 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Flight Boresight Rectification for Lightweight Airborne Pushbroom Imaging Spectrometry
Sep 10, 2024Hyperspectral cameras have recently been miniaturized for operation on lightweight airborne platforms such as UAV or small aircraft. Unlike frame cameras (RGB or Multispectral), many hyperspectral sensors use a linear array or 'push-broom' scanning design. This design presents significant challenges for image rectification and the calibration of the intrinsic and extrinsic camera parameters. Typically, methods employed to address such tasks rely on a precise GPS/INS estimate of the airborne platform trajectory and a detailed terrain model. However, inaccuracies in the trajectory or surface model information can introduce systematic errors and complicate geometric modeling which ultimately degrade the quality of the rectification. To overcome these challenges, we propose a method for tie point extraction and camera calibration for 'push-broom' hyperspectral sensors using only the raw spectral imagery and raw, possibly low quality, GPS/INS trajectory. We demonstrate that our approach allows for the automatic calibration of airborne systems with hyperspectral cameras, outperforms other state-of-the-art automatic rectification methods and reaches an accuracy on par with manual calibration methods.
Bayesian Learning for Disparity Map Refinement for Semi-Dense Active Stereo Vision
Sep 12, 2022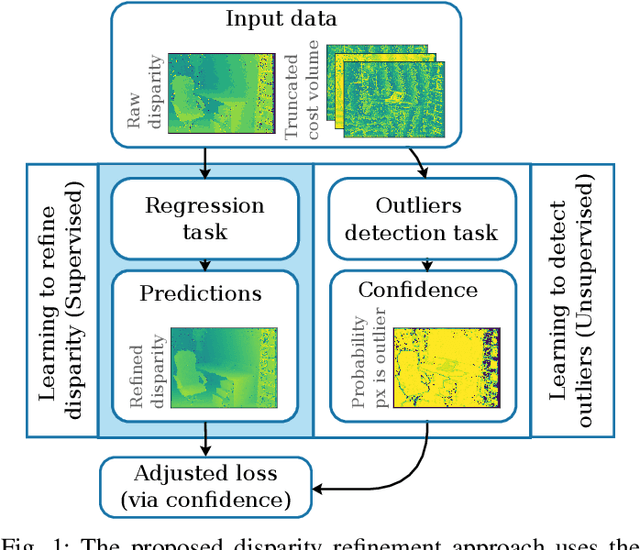
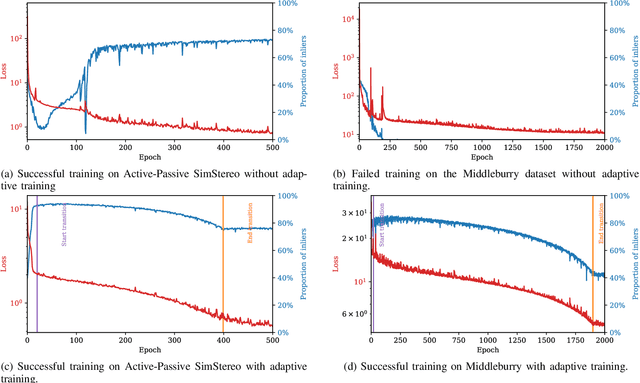
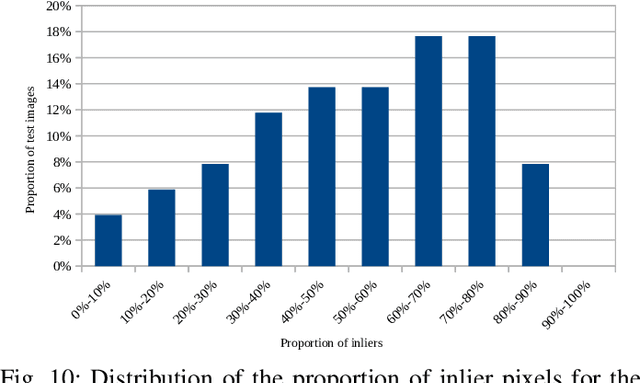
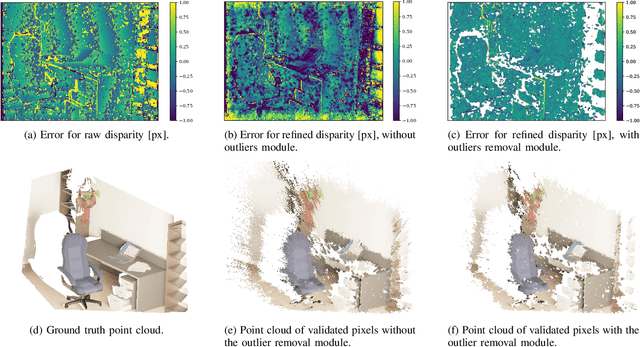
A major focus of recent developments in stereo vision has been on how to obtain accurate dense disparity maps in passive stereo vision. Active vision systems enable more accurate estimations of dense disparity compared to passive stereo. However, subpixel-accurate disparity estimation remains an open problem that has received little attention. In this paper, we propose a new learning strategy to train neural networks to estimate high-quality subpixel disparity maps for semi-dense active stereo vision. The key insight is that neural networks can double their accuracy if they are able to jointly learn how to refine the disparity map while invalidating the pixels where there