 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPAA-SSL: Text Independent Phone-to-Audio Alignment based on Self-Supervised Learning and Knowledge Transfer
May 03, 2024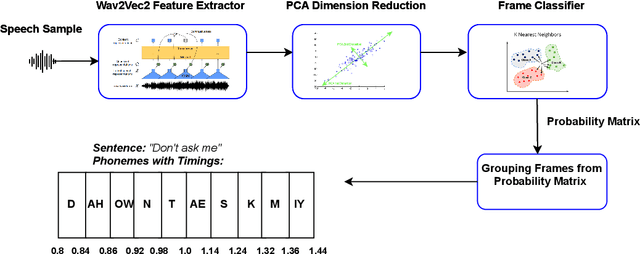
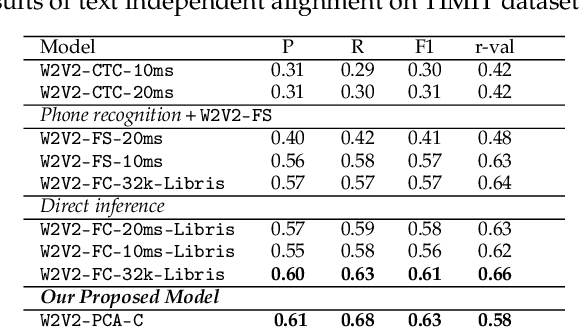
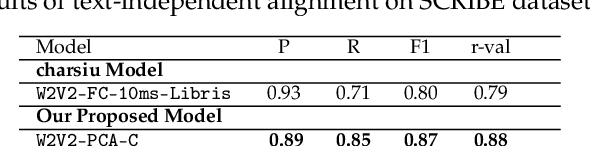
In this paper, we present a novel approach for text independent phone-to-audio alignment based on phoneme recognition, representation learning and knowledge transfer. Our method leverages a self-supervised model (wav2vec2) fine-tuned for phoneme recognition using a Connectionist Temporal Classification (CTC) loss, a dimension reduction model and a frame-level phoneme classifier trained thanks to forced-alignment labels (using Montreal Forced Aligner) to produce multi-lingual phonetic representations, thus requiring minimal additional training. We evaluate our model using synthetic native data from the TIMIT dataset and the SCRIBE dataset for American and British English, respectively. Our proposed model outperforms the state-of-the-art (charsiu) in statistical metrics and has applications in language learning and speech processing systems. We leave experiments on other languages for future work but the design of the system makes it easily adaptable to other languages.
MUST&P-SRL: Multi-lingual and Unified Syllabification in Text and Phonetic Domains for Speech Representation Learning
Oct 17, 2023In this paper, we present a methodology for linguistic feature extraction, focusing particularly on automatically syllabifying words in multiple languages, with a design to be compatible with a forced-alignment tool, the Montreal Forced Aligner (MFA). In both the textual and phonetic domains, our method focuses on the extraction of phonetic transcriptions from text, stress marks, and a unified automatic syllabification (in text and phonetic domains). The system was built with open-source components and resources. Through an ablation study, we demonstrate the efficacy of our approach in automatically syllabifying words from several languages (English, French and Spanish). Additionally, we apply the technique to the transcriptions of the CMU ARCTIC dataset, generating valuable annotations available online\footnote{\url{https://github.com/noetits/MUST_P-SRL}} that are ideal for speech representation learning, speech unit discovery, and disentanglement of speech factors in several speech-related fields.
