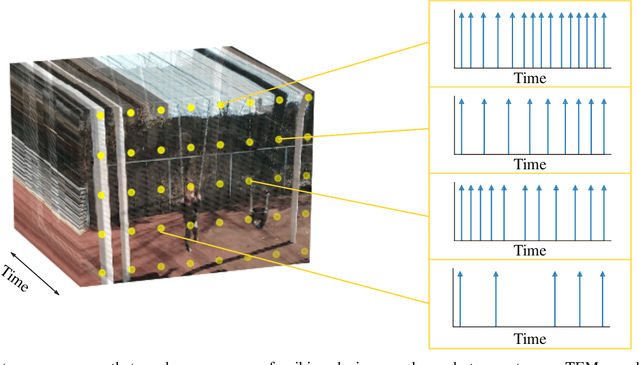
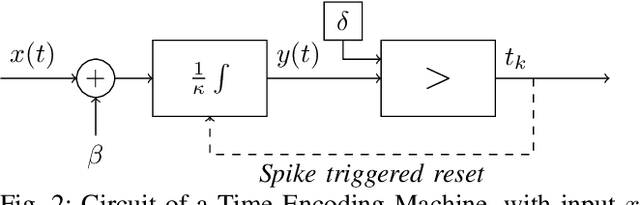
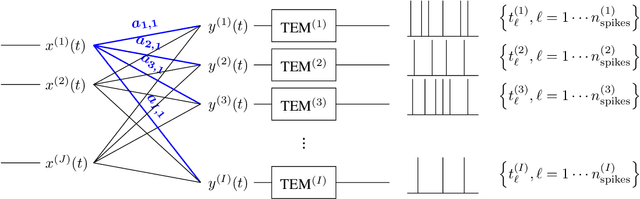
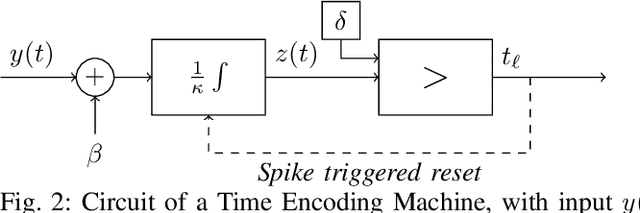
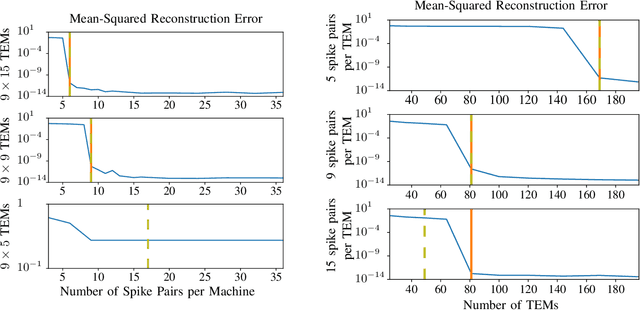
In event-based sensing, many sensors independently and asynchronously emit events when there is a change in their input. Event-based sensing can present significant improvements in power efficiency when compared to traditional sampling, because (1) the output is a stream of events where the important information lies in the timing of the events, and (2) the sensor can easily be controlled to output information only when interesting activity occurs at the input. Moreover, event-based sampling can often provide better resolution than standard uniform sampling. Not only does this occur because individual event-based sensors have higher temporal resolution, it also occurs because the asynchrony of events allows for less redundant and more informative encoding. We would like to explain how such curious results come about. To do so, we use ideal time encoding machines as a proxy for event-based sensors. We explore time encoding of signals with low rank structure, and apply the resulting theory to video. We then see how the asynchronous firing times of the time encoding machines allow for better reconstruction than in the standard sampling case, if we have a high spatial density of time encoding machines that fire less frequently.
