 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial-MAE: A Transformer-Based Multimodal Autoencoder for Face and Voice
Aug 24, 2025Human social behaviors are inherently multimodal necessitating the development of powerful audiovisual models for their perception. In this paper, we present Social-MAE, our pre-trained audiovisual Masked Autoencoder based on an extended version of Contrastive Audio-Visual Masked Auto-Encoder (CAV-MAE), which is pre-trained on audiovisual social data. Specifically, we modify CAV-MAE to receive a larger number of frames as input and pre-train it on a large dataset of human social interaction (VoxCeleb2) in a self-supervised manner. We demonstrate the effectiveness of this model by finetuning and evaluating the model on different social and affective downstream tasks, namely, emotion recognition, laughter detection and apparent personality estimation. The model achieves state-of-the-art results on multimodal emotion recognition and laughter recognition and competitive results for apparent personality estimation, demonstrating the effectiveness of in-domain self-supervised pre-training. Code and model weight are available here https://github.com/HuBohy/SocialMAE.
* 5 pages, 3 figures, IEEE FG 2024 conference
TIPAA-SSL: Text Independent Phone-to-Audio Alignment based on Self-Supervised Learning and Knowledge Transfer
May 03, 2024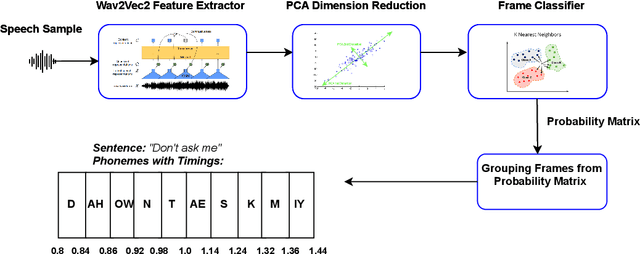
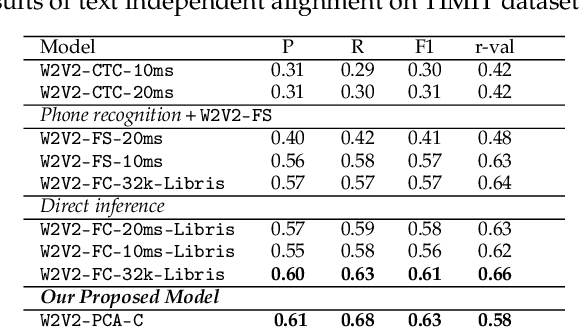
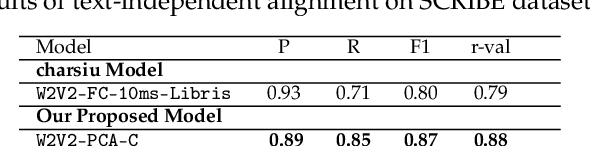
In this paper, we present a novel approach for text independent phone-to-audio alignment based on phoneme recognition, representation learning and knowledge transfer. Our method leverages a self-supervised model (wav2vec2) fine-tuned for phoneme recognition using a Connectionist Temporal Classification (CTC) loss, a dimension reduction model and a frame-level phoneme classifier trained thanks to forced-alignment labels (using Montreal Forced Aligner) to produce multi-lingual phonetic representations, thus requiring minimal additional training. We evaluate our model using synthetic native data from the TIMIT dataset and the SCRIBE dataset for American and British English, respectively. Our proposed model outperforms the state-of-the-art (charsiu) in statistical metrics and has applications in language learning and speech processing systems. We leave experiments on other languages for future work but the design of the system makes it easily adaptable to other languages.