Flowchase: a Mobile Application for Pronunciation Training
Jul 05, 2023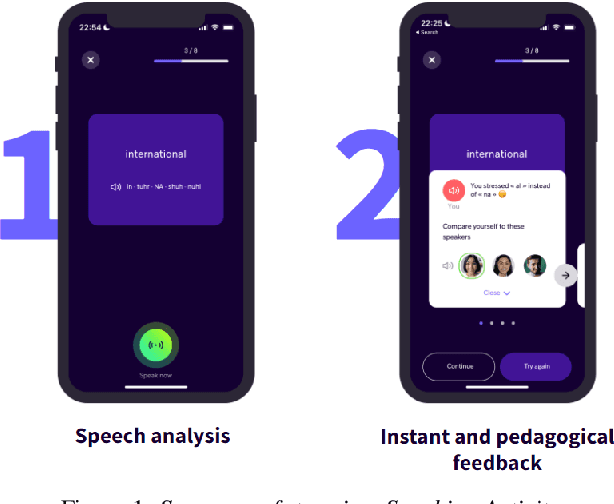
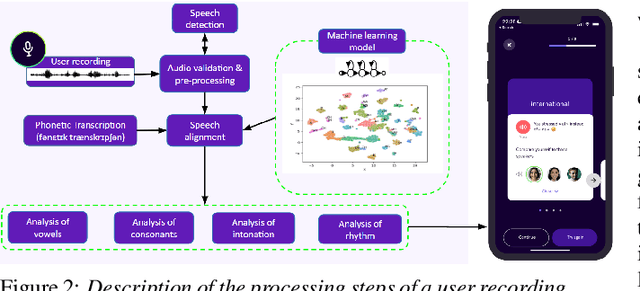

In this paper, we present a solution for providing personalized and instant feedback to English learners through a mobile application, called Flowchase, that is connected to a speech technology able to segment and analyze speech segmental and supra-segmental features. The speech processing pipeline receives linguistic information corresponding to an utterance to analyze along with a speech sample. After validation of the speech sample, a joint forced-alignment and phonetic recognition is performed thanks to a combination of machine learning models based on speech representation learning that provides necessary information for designing a feedback on a series of segmental and supra-segmental pronunciation aspects.
Where Is My Mind ? Predicting Visual Attention from Brain Activity
Jan 11, 2022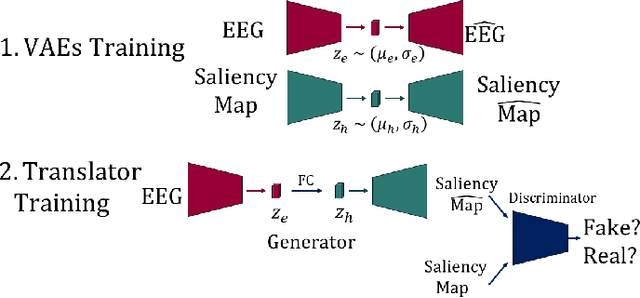
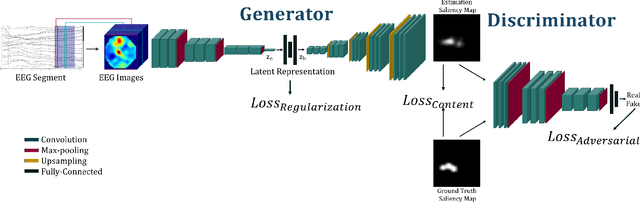

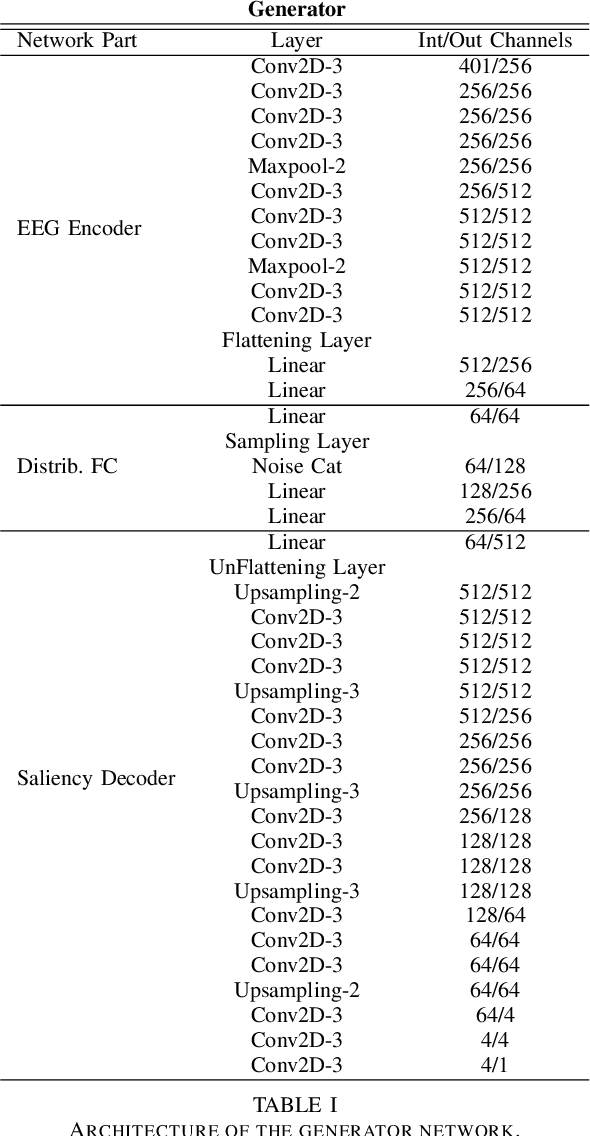
Visual attention estimation is an active field of research at the crossroads of different disciplines: computer vision, artificial intelligence and medicine. One of the most common approaches to estimate a saliency map representing attention is based on the observed images. In this paper, we show that visual attention can be retrieved from EEG acquisition. The