 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Avatar Animation in Virtual Reality: Impact of Motion Signals Artifacts on the Full-Body Pose Reconstruction
Apr 29, 2024Virtual Reality (VR) applications have revolutionized user experiences by immersing individuals in interactive 3D environments. These environments find applications in numerous fields, including healthcare, education, or architecture. A significant aspect of VR is the inclusion of self-avatars, representing users within the virtual world, which enhances interaction and embodiment. However, generating lifelike full-body self-avatar animations remains challenging, particularly in consumer-grade VR systems, where lower-body tracking is often absent. One method to tackle this problem is by providing an external source of motion information that includes lower body information such as full Cartesian positions estimated from RGB(D) cameras. Nevertheless, the limitations of these systems are multiples: the desynchronization between the two motion sources and occlusions are examples of significant issues that hinder the implementations of such systems. In this paper, we aim to measure the impact on the reconstruction of the articulated self-avatar's full-body pose of (1) the latency between the VR motion features and estimated positions, (2) the data acquisition rate, (3) occlusions, and (4) the inaccuracy of the position estimation algorithm. In addition, we analyze the motion reconstruction errors using ground truth and 3D Cartesian coordinates estimated from \textit{YOLOv8} pose estimation. These analyzes show that the studied methods are significantly sensitive to any degradation tested, especially regarding the velocity reconstruction error.
Analysis of Co-Laughter Gesture Relationship on RGB videos in Dyadic Conversation Contex
May 20, 2022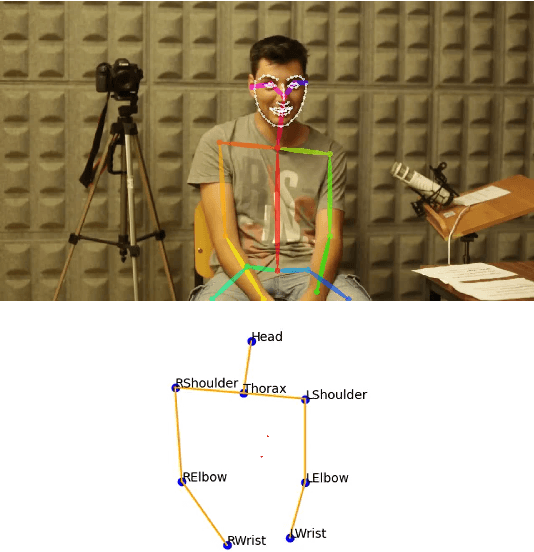

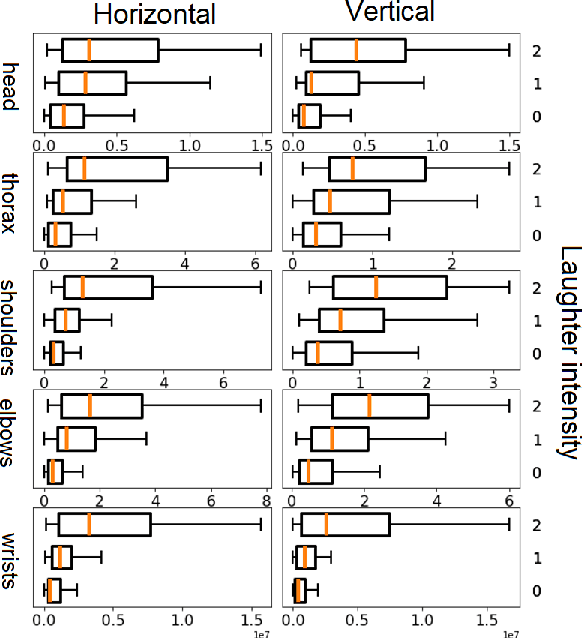
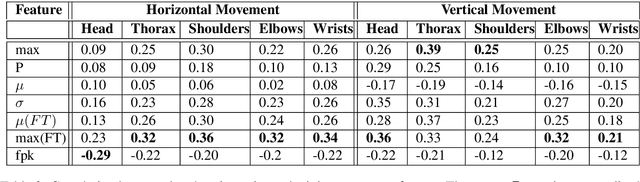
The development of virtual agents has enabled human-avatar interactions to become increasingly rich and varied. Moreover, an expressive virtual agent i.e. that mimics the natural expression of emotions, enhances social interaction between a user (human) and an agent (intelligent machine). The set of non-verbal behaviors of a virtual character is, therefore, an important component in the context of human-machine interaction. Laughter is not just an audio signal, but an intrinsic relationship of multimodal non-verbal communication, in addition to audio, it includes facial expressions and body movements. Motion analysis often relies on a relevant motion capture dataset, but the main issue is that the acquisition of such a dataset is expensive and time-consuming. This work studies the relationship between laughter and body movements in dyadic conversations. The body movements were extracted from videos using deep learning based pose estimator model. We found that, in the explored NDC-ME dataset, a single statistical feature (i.e, the maximum value, or the maximum of Fourier transform) of a joint movement weakly correlates with laughter intensity by 30%. However, we did not find a direct correlation between audio features and body movements. We discuss about the challenges to use such dataset for the audio-driven co-laughter motion synthesis task.
Evaluating the Quality of a Synthesized Motion with the Fréchet Motion Distance
Apr 27, 2022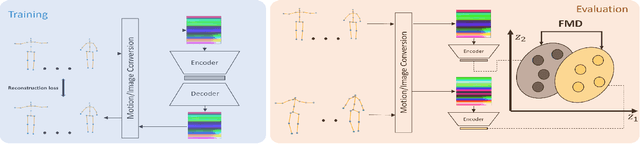

