 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian RBFNet: Gaussian Radial Basis Functions for Fast and Accurate Representation and Reconstruction of Neural Fields
Mar 09, 2025Neural fields such as DeepSDF and Neural Radiance Fields have recently revolutionized novel-view synthesis and 3D reconstruction from RGB images and videos. However, achieving high-quality representation, reconstruction, and rendering requires deep neural networks, which are slow to train and evaluate. Although several acceleration techniques have been proposed, they often trade off speed for memory. Gaussian splatting-based methods, on the other hand, accelerate the rendering time but remain costly in terms of training speed and memory needed to store the parameters of a large number of Gaussians. In this paper, we introduce a novel neural representation that is fast, both at training and inference times, and lightweight. Our key observation is that the neurons used in traditional MLPs perform simple computations (a dot product followed by ReLU activation) and thus one needs to use either wide and deep MLPs or high-resolution and high-dimensional feature grids to parameterize complex nonlinear functions. We show in this paper that by replacing traditional neurons with Radial Basis Function (RBF) kernels, one can achieve highly accurate representation of 2D (RGB images), 3D (geometry), and 5D (radiance fields) signals with just a single layer of such neurons. The representation is highly parallelizable, operates on low-resolution feature grids, and is compact and memory-efficient. We demonstrate that the proposed novel representation can be trained for 3D geometry representation in less than 15 seconds and for novel view synthesis in less than 15 mins. At runtime, it can synthesize novel views at more than 60 fps without sacrificing quality.
Online hand gesture recognition using Continual Graph Transformers
Feb 20, 2025Online continuous action recognition has emerged as a critical research area due to its practical implications in real-world applications, such as human-computer interaction, healthcare, and robotics. Among various modalities, skeleton-based approaches have gained significant popularity, demonstrating their effectiveness in capturing 3D temporal data while ensuring robustness to environmental variations. However, most existing works focus on segment-based recognition, making them unsuitable for real-time, continuous recognition scenarios. In this paper, we propose a novel online recognition system designed for real-time skeleton sequence streaming. Our approach leverages a hybrid architecture combining Spatial Graph Convolutional Networks (S-GCN) for spatial feature extraction and a Transformer-based Graph Encoder (TGE) for capturing temporal dependencies across frames. Additionally, we introduce a continual learning mechanism to enhance model adaptability to evolving data distributions, ensuring robust recognition in dynamic environments. We evaluate our method on the SHREC'21 benchmark dataset, demonstrating its superior performance in online hand gesture recognition. Our approach not only achieves state-of-the-art accuracy but also significantly reduces false positive rates, making it a compelling solution for real-time applications. The proposed system can be seamlessly integrated into various domains, including human-robot collaboration and assistive technologies, where natural and intuitive interaction is crucial.
