 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLest We Forget: A Dataset of Coronavirus-Related News Headlines in Swiss Media
Jun 25, 2020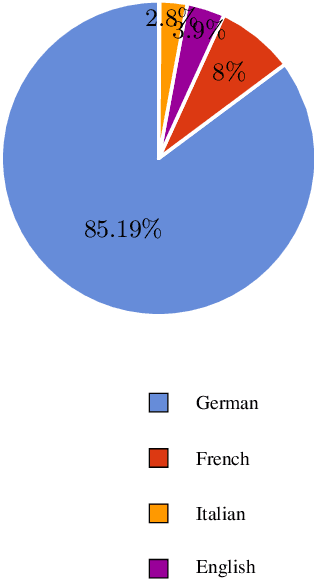

We release our COVID-19 news dataset, containing more than 10,000 links to news articles related to the Coronavirus pandemic published in the Swiss media since early January 2020. This collection can prove beneficial in mining and analysis of the reaction of the Swiss media and the COVID-19 pandemic and extracting insightful information for further research. We hope this dataset helps researchers and the public deliver results that will help analyse the pandemic and potentially lead to a better understanding of the events.
Bound and Conquer: Improving Triangulation by Enforcing Consistency
Apr 27, 2018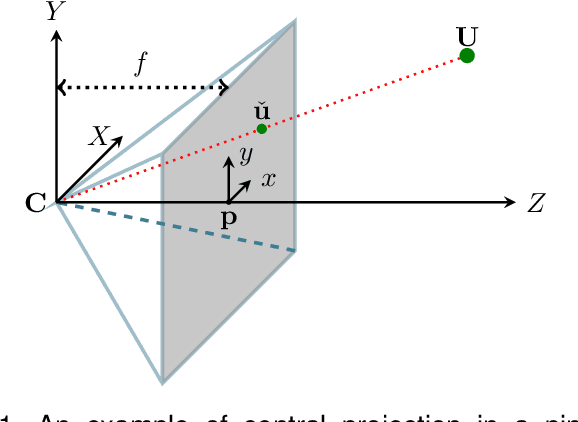
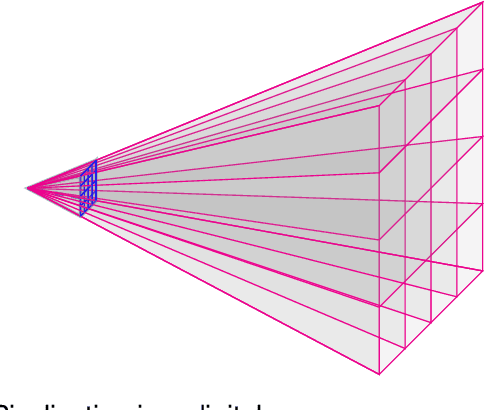
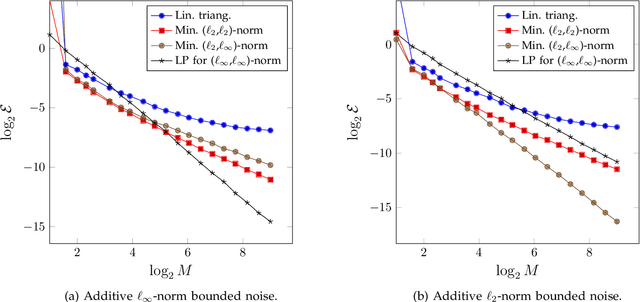