Evaluating the Quality of a Synthesized Motion with the Fr\'echet Motion Distance
Towards Lightweight Neural Animation : Exploration of Neural Network Pruning in Mixture of Experts-based Animation Models
Jan 24, 2022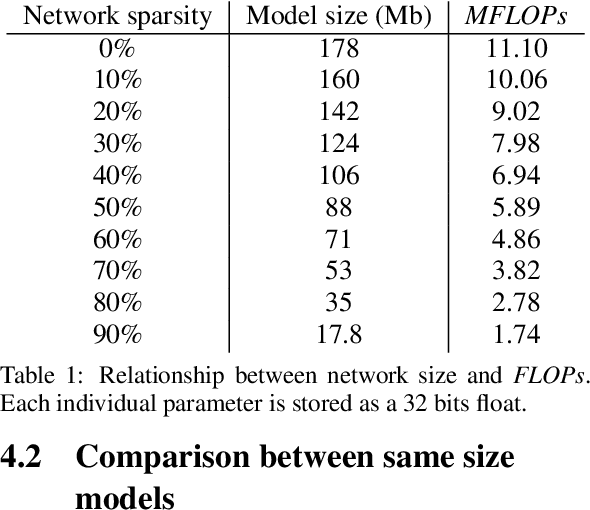
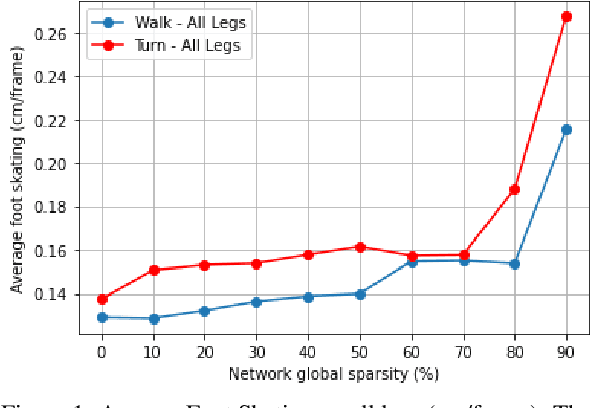