results are comparable to traditional predictions from observed images, which is of great interest. For this purpose, a set of signals has been recorded and different models have been developed to study the relationship between visual attention and brain activity. The results are encouraging and comparable with other approaches estimating attention with other modalities. The codes and dataset considered in this paper have been made available at \url{https://figshare.com/s/3e353bd1c621962888ad} to promote research in the field.
Analysis and Assessment of Controllability of an Expressive Deep Learning-based TTS system
Mar 06, 2021

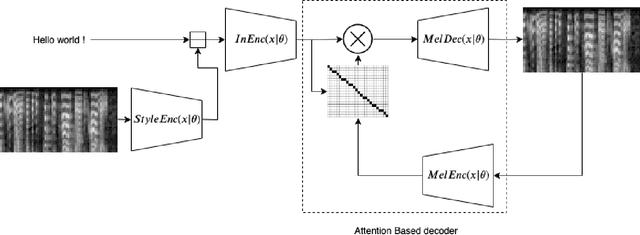

In this paper, we study the controllability of an Expressive TTS system trained on a dataset for a continuous control. The dataset is the Blizzard 2013 dataset based on audiobooks read by a female speaker containing a great variability in styles and expressiveness. Controllability is evaluated with both an objective and a subjective experiment. The objective assessment is based on a measure of correlation between acoustic features and the dimensions of the latent space representing expressiveness. The subjective assessment is based on a perceptual experiment in which users are shown an interface for Controllable Expressive TTS and asked to retrieve a synthetic utterance whose expressiveness subjectively corresponds to that a reference utterance.