eMotion-GAN: A Motion-based GAN for Photorealistic and Facial Expression Preserving Frontal View Synthesis
Apr 15, 2024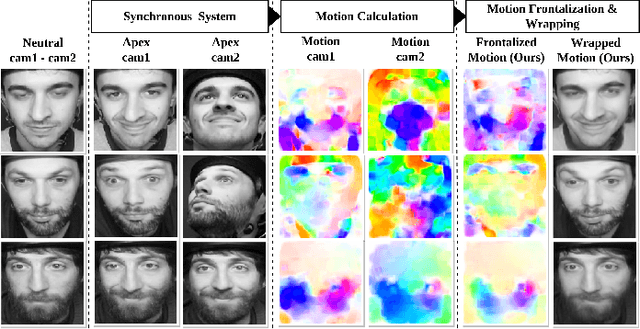

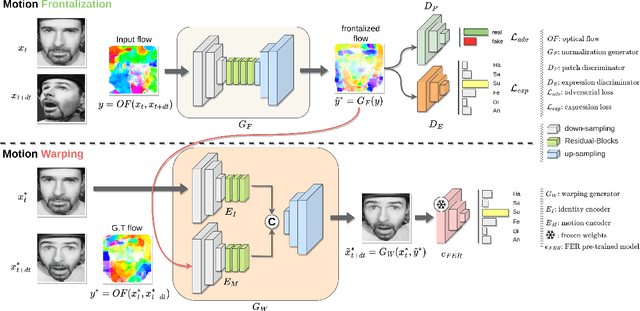
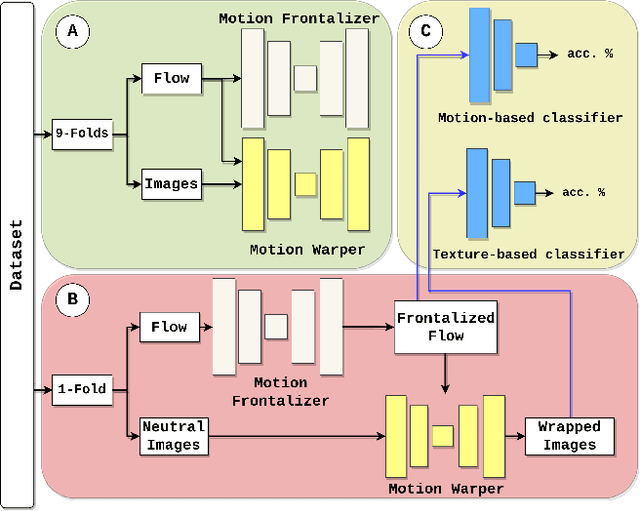
Many existing facial expression recognition (FER) systems encounter substantial performance degradation when faced with variations in head pose. Numerous frontalization methods have been proposed to enhance these systems' performance under such conditions. However, they often introduce undesirable deformations, rendering them less suitable for precise facial expression analysis. In this paper, we present eMotion-GAN, a novel deep learning approach designed for frontal view synthesis while preserving facial expressions within the motion domain. Considering the motion induced by head variation as noise and the motion induced by facial expression as the relevant information, our model is trained to filter out the noisy motion in order to retain only the motion related to facial expression. The filtered motion is then mapped onto a neutral frontal face to generate the corresponding expressive frontal face. We conducted extensive evaluations using several widely recognized dynamic FER datasets, which encompass sequences exhibiting various degrees of head pose variations in both intensity and orientation. Our results demonstrate the effectiveness of our approach in significantly reducing the FER performance gap between frontal and non-frontal faces. Specifically, we achieved a FER improvement of up to +5\% for small pose variations and up to +20\% improvement for larger pose variations. Code available at \url{https://github.com/o-ikne/eMotion-GAN.git}.
Spatio-Temporal Analysis of Transformer based Architecture for Attention Estimation from EEG
Apr 04, 2022
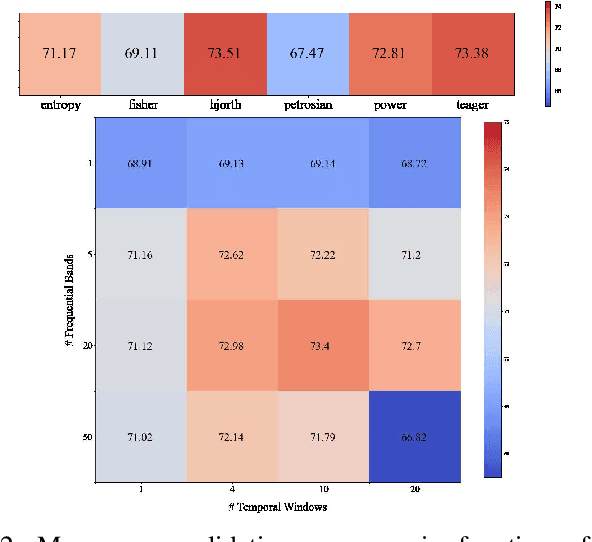
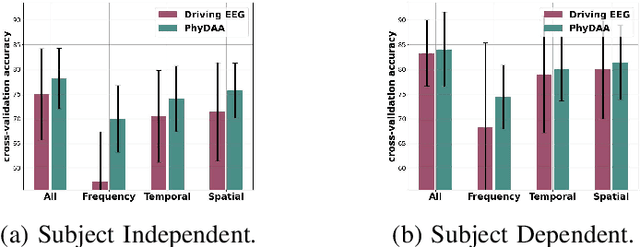
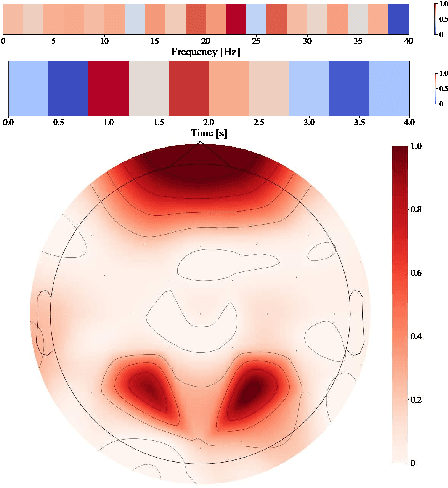