We study the accuracy of triangulation in multi-camera systems with respect to the number of cameras. We show that, under certain conditions, the optimal achievable reconstruction error decays quadratically as more cameras are added to the system. Furthermore, we analyse the error decay-rate of major state-of-the-art algorithms with respect to the number of cameras. To this end, we introduce the notion of consistency for triangulation, and show that consistent reconstruction algorithms achieve the optimal quadratic decay, which is asymptotically faster than some other methods. Finally, we present simulations results supporting our findings. Our simulations have been implemented in MATLAB and the resulting code is available in the supplementary material.
On the Accuracy of Point Localisation in a Circular Camera-Array
Feb 24, 2016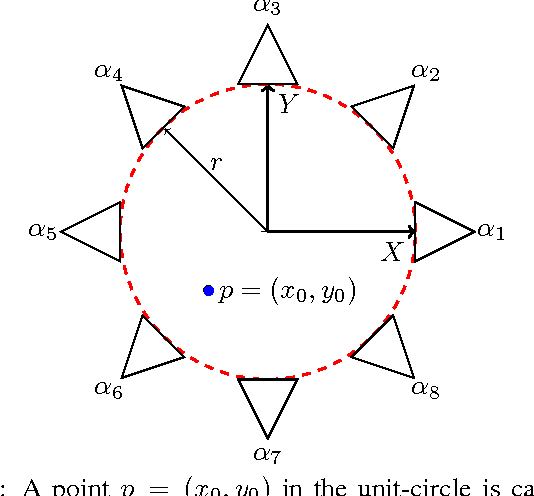
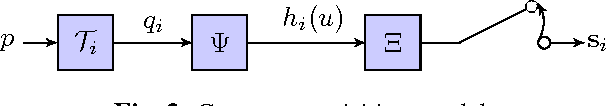
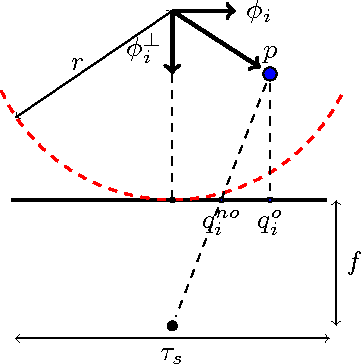
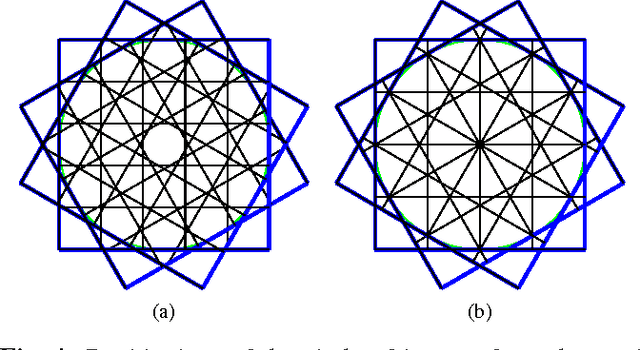
Although many advances have been made in light-field and camera-array image processing, there is still a lack of thorough analysis of the localisation accuracy of different multi-camera systems. By considering the problem from a frame-quantisation perspective, we are able to quantify the point localisation error of circular camera configurations. Specifically, we obtain closed form expressions bounding the localisation error in terms of the parameters describing the acquisition setup. These theoretical results are independent of the localisation algorithm and thus provide fundamental limits on performance. Furthermore, the new frame-quantisation perspective is general enough to be extended to more complex camera configurations.
SHAPE: Linear-Time Camera Pose Estimation With Quadratic Error-Decay
Feb 24, 2016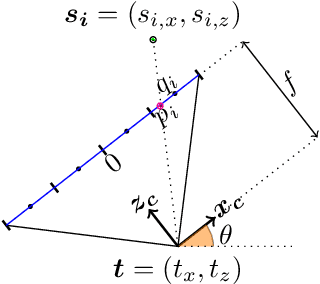
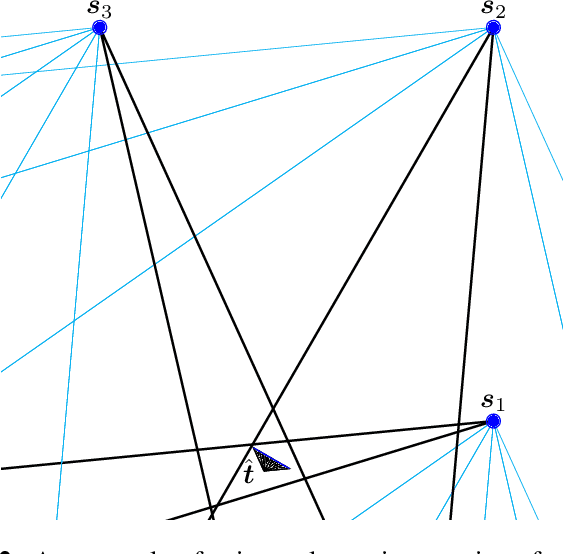
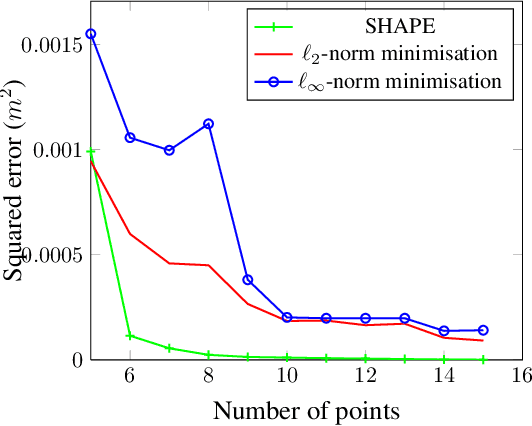
We propose a novel camera pose estimation or perspective-n-point (PnP) algorithm, based on the idea of consistency regions and half-space intersections. Our algorithm has linear time-complexity and a squared reconstruction error that decreases at least quadratically, as the number of feature point correspondences increase. Inspired by ideas from triangulation and frame quantisation theory, we define consistent reconstruction and then present SHAPE, our proposed consistent pose estimation algorithm. We compare this algorithm with state-of-the-art pose estimation techniques in terms of accuracy and error decay rate. The experimental results verify our hypothesis on the optimal worst-case quadratic decay and demonstrate its promising performance compared to other approaches.
A Bayesian Approach to the Data Description Problem
Feb 24, 2016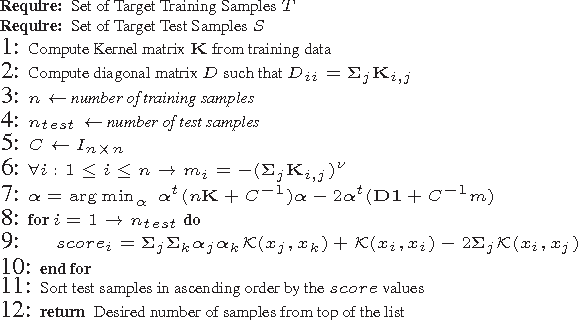
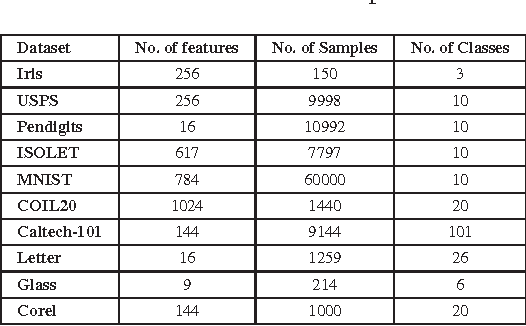