Modulated Fusion using Transformer for Linguistic-Acoustic Emotion Recognition
Oct 05, 2020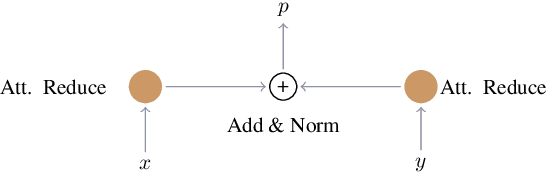
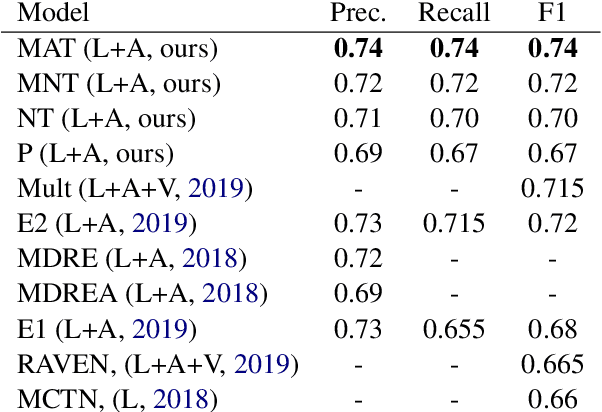
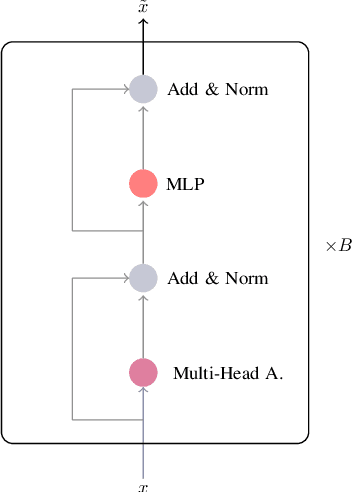
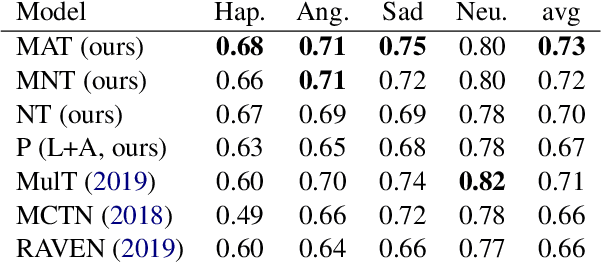
This paper aims to bring a new lightweight yet powerful solution for the task of Emotion Recognition and Sentiment Analysis. Our motivation is to propose two architectures based on Transformers and modulation that combine the linguistic and acoustic inputs from a wide range of datasets to challenge, and sometimes surpass, the state-of-the-art in the field. To demonstrate the efficiency of our models, we carefully evaluate their performances on the IEMOCAP, MOSI, MOSEI and MELD dataset. The experiments can be directly replicated and the code is fully open for future researches.
ICE-Talk: an Interface for a Controllable Expressive Talking Machine
Aug 25, 2020
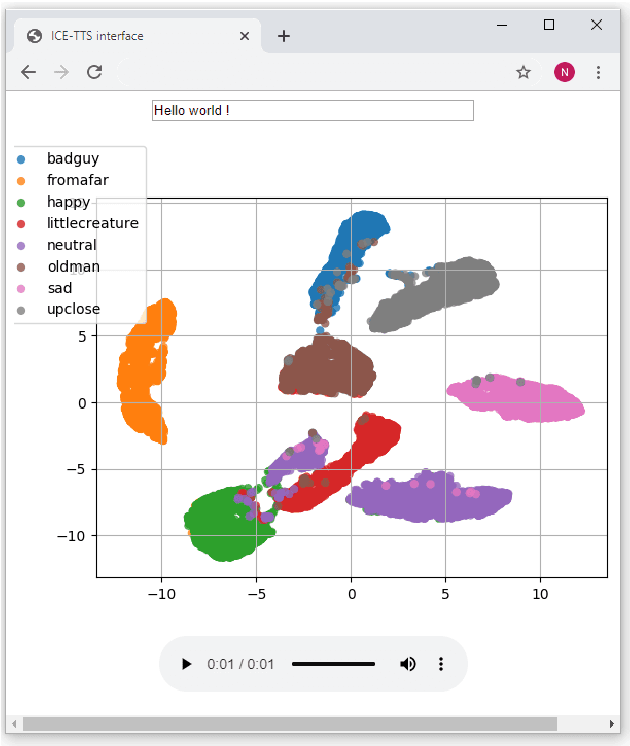
ICE-Talk is an open source web-based GUI that allows the use of a TTS system with controllable parameters via a text field and a clickable 2D plot. It enables the study of latent spaces for controllable TTS. Moreover it is implemented as a module that can be used as part of a Human-Agent interaction.