is insufficient information to correct the disparity estimate. Our approach is based on Bayesian modeling where validated and invalidated pixels are defined by their stochastic properties, allowing the model to learn how to choose by itself which pixels are worth its attention. Using active stereo datasets such as Active-Passive SimStereo, we demonstrate that the proposed method outperforms the current state-of-the-art active stereo models. We also demonstrate that the proposed approach compares favorably with state-of-the-art passive stereo models on the Middlebury dataset.
Generalized Closed-form Formulae for Feature-based Subpixel Alignment in Patch-based Matching
Dec 02, 2021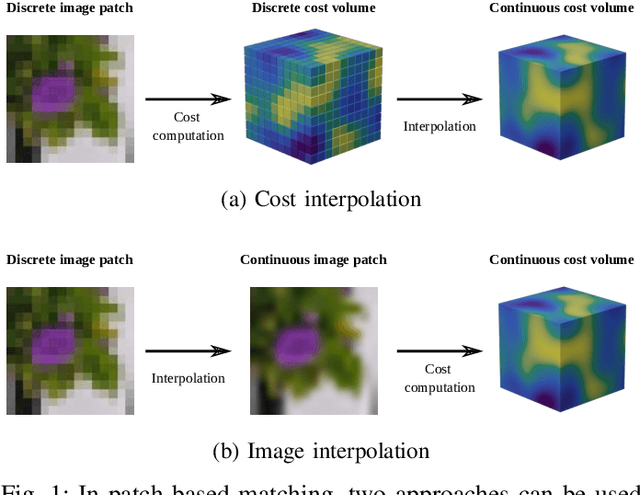

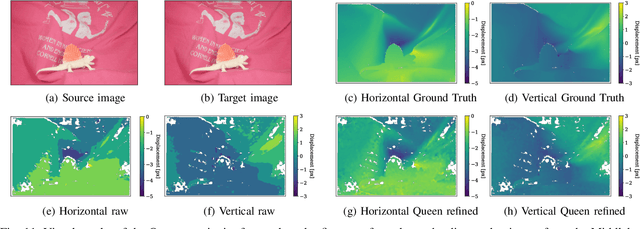
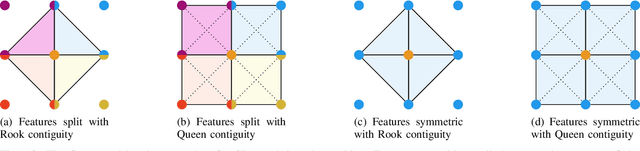
Cost-based image patch matching is at the core of various techniques in computer vision, photogrammetry and remote sensing. When the subpixel disparity between the reference patch in the source and target images is required, either the cost function or the target image have to be interpolated. While cost-based interpolation is the easiest to implement, multiple works have shown that image based interpolation can increase the accuracy of the subpixel matching, but usually at the cost of expensive search procedures. This, however, is problematic, especially for very computation intensive applications such as stereo matching or optical flow computation. In this paper, we show that closed form formulae for subpixel disparity computation for the case of one dimensional matching, e.g., in the case of rectified stereo images where the search space is of one dimension, exists when using the standard NCC, SSD and SAD cost functions. We then demonstrate how to generalize the proposed formulae to the case of high dimensional search spaces, which is required for unrectified stereo matching and optical flow extraction. We also compare our results with traditional cost volume interpolation formulae as well as with state-of-the-art cost-based refinement methods, and show that the proposed formulae bring a small improvement over the state-of-the-art cost-based methods in the case of one dimensional search spaces, and a significant improvement when the search space is two dimensional.
