 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Complex Human Motion Video Generation via Text-to-Skeleton Cascades
Mar 09, 2026Generating videos of complex human motions such as flips, cartwheels, and martial arts remains challenging for current video diffusion models. Text-only conditioning is temporally ambiguous for fine-grained motion control, while explicit pose-based controls, though effective, require users to provide complete skeleton sequences that are costly to produce for long and dynamic actions. We propose a two-stage cascaded framework that addresses both limitations. First, an autoregressive text-to-skeleton model generates 2D pose sequences from natural language descriptions by predicting each joint conditioned on previously generated poses. This design captures long-range temporal dependencies and inter-joint coordination required for complex motions. Second, a pose-conditioned video diffusion model synthesizes videos from a reference image and the generated skeleton sequence. It employs DINO-ALF (Adaptive Layer Fusion), a multi-level reference encoder that preserves appearance and clothing details under large pose changes and self-occlusions. To address the lack of publicly available datasets for complex human motion video generation, we introduce a Blender-based synthetic dataset containing 2,000 videos with diverse characters performing acrobatic and stunt-like motions. The dataset provides full control over appearance, motion, and environment. It fills an important gap because existing benchmarks significantly under-represent acrobatic motions while web-collected datasets raise copyright and privacy concerns. Experiments on our synthetic dataset and the Motion-X Fitness benchmark show that our text-to-skeleton model outperforms prior methods on FID, R-precision, and motion diversity. Our pose-to-video model also achieves the best results among all compared methods on VBench metrics for temporal consistency, motion smoothness, and subject preservation.
LatentMove: Towards Complex Human Movement Video Generation
May 28, 2025Image-to-video (I2V) generation seeks to produce realistic motion sequences from a single reference image. Although recent methods exhibit strong temporal consistency, they often struggle when dealing with complex, non-repetitive human movements, leading to unnatural deformations. To tackle this issue, we present LatentMove, a DiT-based framework specifically tailored for highly dynamic human animation. Our architecture incorporates a conditional control branch and learnable face/body tokens to preserve consistency as well as fine-grained details across frames. We introduce Complex-Human-Videos (CHV), a dataset featuring diverse, challenging human motions designed to benchmark the robustness of I2V systems. We also introduce two metrics to assess the flow and silhouette consistency of generated videos with their ground truth. Experimental results indicate that LatentMove substantially improves human animation quality--particularly when handling rapid, intricate movements--thereby pushing the boundaries of I2V generation. The code, the CHV dataset, and the evaluation metrics will be available at https://github.com/ --.
Gaussian RBFNet: Gaussian Radial Basis Functions for Fast and Accurate Representation and Reconstruction of Neural Fields
Mar 09, 2025Neural fields such as DeepSDF and Neural Radiance Fields have recently revolutionized novel-view synthesis and 3D reconstruction from RGB images and videos. However, achieving high-quality representation, reconstruction, and rendering requires deep neural networks, which are slow to train and evaluate. Although several acceleration techniques have been proposed, they often trade off speed for memory. Gaussian splatting-based methods, on the other hand, accelerate the rendering time but remain costly in terms of training speed and memory needed to store the parameters of a large number of Gaussians. In this paper, we introduce a novel neural representation that is fast, both at training and inference times, and lightweight. Our key observation is that the neurons used in traditional MLPs perform simple computations (a dot product followed by ReLU activation) and thus one needs to use either wide and deep MLPs or high-resolution and high-dimensional feature grids to parameterize complex nonlinear functions. We show in this paper that by replacing traditional neurons with Radial Basis Function (RBF) kernels, one can achieve highly accurate representation of 2D (RGB images), 3D (geometry), and 5D (radiance fields) signals with just a single layer of such neurons. The representation is highly parallelizable, operates on low-resolution feature grids, and is compact and memory-efficient. We demonstrate that the proposed novel representation can be trained for 3D geometry representation in less than 15 seconds and for novel view synthesis in less than 15 mins. At runtime, it can synthesize novel views at more than 60 fps without sacrificing quality.
Dynamic Neural Surfaces for Elastic 4D Shape Representation and Analysis
Mar 05, 2025We propose a novel framework for the statistical analysis of genus-zero 4D surfaces, i.e., 3D surfaces that deform and evolve over time. This problem is particularly challenging due to the arbitrary parameterizations of these surfaces and their varying deformation speeds, necessitating effective spatiotemporal registration. Traditionally, 4D surfaces are discretized, in space and time, before computing their spatiotemporal registrations, geodesics, and statistics. However, this approach may result in suboptimal solutions and, as we demonstrate in this paper, is not necessary. In contrast, we treat 4D surfaces as continuous functions in both space and time. We introduce Dynamic Spherical Neural Surfaces (D-SNS), an efficient smooth and continuous spatiotemporal representation for genus-0 4D surfaces. We then demonstrate how to perform core 4D shape analysis tasks such as spatiotemporal registration, geodesics computation, and mean 4D shape estimation, directly on these continuous representations without upfront discretization and meshing. By integrating neural representations with classical Riemannian geometry and statistical shape analysis techniques, we provide the building blocks for enabling full functional shape analysis. We demonstrate the efficiency of the framework on 4D human and face datasets. The source code and additional results are available at https://4d-dsns.github.io/DSNS/.
* 22 pages, 23 figures, conference paper
A Riemannian Approach for Spatiotemporal Analysis and Generation of 4D Tree-shaped Structures
Aug 22, 2024