In the past few years, neural character animation has emerged and offered an automatic method for animating virtual characters. Their motion is synthesized by a neural network. Controlling this movement in real time with a user-defined control signal is also an important task in video games for example. Solutions based on fully-connected layers (MLPs) and Mixture-of-Experts (MoE) have given impressive results in generating and controlling various movements with close-range interactions between the environment and the virtual character. However, a major shortcoming of fully-connected layers is their computational and memory cost which may lead to sub-optimized solution. In this work, we apply pruning algorithms to compress an MLP- MoE neural network in the context of interactive character animation, which reduces its number of parameters and accelerates its computation time with a trade-off between this acceleration and the synthesized motion quality. This work demonstrates that, with the same number of experts and parameters, the pruned model produces less motion artifacts than the dense model and the learned high-level motion features are similar for both
Where Is My Mind ? Predicting Visual Attention from Brain Activity
Jan 11, 2022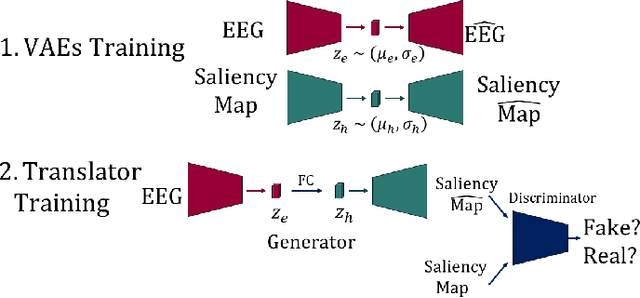
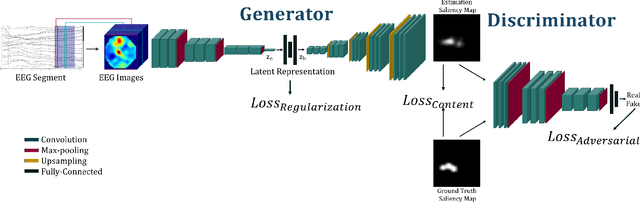

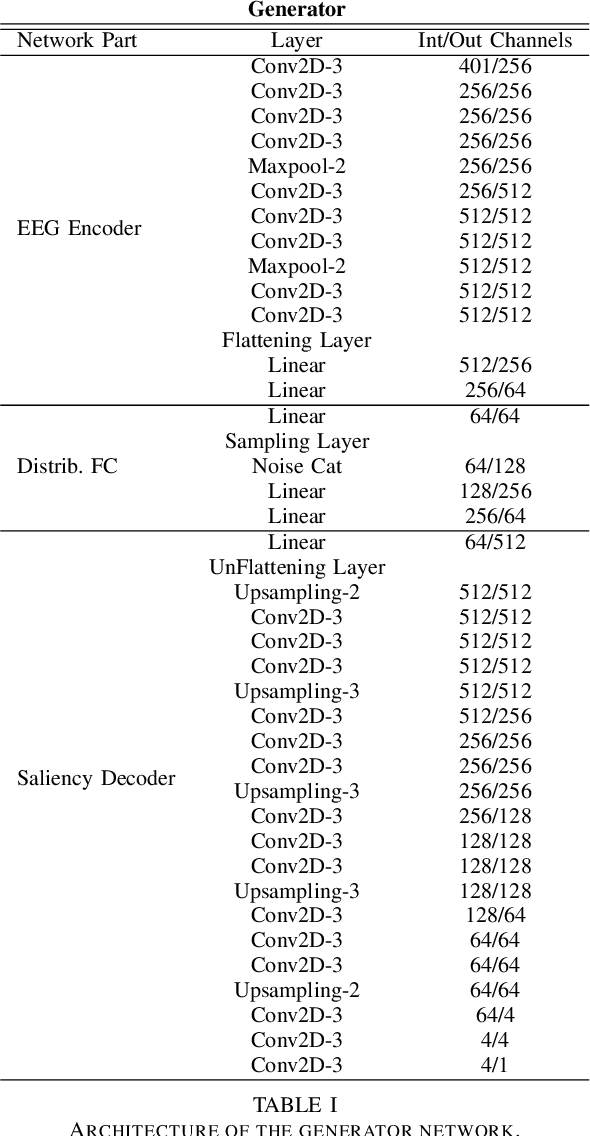
Visual attention estimation is an active field of research at the crossroads of different disciplines: computer vision, artificial intelligence and medicine. One of the most common approaches to estimate a saliency map representing attention is based on the observed images. In this paper, we show that visual attention can be retrieved from EEG acquisition. The results are comparable to traditional predictions from observed images, which is of great interest. For this purpose, a set of signals has been recorded and different models have been developed to study the relationship between visual attention and brain activity. The results are encouraging and comparable with other approaches estimating attention with other modalities. The codes and dataset considered in this paper have been made available at \url{https://figshare.com/s/3e353bd1c621962888ad} to promote research in the field.
Modulated Self-attention Convolutional Network for VQA
Oct 31, 2019

As new data-sets for real-world visual reasoning and compositional question answering are emerging, it might be needed to use the visual feature extraction as a end-to-end process during training. This small contribution aims to suggest new ideas to improve the visual processing of traditional convolutional network for visual question answering (VQA). In this paper, we propose to modulate by a linguistic input a CNN augmented with self-attention. We show encouraging relative improvements for future research in this direction.