 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGridNet-HD: A High-Resolution Multi-Modal Dataset for LiDAR-Image Fusion on Power Line Infrastructure
Jan 19, 2026This paper presents GridNet-HD, a multi-modal dataset for 3D semantic segmentation of overhead electrical infrastructures, pairing high-density LiDAR with high-resolution oblique imagery. The dataset comprises 7,694 images and 2.5 billion points annotated into 11 classes, with predefined splits and mIoU metrics. Unimodal (LiDAR-only, image-only) and multi-modal fusion baselines are provided. On GridNet-HD, fusion models outperform the best unimodal baseline by +5.55 mIoU, highlighting the complementarity of geometry and appearance. As reviewed in Sec. 2, no public dataset jointly provides high-density LiDAR and high-resolution oblique imagery with 3D semantic labels for power-line assets. Dataset, baselines, and codes are available: https://huggingface.co/collections/heig-vd-geo/gridnet-hd.
Context-Aware Semantic Segmentation via Stage-Wise Attention
Jan 16, 2026Semantic ultra high resolution image (UHR) segmentation is essential in remote sensing applications such as aerial mapping and environmental monitoring. Transformer-based models struggle in this setting because memory grows quadratically with token count, constraining either the contextual scope or the spatial resolution. We introduce CASWiT (Context-Aware Stage-Wise Transformer), a dual-branch, Swin-based architecture that injects global cues into fine-grained UHR features. A context encoder processes a downsampled neighborhood to capture long-range dependencies, while a high resolution encoder extracts detailed features from UHR patches. A cross-scale fusion module, combining cross-attention and gated feature injection, enriches high-resolution tokens with context. Beyond architecture, we propose a SimMIM-style pretraining. We mask 75% of the high-resolution image tokens and the low-resolution center region that spatially corresponds to the UHR patch, then train the shared dual-encoder with small decoder to reconstruct the UHR initial image. Extensive experiments on the large-scale IGN FLAIR-HUB aerial dataset demonstrate the effectiveness of CASWiT. Our method achieves 65.83% mIoU, outperforming RGB baselines by 1.78 points. On URUR, CASWiT achieves 49.1% mIoU, surpassing the current SoTA by +0.9% under the official evaluation protocol. All codes are provided on: https://huggingface.co/collections/heig-vd-geo/caswit.
A Data-Centric Approach to 3D Semantic Segmentation of Railway Scenes
Apr 25, 2025


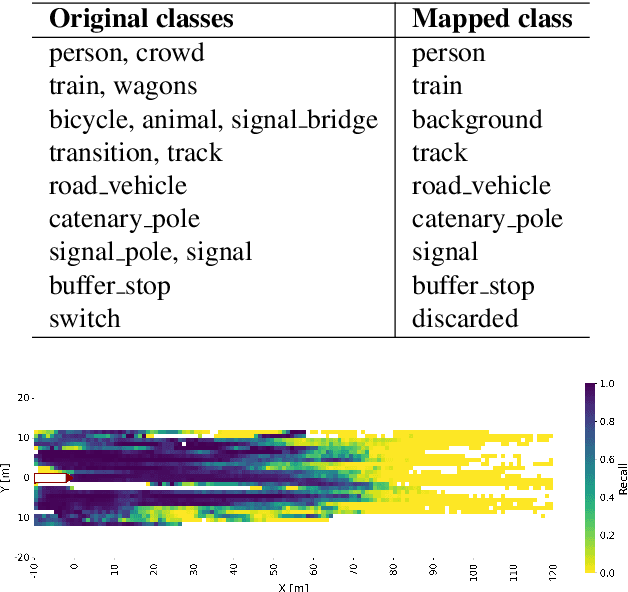
LiDAR-based semantic segmentation is critical for autonomous trains, requiring accurate predictions across varying distances. This paper introduces two targeted data augmentation methods designed to improve segmentation performance on the railway-specific OSDaR23 dataset. The person instance pasting method enhances segmentation of pedestrians at distant ranges by injecting realistic variations into the dataset. The track sparsification method redistributes point density in LiDAR scans, improving track segmentation at far distances with minimal impact on close-range accuracy. Both methods are evaluated using a state-of-the-art 3D semantic segmentation network, demonstrating significant improvements in distant-range performance while maintaining robustness in close-range predictions. We establish the first 3D semantic segmentation benchmark for OSDaR23, demonstrating the potential of data-centric approaches to address railway-specific challenges in autonomous train perception.
In Flight Boresight Rectification for Lightweight Airborne Pushbroom Imaging Spectrometry
Sep 10, 2024Hyperspectral cameras have recently been miniaturized for operation on lightweight airborne platforms such as UAV or small aircraft. Unlike frame cameras (RGB or Multispectral), many hyperspectral sensors use a linear array or 'push-broom' scanning design. This design presents significant challenges for image rectification and the calibration of the intrinsic and extrinsic camera parameters. Typically, methods employed to address such tasks rely on a precise GPS/INS estimate of the airborne platform trajectory and a detailed terrain model. However, inaccuracies in the trajectory or surface model information can introduce systematic errors and complicate geometric modeling which ultimately degrade the quality of the rectification. To overcome these challenges, we propose a method for tie point extraction and camera calibration for 'push-broom' hyperspectral sensors using only the raw spectral imagery and raw, possibly low quality, GPS/INS trajectory. We demonstrate that our approach allows for the automatic calibration of airborne systems with hyperspectral cameras, outperforms other state-of-the-art automatic rectification methods and reaches an accuracy on par with manual calibration methods.
LiDAR Point--to--point Correspondences for Rigorous Registration of Kinematic Scanning in Dynamic Networks
Jan 03, 2022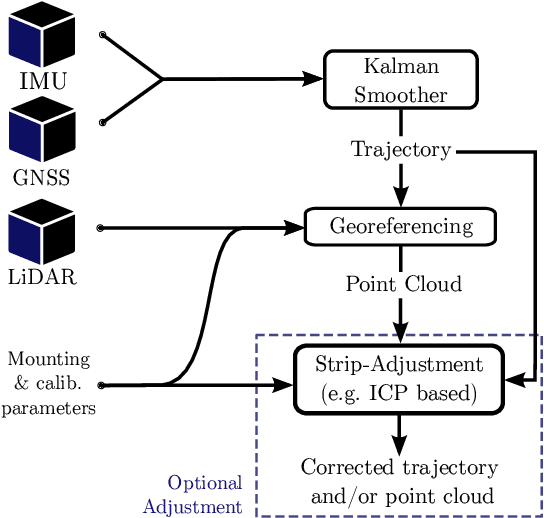