We propose the first comprehensive approach for modeling and analyzing the spatiotemporal shape variability in tree-like 4D objects, i.e., 3D objects whose shapes bend, stretch, and change in their branching structure over time as they deform, grow, and interact with their environment. Our key contribution is the representation of tree-like 3D shapes using Square Root Velocity Function Trees (SRVFT). By solving the spatial registration in the SRVFT space, which is equipped with an L2 metric, 4D tree-shaped structures become time-parameterized trajectories in this space. This reduces the problem of modeling and analyzing 4D tree-like shapes to that of modeling and analyzing elastic trajectories in the SRVFT space, where elasticity refers to time warping. In this paper, we propose a novel mathematical representation of the shape space of such trajectories, a Riemannian metric on that space, and computational tools for fast and accurate spatiotemporal registration and geodesics computation between 4D tree-shaped structures. Leveraging these building blocks, we develop a full framework for modelling the spatiotemporal variability using statistical models and generating novel 4D tree-like structures from a set of exemplars. We demonstrate and validate the proposed framework using real 4D plant data.
Faster Image2Video Generation: A Closer Look at CLIP Image Embedding's Impact on Spatio-Temporal Cross-Attentions
Jul 27, 2024



This paper investigates the role of CLIP image embeddings within the Stable Video Diffusion (SVD) framework, focusing on their impact on video generation quality and computational efficiency. Our findings indicate that CLIP embeddings, while crucial for aesthetic quality, do not significantly contribute towards the subject and background consistency of video outputs. Moreover, the computationally expensive cross-attention mechanism can be effectively replaced by a simpler linear layer. This layer is computed only once at the first diffusion inference step, and its output is then cached and reused throughout the inference process, thereby enhancing efficiency while maintaining high-quality outputs. Building on these insights, we introduce the VCUT, a training-free approach optimized for efficiency within the SVD architecture. VCUT eliminates temporal cross-attention and replaces spatial cross-attention with a one-time computed linear layer, significantly reducing computational load. The implementation of VCUT leads to a reduction of up to 322T Multiple-Accumulate Operations (MACs) per video and a decrease in model parameters by up to 50M, achieving a 20% reduction in latency compared to the baseline. Our approach demonstrates that conditioning during the Semantic Binding stage is sufficient, eliminating the need for continuous computation across all inference steps and setting a new standard for efficient video generation.
Deep Learning-based Depth Estimation Methods from Monocular Image and Videos: A Comprehensive Survey
Jun 28, 2024



