 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning in medical image registration: introduction and survey
Sep 01, 2023Image registration (IR) is a process that deforms images to align them with respect to a reference space, making it easier for medical practitioners to examine various medical images in a standardized reference frame, such as having the same rotation and scale. This document introduces image registration using a simple numeric example. It provides a definition of image registration along with a space-oriented symbolic representation. This review covers various aspects of image transformations, including affine, deformable, invertible, and bidirectional transformations, as well as medical image registration algorithms such as Voxelmorph, Demons, SyN, Iterative Closest Point, and SynthMorph. It also explores atlas-based registration and multistage image registration techniques, including coarse-fine and pyramid approaches. Furthermore, this survey paper discusses medical image registration taxonomies, datasets, evaluation measures, such as correlation-based metrics, segmentation-based metrics, processing time, and model size. It also explores applications in image-guided surgery, motion tracking, and tumor diagnosis. Finally, the document addresses future research directions, including the further development of transformers.
Analysis of Co-Laughter Gesture Relationship on RGB videos in Dyadic Conversation Contex
May 20, 2022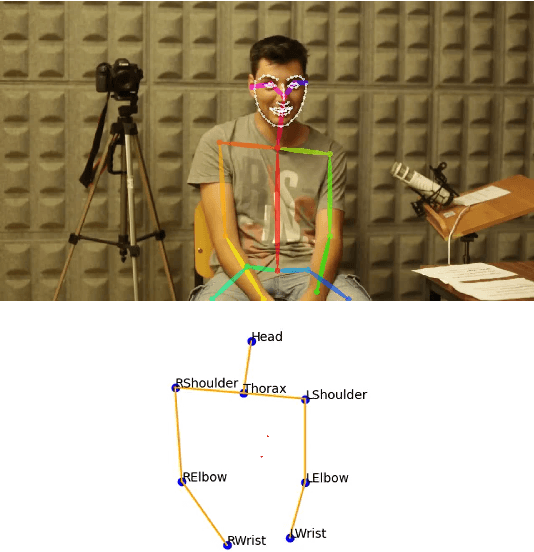

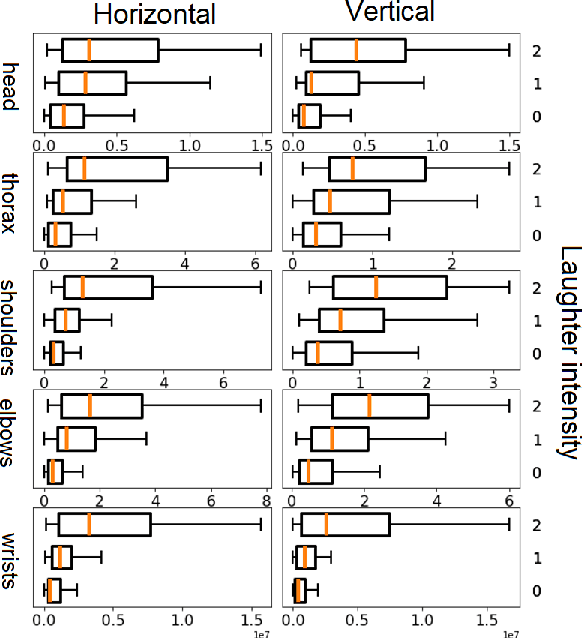
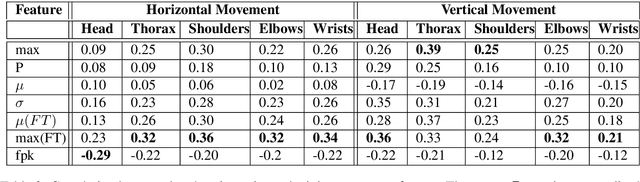
The development of virtual agents has enabled human-avatar interactions to become increasingly rich and varied. Moreover, an expressive virtual agent i.e. that mimics the natural expression of emotions, enhances social interaction between a user (human) and an agent (intelligent machine). The set of non-verbal behaviors of a virtual character is, therefore, an important component in the context of human-machine interaction. Laughter is not just an audio signal, but an intrinsic relationship of multimodal non-verbal communication, in addition to audio, it includes facial expressions and body movements. Motion analysis often relies on a relevant motion capture dataset, but the main issue is that the acquisition of such a dataset is expensive and time-consuming. This work studies the relationship between laughter and body movements in dyadic conversations. The body movements were extracted from videos using deep learning based pose estimator model. We found that, in the explored NDC-ME dataset, a single statistical feature (i.e, the maximum value, or the maximum of Fourier transform) of a joint movement weakly correlates with laughter intensity by 30%. However, we did not find a direct correlation between audio features and body movements. We discuss about the challenges to use such dataset for the audio-driven co-laughter motion synthesis task.
Deep soccer captioning with transformer: dataset, semantics-related losses, and multi-level evaluation
Feb 11, 2022This work aims at generating captions for soccer videos using deep learning. In this context, this paper introduces a dataset, model, and triple-level evaluation. The dataset consists of 22k caption-clip pairs and three visual features (images, optical flow, inpainting) for ~500 hours of \emph{SoccerNet} videos. The model is divided into three parts: a transformer learns language, ConvNets learn vision, and a fusion of linguistic and visual features generates captions. The paper suggests evaluating generated captions at three levels: syntax (the commonly used evaluation metrics such as BLEU-score and CIDEr), meaning (the quality of descriptions for a domain expert), and corpus (the diversity of generated captions). The paper shows that the diversity of generated captions has improved (from 0.07 reaching 0.18) with semantics-related losses that prioritize selected words. Semantics-related losses and the utilization of more visual features (optical flow, inpainting) improved the normalized captioning score by 28\%. The web page of this work: https://sites.google.com/view/soccercaptioning}{https://sites.google.com/view/soccercaptioning
A Reflection on Learning from Data: Epistemology Issues and Limitations
Jul 28, 2021Although learning from data is effective and has achieved significant milestones, it has many challenges and limitations. Learning from data starts from observations and then proceeds to broader generalizations. This framework is controversial in science, yet it has achieved remarkable engineering successes. This paper reflects on some epistemological issues and some of the limitations of the knowledge discovered in data. The document discusses the common perception that getting more data is the key to achieving better machine learning models from theoretical and practical perspectives. The paper sheds some light on the shortcomings of using generic mathematical theories to describe the process. It further highlights the need for theories specialized in learning from data. While more data leverages the performance of machine learning models in general, the relation in practice is shown to be logarithmic at its best; After a specific limit, more data stabilize or degrade the machine learning models. Recent work in reinforcement learning showed that the trend is shifting away from data-oriented approaches and relying more on algorithms. The paper concludes that learning from data is hindered by many limitations. Hence an approach that has an intensional orientation is needed.