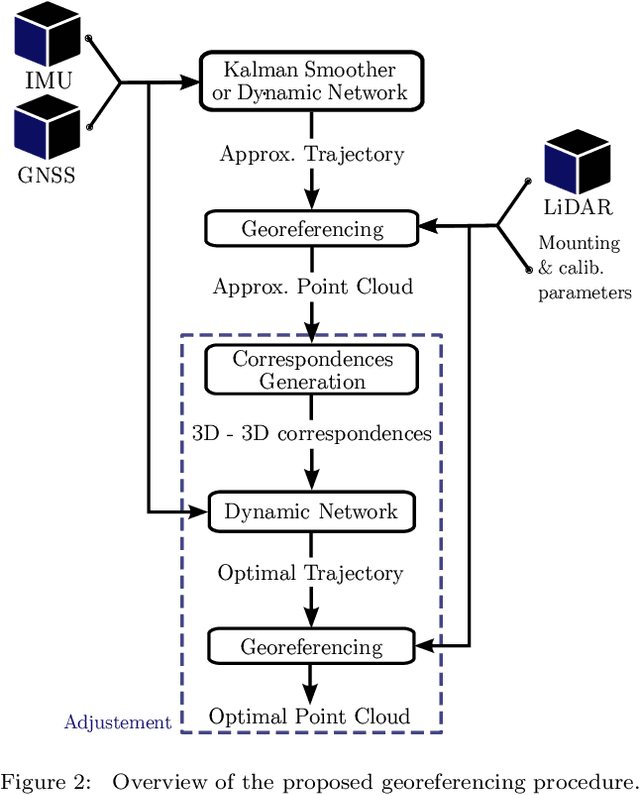

With the objective of improving the registration of LiDAR point clouds produced by kinematic scanning systems, we propose a novel trajectory adjustment procedure that leverages on the automated extraction of selected reliable 3D point--to--point correspondences between overlapping point clouds and their joint integration (adjustment) together with all raw inertial and GNSS observations. This is performed in a tightly coupled fashion using a Dynamic Network approach that results in an optimally compensated trajectory through modeling of errors at the sensor, rather than the trajectory, level. The 3D correspondences are formulated as static conditions within this network and the registered point cloud is generated with higher accuracy utilizing the corrected trajectory and possibly other parameters determined within the adjustment. We first describe the method for selecting correspondences and how they are inserted into the Dynamic Network as new observation models. We then describe the experiments conducted to evaluate the performance of the proposed framework in practical airborne laser scanning scenarios with low-cost MEMS inertial sensors. In the conducted experiments, the method proposed to establish 3D correspondences is effective in determining point--to--point matches across a wide range of geometries such as trees, buildings and cars. Our results demonstrate that the method improves the point cloud registration accuracy, that is otherwise strongly affected by errors in the determined platform attitude or position (in nominal and emulated GNSS outage conditions), and possibly determine unknown boresight angles using only a fraction of the total number of 3D correspondences that are established.