Realizability of Planar Point Embeddings from Angle Measurements
May 09, 2020
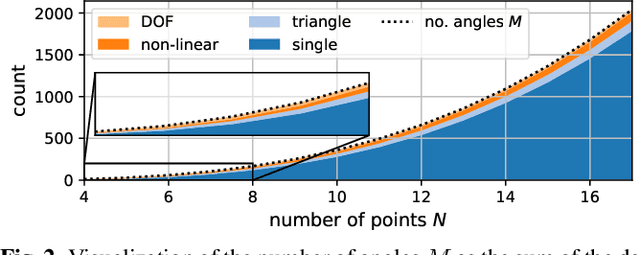
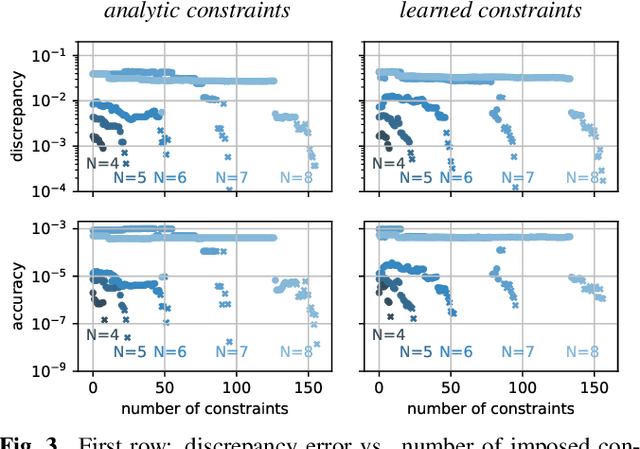
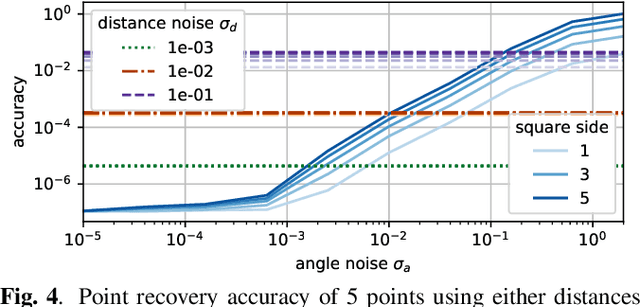
Localization of a set of nodes is an important and a thoroughly researched problem in robotics and sensor networks. This paper is concerned with the theory of localization from inner-angle measurements. We focus on the challenging case where no anchor locations are known. Inspired by Euclidean distance matrices, we investigate when a set of inner angles corresponds to a realizable point set. In particular, we find linear and non-linear constraints that are provably necessary, and we conjecture also sufficient for characterizing realizable angle sets. We confirm this in extensive numerical simulations, and we illustrate the use of these constraints for denoising angle measurements along with the reconstruction of a valid point set.
Embedded polarizing filters to separate diffuse and specular reflection
Nov 06, 2018



Polarizing filters provide a powerful way to separate diffuse and specular reflection; however, traditional methods rely on several captures and require proper alignment of the filters. Recently, camera manufacturers have proposed to embed polarizing micro-filters in front of the sensor, creating a mosaic of pixels with different polarizations. In this paper, we investigate the advantages of such camera designs. In particular, we consider different design patterns for the filter arrays and propose an algorithm to demosaic an image generated by such cameras. This essentially allows us to separate the diffuse and specular components using a single image. The performance of our algorithm is compared with a color-based method using synthetic and real data. Finally, we demonstrate how we can recover the normals of a scene using the diffuse images estimated by our method.
Bound and Conquer: Improving Triangulation by Enforcing Consistency
Apr 27, 2018
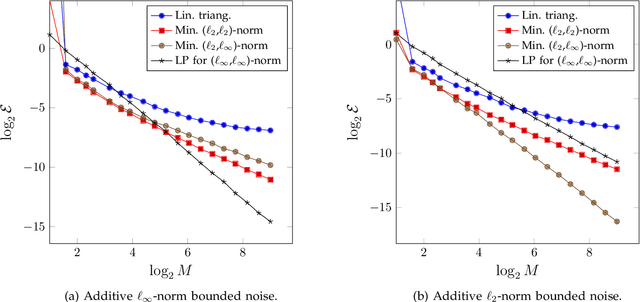

We study the accuracy of triangulation in multi-camera systems with respect to the number of cameras. We show that, under certain conditions, the optimal achievable reconstruction error decays quadratically as more cameras are added to the system. Furthermore, we analyse the error decay-rate of major state-of-the-art algorithms with respect to the number of cameras. To this end, we introduce the notion of consistency for triangulation, and show that consistent reconstruction algorithms achieve the optimal quadratic decay, which is asymptotically faster than some other methods. Finally, we present simulations results supporting our findings. Our simulations have been implemented in MATLAB and the resulting code is available in the supplementary material.