Laughter Synthesis: Combining Seq2seq modeling with Transfer Learning
Aug 20, 2020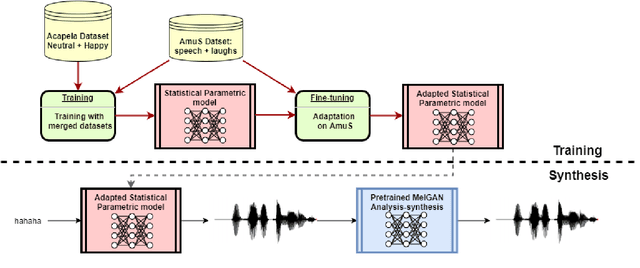
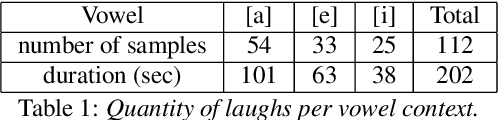

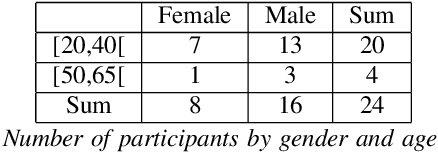
Despite the growing interest for expressive speech synthesis, synthesis of nonverbal expressions is an under-explored area. In this paper we propose an audio laughter synthesis system based on a sequence-to-sequence TTS synthesis system. We leverage transfer learning by training a deep learning model to learn to generate both speech and laughs from annotations. We evaluate our model with a listening test, comparing its performance to an HMM-based laughter synthesis one and assess that it reaches higher perceived naturalness. Our solution is a first step towards a TTS system that would be able to synthesize speech with a control on amusement level with laughter integration.
A Transformer-based joint-encoding for Emotion Recognition and Sentiment Analysis
Jun 29, 2020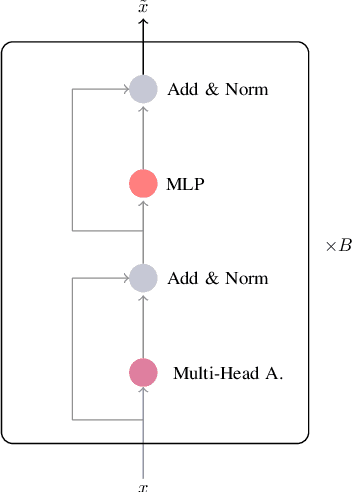
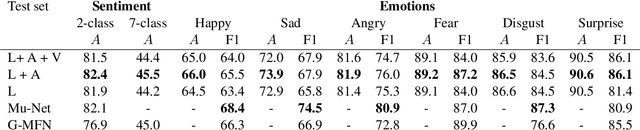
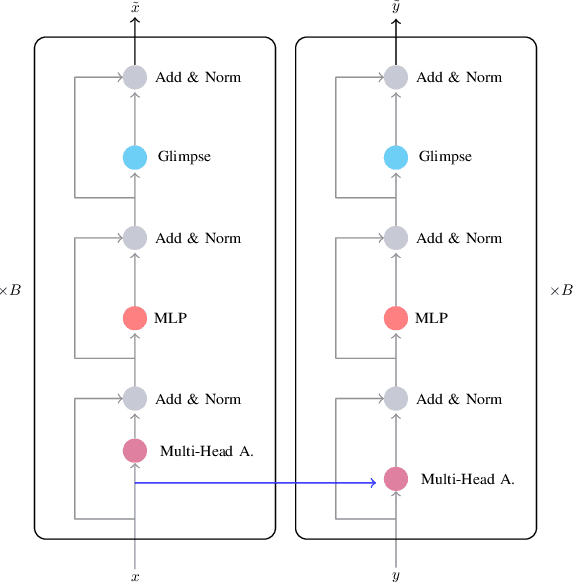
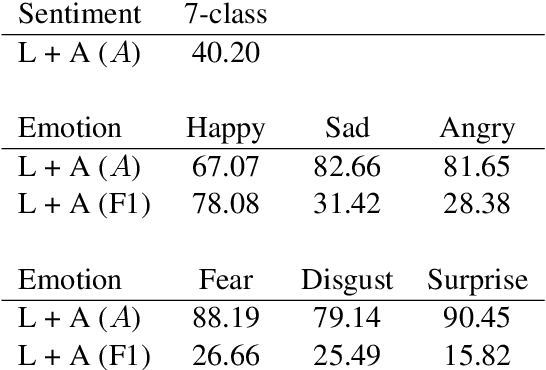
Understanding expressed sentiment and emotions are two crucial factors in human multimodal language. This paper describes a Transformer-based joint-encoding (TBJE) for the task of Emotion Recognition and Sentiment Analysis. In addition to use the Transformer architecture, our approach relies on a modular co-attention and a glimpse layer to jointly encode one or more modalities. The proposed solution has also been submitted to the ACL20: Second Grand-Challenge on Multimodal Language to be evaluated on the CMU-MOSEI dataset. The code to replicate the presented experiments is open-source: https://github.com/jbdel/MOSEI_UMONS.