Hands-on Bayesian Neural Networks -- a Tutorial for Deep Learning Users
Jul 14, 2020
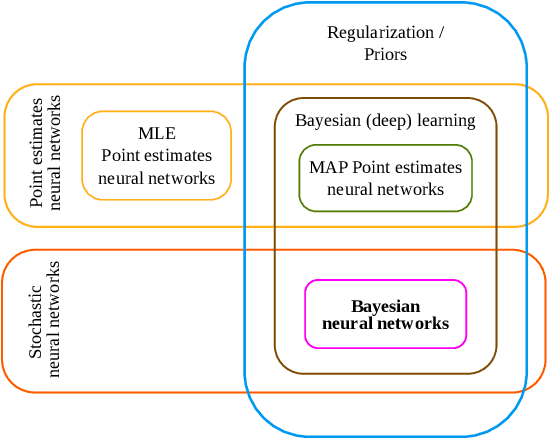
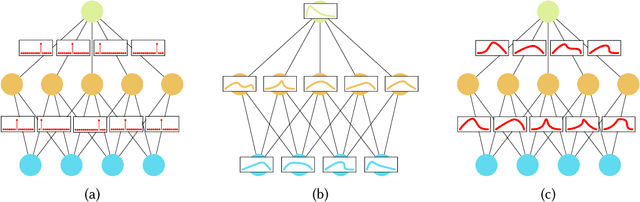
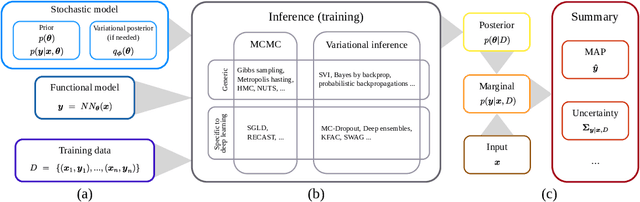
Modern deep learning methods have equipped researchers and engineers with incredibly powerful tools to tackle problems that previously seemed impossible. However, since deep learning methods operate as black boxes, the uncertainty associated with their predictions is often challenging to quantify. Bayesian statistics offer a formalism to understand and quantify the uncertainty associated with deep neural networks predictions. This paper provides a tutorial for researchers and scientists who are using machine learning, especially deep learning, with an overview of the relevant literature and a complete toolset to design, implement, train, use and evaluate Bayesian neural networks.
A Survey on Deep Learning Techniques for Stereo-based Depth Estimation
Jun 01, 2020


Estimating depth from RGB images is a long-standing ill-posed problem, which has been explored for decades by the computer vision, graphics, and machine learning communities. Among the existing techniques, stereo matching remains one of the most widely used in the literature due to its strong connection to the human binocular system. Traditionally, stereo-based depth estimation has been addressed through matching hand-crafted features across multiple images. Despite the extensive amount of research, these traditional techniques still suffer in the presence of highly textured areas, large uniform regions, and occlusions. Motivated by their growing success in solving various 2D and 3D vision problems, deep learning for stereo-based depth estimation has attracted growing interest from the community, with more than 150 papers published in this area between 2014 and 2019. This new generation of methods has demonstrated a significant leap in performance, enabling applications such as autonomous driving and augmented reality. In this article, we provide a comprehensive survey of this new and continuously growing field of research, summarize the most commonly used pipelines, and discuss their benefits and limitations. In retrospect of what has been achieved so far, we also conjecture what the future may hold for deep learning-based stereo for depth estimation research.
Embedded polarizing filters to separate diffuse and specular reflection
Nov 06, 2018



Polarizing filters provide a powerful way to separate diffuse and specular reflection; however, traditional methods rely on several captures and require proper alignment of the filters. Recently, camera manufacturers have proposed to embed polarizing micro-filters in front of the sensor, creating a mosaic of pixels with different polarizations. In this paper, we investigate the advantages of such camera designs. In particular, we consider different design patterns for the filter arrays and propose an algorithm to demosaic an image generated by such cameras. This essentially allows us to separate the diffuse and specular components using a single image. The performance of our algorithm is compared with a color-based method using synthetic and real data. Finally, we demonstrate how we can recover the normals of a scene using the diffuse images estimated by our method.