Estimating depth from single RGB images and videos is of widespread interest due to its applications in many areas, including autonomous driving, 3D reconstruction, digital entertainment, and robotics. More than 500 deep learning-based papers have been published in the past 10 years, which indicates the growing interest in the task. This paper presents a comprehensive survey of the existing deep learning-based methods, the challenges they address, and how they have evolved in their architecture and supervision methods. It provides a taxonomy for classifying the current work based on their input and output modalities, network architectures, and learning methods. It also discusses the major milestones in the history of monocular depth estimation, and different pipelines, datasets, and evaluation metrics used in existing methods.
Normal-guided Detail-Preserving Neural Implicit Functions for High-Fidelity 3D Surface Reconstruction
Jun 07, 2024Neural implicit representations have emerged as a powerful paradigm for 3D reconstruction. However, despite their success, existing methods fail to capture fine geometric details and thin structures, especially in scenarios where only sparse RGB views of the objects of interest are available. We hypothesize that current methods for learning neural implicit representations from RGB or RGBD images produce 3D surfaces with missing parts and details because they only rely on 0-order differential properties, i.e. the 3D surface points and their projections, as supervisory signals. Such properties, however, do not capture the local 3D geometry around the points and also ignore the interactions between points. This paper demonstrates that training neural representations with first-order differential properties, i.e. surface normals, leads to highly accurate 3D surface reconstruction even in situations where only as few as two RGB (front and back) images are available. Given multiview RGB images of an object of interest, we first compute the approximate surface normals in the image space using the gradient of the depth maps produced using an off-the-shelf monocular depth estimator such as Depth Anything model. An implicit surface regressor is then trained using a loss function that enforces the first-order differential properties of the regressed surface to match those estimated from Depth Anything. Our extensive experiments on a wide range of real and synthetic datasets show that the proposed method achieves an unprecedented level of reconstruction accuracy even when using as few as two RGB views. The detailed ablation study also demonstrates that normal-based supervision plays a key role in this significant improvement in performance, enabling the 3D reconstruction of intricate geometric details and thin structures that were previously challenging to capture.
Box It to Bind It: Unified Layout Control and Attribute Binding in T2I Diffusion Models
Feb 27, 2024



While latent diffusion models (LDMs) excel at creating imaginative images, they often lack precision in semantic fidelity and spatial control over where objects are generated. To address these deficiencies, we introduce the Box-it-to-Bind-it (B2B) module - a novel, training-free approach for improving spatial control and semantic accuracy in text-to-image (T2I) diffusion models. B2B targets three key challenges in T2I: catastrophic neglect, attribute binding, and layout guidance. The process encompasses two main steps: i) Object generation, which adjusts the latent encoding to guarantee object generation and directs it within specified bounding boxes, and ii) attribute binding, guaranteeing that generated objects adhere to their specified attributes in the prompt. B2B is designed as a compatible plug-and-play module for existing T2I models, markedly enhancing model performance in addressing the key challenges. We evaluate our technique using the established CompBench and TIFA score benchmarks, demonstrating significant performance improvements compared to existing methods. The source code will be made publicly available at https://github.com/nextaistudio/BoxIt2BindIt.
MCTformer+: Multi-Class Token Transformer for Weakly Supervised Semantic Segmentation
Aug 06, 2023

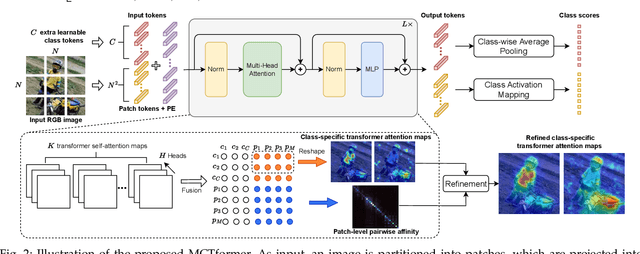

This paper proposes a novel transformer-based framework that aims to enhance weakly supervised semantic segmentation (WSSS) by generating accurate class-specific object localization maps as pseudo labels. Building upon the observation that the attended regions of the one-class token in the standard vision transformer can contribute to a class-agnostic localization map, we explore the potential of the transformer model to capture class-specific attention for class-discriminative object localization by learning multiple class tokens. We introduce a Multi-Class Token transformer, which incorporates multiple class tokens to enable class-aware interactions with the patch tokens. To achieve this, we devise a class-aware training strategy that establishes a one-to-one correspondence between the output class tokens and the ground-truth class labels. Moreover, a Contrastive-Class-Token (CCT) module is proposed to enhance the learning of discriminative class tokens, enabling the model to better capture the unique characteristics and properties of each class. As a result, class-discriminative object localization maps can be effectively generated by leveraging the class-to-patch attentions associated with different class tokens. To further refine these localization maps, we propose the utilization of patch-level pairwise affinity derived from the patch-to-patch transformer attention. Furthermore, the proposed framework seamlessly complements the Class Activation Mapping (CAM) method, resulting in significantly improved WSSS performance on the PASCAL VOC 2012 and MS COCO 2014 datasets. These results underline the importance of the class token for WSSS.