Self-Avatar Animation in Virtual Reality: Impact of Motion Signals Artifacts on the Full-Body Pose Reconstruction
Apr 29, 2024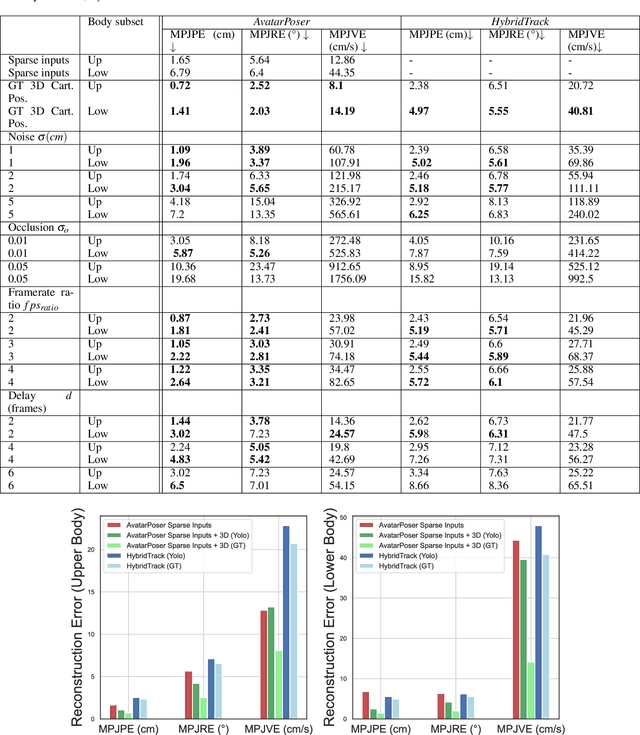
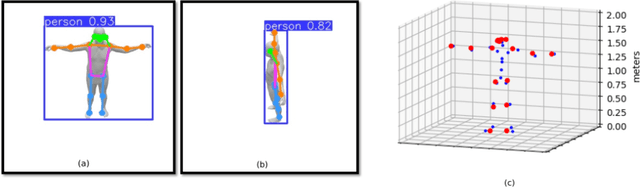
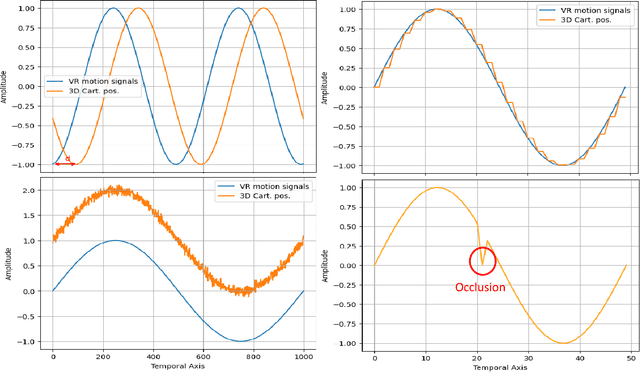
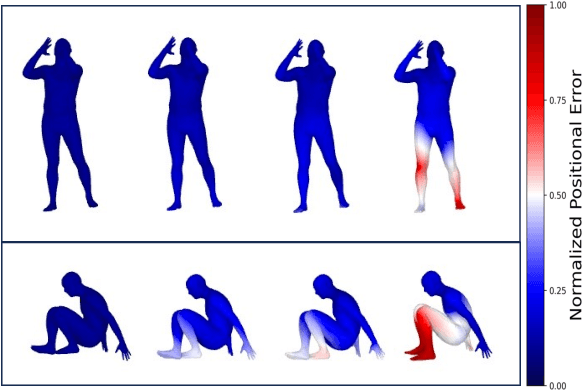
Virtual Reality (VR) applications have revolutionized user experiences by immersing individuals in interactive 3D environments. These environments find applications in numerous fields, including healthcare, education, or architecture. A significant aspect of VR is the inclusion of self-avatars, representing users within the virtual world, which enhances interaction and embodiment. However, generating lifelike full-body self-avatar animations remains challenging, particularly in consumer-grade VR systems, where lower-body tracking is often absent. One method to tackle this problem is by providing an external source of motion information that includes lower body information such as full Cartesian positions estimated from RGB(D) cameras. Nevertheless, the limitations of these systems are multiples: the desynchronization between the two motion sources and occlusions are examples of significant issues that hinder the implementations of such systems. In this paper, we aim to measure the impact on the reconstruction of the articulated self-avatar's full-body pose of (1) the latency between the VR motion features and estimated positions, (2) the data acquisition rate, (3) occlusions, and (4) the inaccuracy of the position estimation algorithm. In addition, we analyze the motion reconstruction errors using ground truth and 3D Cartesian coordinates estimated from \textit{YOLOv8} pose estimation. These analyzes show that the studied methods are significantly sensitive to any degradation tested, especially regarding the velocity reconstruction error.