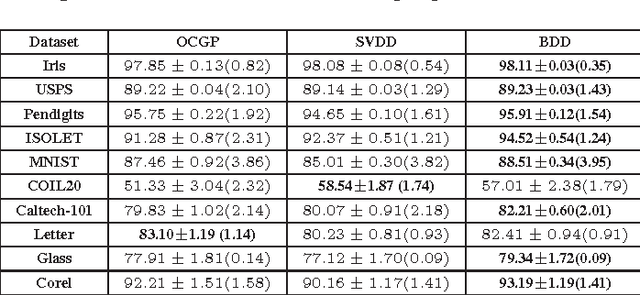
In this paper, we address the problem of data description using a Bayesian framework. The goal of data description is to draw a boundary around objects of a certain class of interest to discriminate that class from the rest of the feature space. Data description is also known as one-class learning and has a wide range of applications. The proposed approach uses a Bayesian framework to precisely compute the class boundary and therefore can utilize domain information in form of prior knowledge in the framework. It can also operate in the kernel space and therefore recognize arbitrary boundary shapes. Moreover, the proposed method can utilize unlabeled data in order to improve accuracy of discrimination. We evaluate our method using various real-world datasets and compare it with other state of the art approaches of data description. Experiments show promising results and improved performance over other data description and one-class learning algorithms.
Active Learning from Positive and Unlabeled Data
Feb 24, 2016

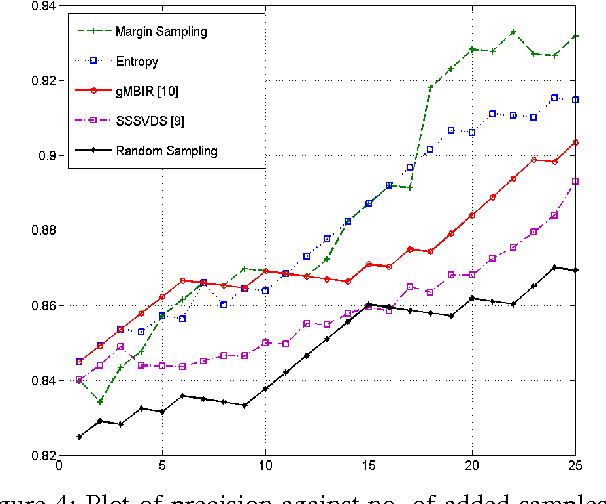

During recent years, active learning has evolved into a popular paradigm for utilizing user's feedback to improve accuracy of learning algorithms. Active learning works by selecting the most informative sample among unlabeled data and querying the label of that point from user. Many different methods such as uncertainty sampling and minimum risk sampling have been utilized to select the most informative sample in active learning. Although many active learning algorithms have been proposed so far, most of them work with binary or multi-class classification problems and therefore can not be applied to problems in which only samples from one class as well as a set of unlabeled data are available. Such problems arise in many real-world situations and are known as the problem of learning from positive and unlabeled data. In this paper we propose an active learning algorithm that can work when only samples of one class as well as a set of unlabelled data are available. Our method works by separately estimating probability desnity of positive and unlabeled points and then computing expected value of informativeness to get rid of a hyper-parameter and have a better measure of informativeness./ Experiments and empirical analysis show promising results compared to other similar methods.