On the Accuracy of Point Localisation in a Circular Camera-Array
Feb 24, 2016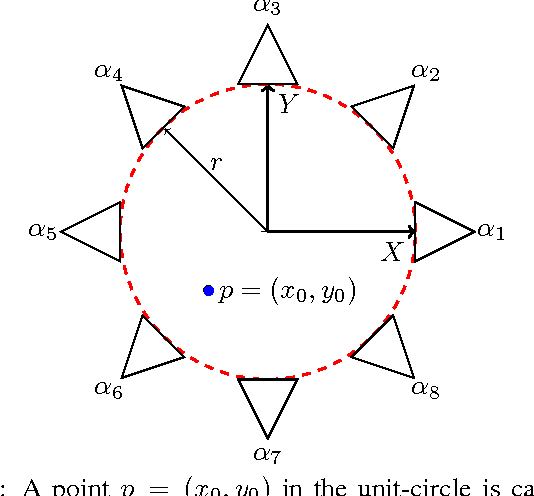
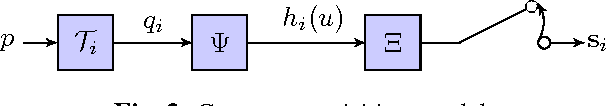
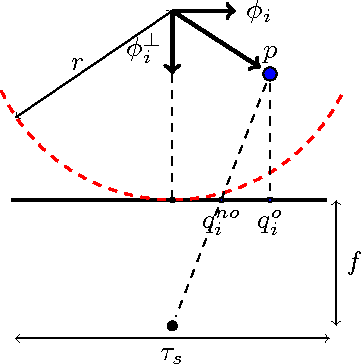
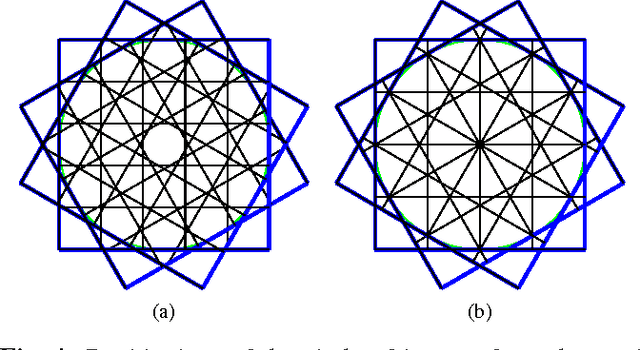
Although many advances have been made in light-field and camera-array image processing, there is still a lack of thorough analysis of the localisation accuracy of different multi-camera systems. By considering the problem from a frame-quantisation perspective, we are able to quantify the point localisation error of circular camera configurations. Specifically, we obtain closed form expressions bounding the localisation error in terms of the parameters describing the acquisition setup. These theoretical results are independent of the localisation algorithm and thus provide fundamental limits on performance. Furthermore, the new frame-quantisation perspective is general enough to be extended to more complex camera configurations.
SHAPE: Linear-Time Camera Pose Estimation With Quadratic Error-Decay
Feb 24, 2016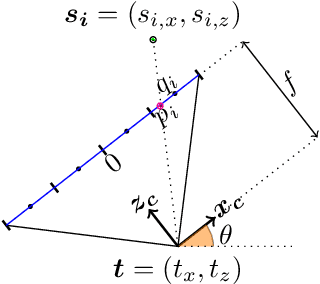
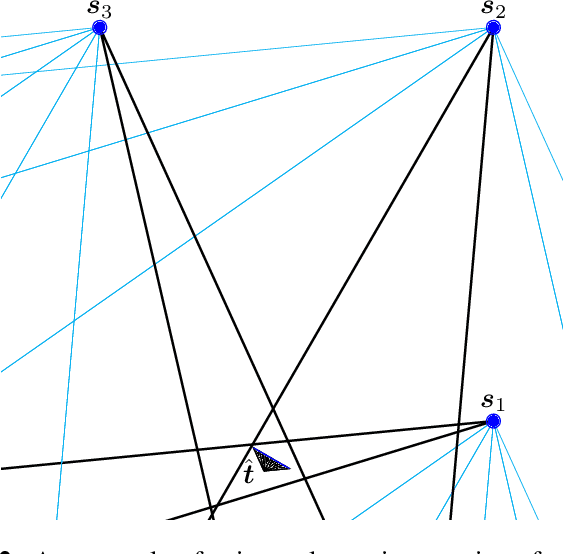
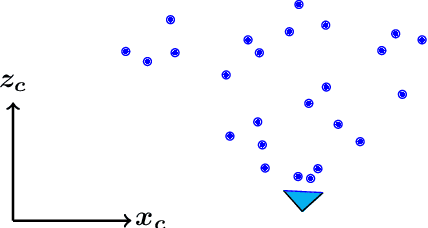
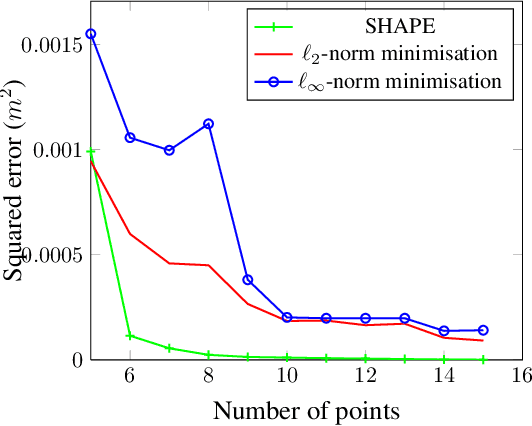
We propose a novel camera pose estimation or perspective-n-point (PnP) algorithm, based on the idea of consistency regions and half-space intersections. Our algorithm has linear time-complexity and a squared reconstruction error that decreases at least quadratically, as the number of feature point correspondences increase. Inspired by ideas from triangulation and frame quantisation theory, we define consistent reconstruction and then present SHAPE, our proposed consistent pose estimation algorithm. We compare this algorithm with state-of-the-art pose estimation techniques in terms of accuracy and error decay rate. The experimental results verify our hypothesis on the optimal worst-case quadratic decay and demonstrate its promising performance compared to other approaches.