For many years now, understanding the brain mechanism has been a great research subject in many different fields. Brain signal processing and especially electroencephalogram (EEG) has recently known a growing interest both in academia and industry. One of the main examples is the increasing number of Brain-Computer Interfaces (BCI) aiming to link brains and computers. In this paper, we present a novel framework allowing us to retrieve the attention state, i.e degree of attention given to a specific task, from EEG signals. While previous methods often consider the spatial relationship in EEG through electrodes and process them in recurrent or convolutional based architecture, we propose here to also exploit the spatial and temporal information with a transformer-based network that has already shown its supremacy in many machine-learning (ML) related studies, e.g. machine translation. In addition to this novel architecture, an extensive study on the feature extraction methods, frequential bands and temporal windows length has also been carried out. The proposed network has been trained and validated on two public datasets and achieves higher results compared to state-of-the-art models. As well as proposing better results, the framework could be used in real applications, e.g. Attention Deficit Hyperactivity Disorder (ADHD) symptoms or vigilance during a driving assessment.
A Saliency based Feature Fusion Model for EEG Emotion Estimation
Jan 26, 2022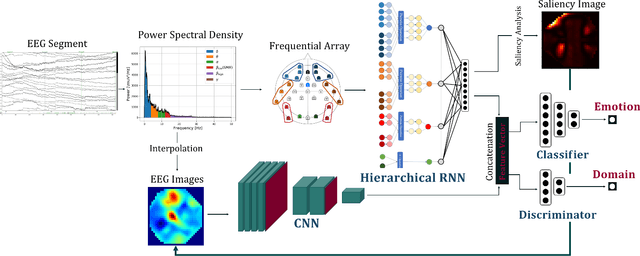


Among the different modalities to assess emotion, electroencephalogram (EEG), representing the electrical brain activity, achieved motivating results over the last decade. Emotion estimation from EEG could help in the diagnosis or rehabilitation of certain diseases. In this paper, we propose a dual model considering two different representations of EEG feature maps: 1) a sequential based representation of EEG band power, 2) an image-based representation of the feature vectors. We also propose an innovative method to combine the information based on a saliency analysis of the image-based model to promote joint learning of both model parts. The model has been evaluated on four publicly available datasets and achieves similar results to the state-of-the-art approaches. It outperforms results for two of the proposed datasets with a lower standard deviation that reflects higher stability. For sake of reproducibility, the codes and models proposed in this paper are available at https://github.com/VDelv/Emotion-EEG.