The Theory behind Controllable Expressive Speech Synthesis: a Cross-disciplinary Approach
Oct 14, 2019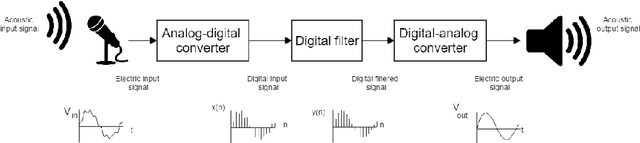
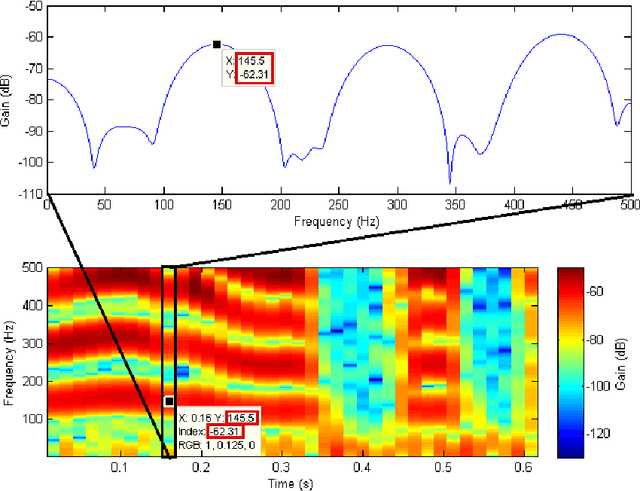

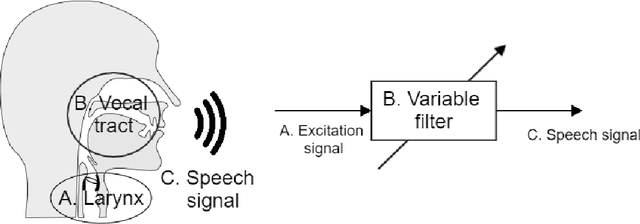
As part of the Human-Computer Interaction field, Expressive speech synthesis is a very rich domain as it requires knowledge in areas such as machine learning, signal processing, sociology, psychology. In this Chapter, we will focus mostly on the technical side. From the recording of expressive speech to its modeling, the reader will have an overview of the main paradigms used in this field, through some of the most prominent systems and methods. We explain how speech can be represented and encoded with audio features. We present a history of the main methods of Text-to-Speech synthesis: concatenative, parametric and statistical parametric speech synthesis. Finally, we focus on the last one, with the last techniques modeling Text-to-Speech synthesis as a sequence-to-sequence problem. This enables the use of Deep Learning blocks such as Convolutional and Recurrent Neural Networks as well as Attention Mechanism. The last part of the Chapter intends to assemble the different aspects of the theory and summarize the concepts.