Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModulated Fusion using Transformer for Linguistic-Acoustic Emotion Recognition
Paper and Code
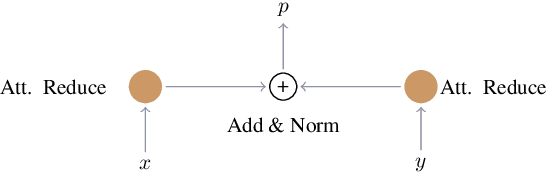
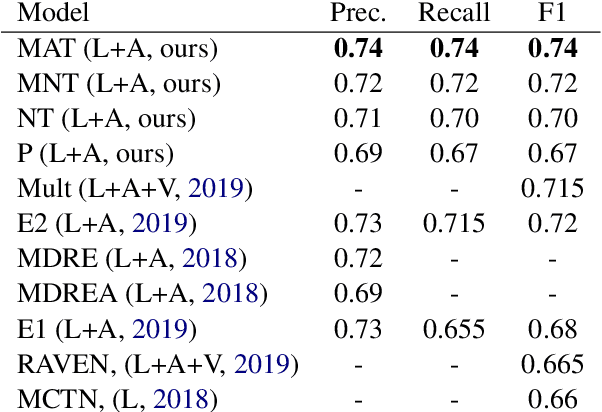
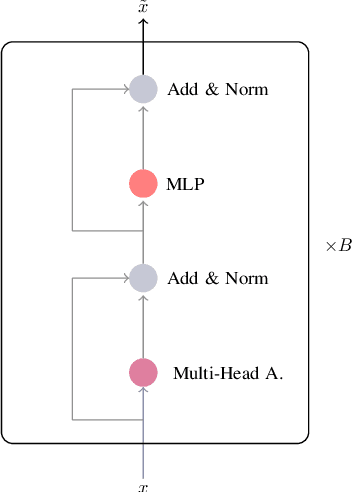
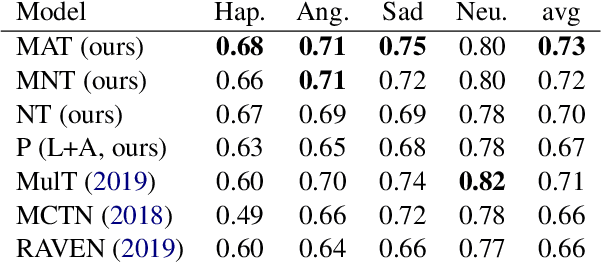
This paper aims to bring a new lightweight yet powerful solution for the task of Emotion Recognition and Sentiment Analysis. Our motivation is to propose two architectures based on Transformers and modulation that combine the linguistic and acoustic inputs from a wide range of datasets to challenge, and sometimes surpass, the state-of-the-art in the field. To demonstrate the efficiency of our models, we carefully evaluate their performances on the IEMOCAP, MOSI, MOSEI and MELD dataset. The experiments can be directly replicated and the code is fully open for future researches.
* EMNLP 2020 workshop: NLP Beyond Text (NLPBT)
View paper on