A New Perspective on Smiling and Laughter Detection: Intensity Levels Matter
Mar 04, 2024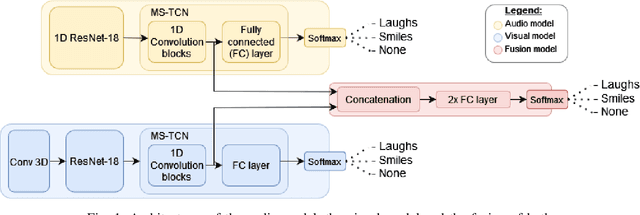
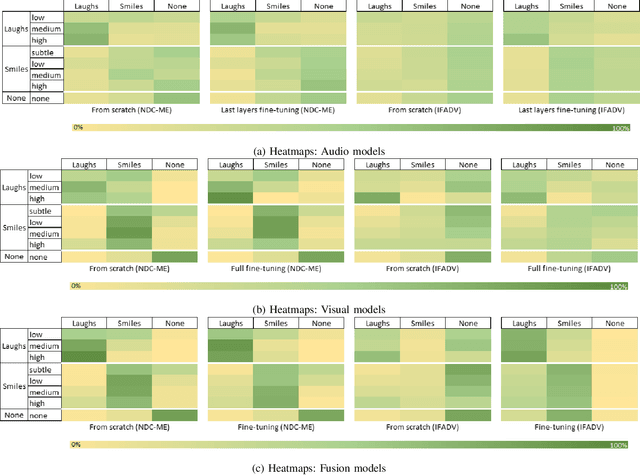
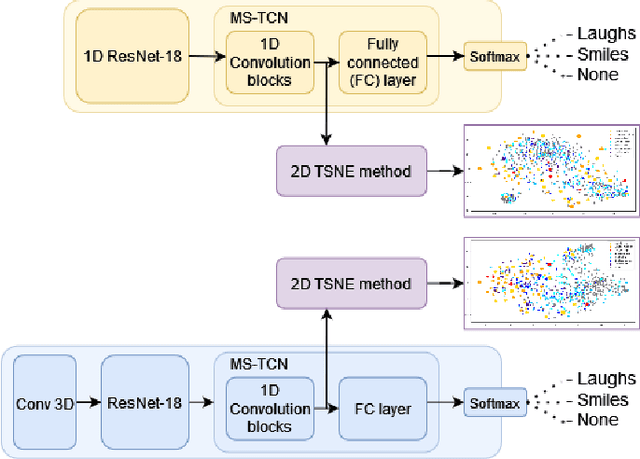
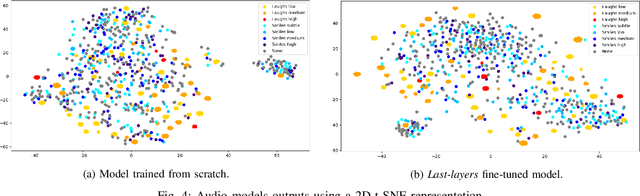
Smiles and laughs detection systems have attracted a lot of attention in the past decade contributing to the improvement of human-agent interaction systems. But very few considered these expressions as distinct, although no prior work clearly proves them to belong to the same category or not. In this work, we present a deep learning-based multimodal smile and laugh classification system, considering them as two different entities. We compare the use of audio and vision-based models as well as a fusion approach. We show that, as expected, the fusion leads to a better generalization on unseen data. We also present an in-depth analysis of the behavior of these models on the smiles and laughs intensity levels. The analyses on the intensity levels show that the relationship between smiles and laughs might not be as simple as a binary one or even grouping them in a single category, and so, a more complex approach should be taken when dealing with them. We also tackle the problem of limited resources by showing that transfer learning allows the models to improve the detection of confusing intensity levels.
A Recipe for Efficient SBIR Models: Combining Relative Triplet Loss with Batch Normalization and Knowledge Distillation
May 30, 2023Sketch-Based Image Retrieval (SBIR) is a crucial task in multimedia retrieval, where the goal is to retrieve a set of images that match a given sketch query. Researchers have already proposed several well-performing solutions for this task, but most focus on enhancing embedding through different approaches such as triplet loss, quadruplet loss, adding data augmentation, and using edge extraction. In this work, we tackle the problem from various angles. We start by examining the training data quality and show some of its limitations. Then, we introduce a Relative Triplet Loss (RTL), an adapted triplet loss to overcome those limitations through loss weighting based on anchors similarity. Through a series of experiments, we demonstrate that replacing a triplet loss with RTL outperforms previous state-of-the-art without the need for any data augmentation. In addition, we demonstrate why batch normalization is more suited for SBIR embeddings than l2-normalization and show that it improves significantly the performance of our models. We further investigate the capacity of models required for the photo and sketch domains and demonstrate that the photo encoder requires a higher capacity than the sketch encoder, which validates the hypothesis formulated in [34]. Then, we propose a straightforward approach to train small models, such as ShuffleNetv2 [22] efficiently with a marginal loss of accuracy through knowledge distillation. The same approach used with larger models enabled us to outperform previous state-of-the-art results and achieve a recall of 62.38% at k = 1 on The Sketchy Database [30].
Deep learning-based stereo camera multi-video synchronization
Mar 22, 2023Stereo vision is essential for many applications. Currently, the synchronization of the streams coming from two cameras is done using mostly hardware. A software-based synchronization method would reduce the cost, weight and size of the entire system and allow for more flexibility when building such systems. With this goal in mind, we present here a comparison of different deep learning-based systems and prove that some are efficient and generalizable enough for such a task. This study paves the way to a production ready software-based video synchronization system.
Synthesizer Preset Interpolation using Transformer Auto-Encoders
Oct 27, 2022Sound synthesizers are widespread in modern music production but they increasingly require expert skills to be mastered. This work focuses on interpolation between presets, i.e., sets of values of all sound synthesis parameters, to enable the intuitive creation of new sounds from existing ones. We introduce a bimodal auto-encoder neural network, which simultaneously processes presets using multi-head attention blocks, and audio using convolutions. This model has been tested on a popular frequency modulation synthesizer with more than one hundred parameters. Experiments have compared the model to related architectures and methods, and have demonstrated that it performs smoother interpolations. After training, the proposed model can be integrated into commercial synthesizers for live interpolation or sound design tasks.