Where Is My Mind ? Predicting Visual Attention from Brain Activity
Jan 11, 2022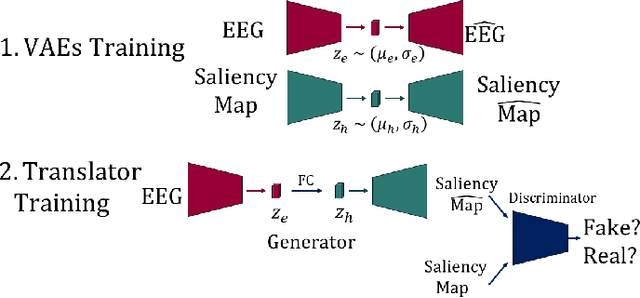
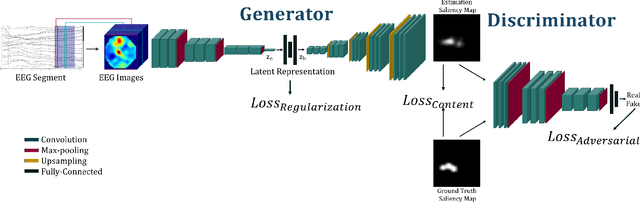

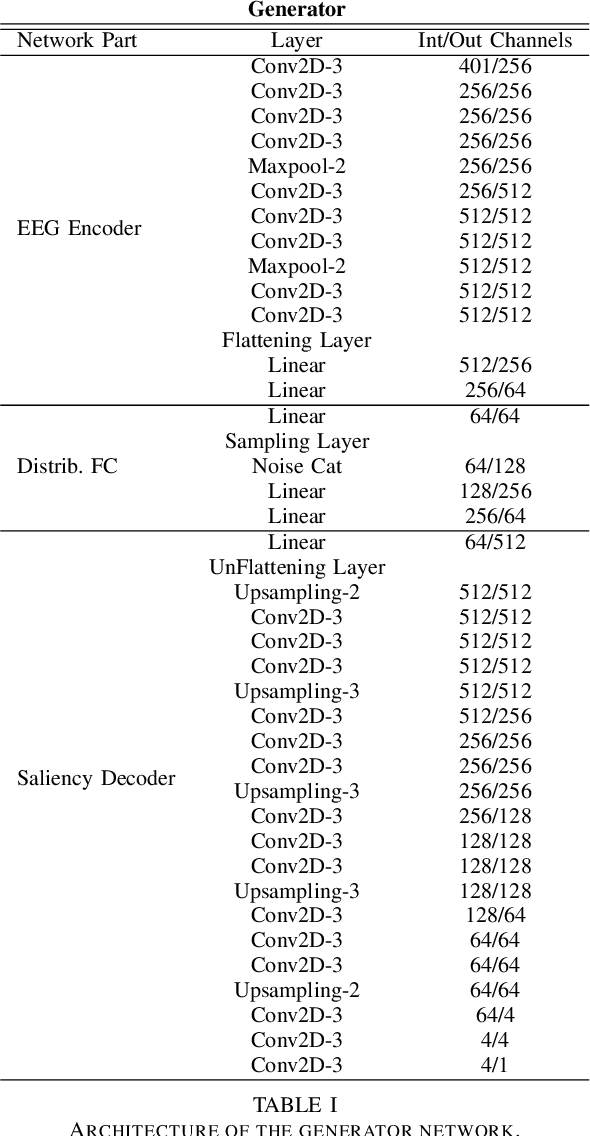
Visual attention estimation is an active field of research at the crossroads of different disciplines: computer vision, artificial intelligence and medicine. One of the most common approaches to estimate a saliency map representing attention is based on the observed images. In this paper, we show that visual attention can be retrieved from EEG acquisition. The results are comparable to traditional predictions from observed images, which is of great interest. For this purpose, a set of signals has been recorded and different models have been developed to study the relationship between visual attention and brain activity. The results are encouraging and comparable with other approaches estimating attention with other modalities. The codes and dataset considered in this paper have been made available at \url{https://figshare.com/s/3e353bd1c621962888ad} to promote research in the field.