Cardiotocography Signal Abnormality Detection based on Deep Unsupervised Models
Sep 29, 2022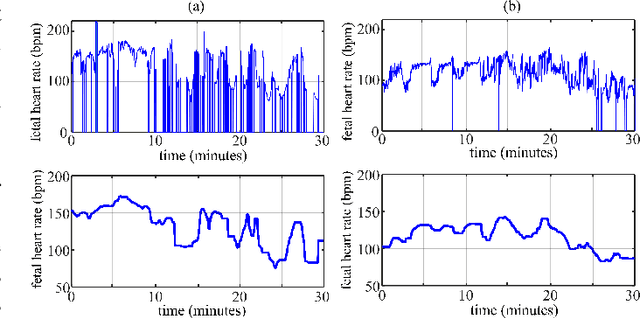
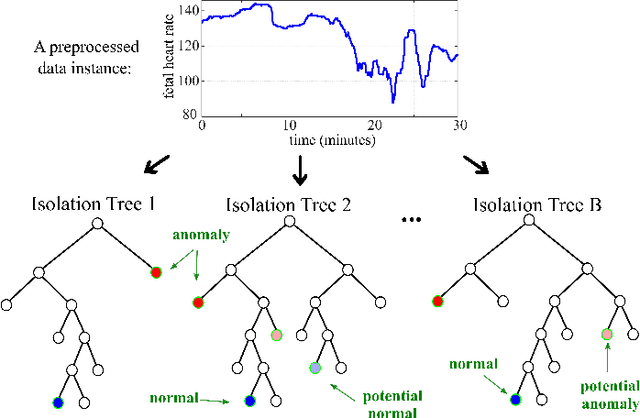
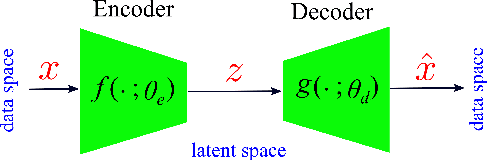
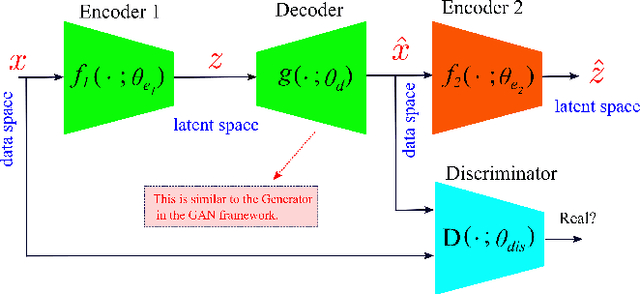
Cardiotocography (CTG) is a key element when it comes to monitoring fetal well-being. Obstetricians use it to observe the fetal heart rate (FHR) and the uterine contraction (UC). The goal is to determine how the fetus reacts to the contraction and whether it is receiving adequate oxygen. If a problem occurs, the physician can then respond with an intervention. Unfortunately, the interpretation of CTGs is highly subjective and there is a low inter- and intra-observer agreement rate among practitioners. This can lead to unnecessary medical intervention that represents a risk for both the mother and the fetus. Recently, computer-assisted diagnosis techniques, especially based on artificial intelligence models (mostly supervised), have been proposed in the literature. But, many of these models lack generalization to unseen/test data samples due to overfitting. Moreover, the unsupervised models were applied to a very small portion of the CTG samples where the normal and abnormal classes are highly separable. In this work, deep unsupervised learning approaches, trained in a semi-supervised manner, are proposed for anomaly detection in CTG signals. The GANomaly framework, modified to capture the underlying distribution of data samples, is used as our main model and is applied to the CTU-UHB dataset. Unlike the recent studies, all the CTG data samples, without any specific preferences, are used in our work. The experimental results show that our modified GANomaly model outperforms state-of-the-arts. This study admit the superiority of the deep unsupervised models over the supervised ones in CTG abnormality detection.
Transformers and CNNs both Beat Humans on SBIR
Sep 14, 2022
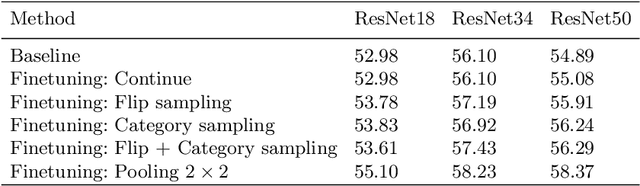


Sketch-based image retrieval (SBIR) is the task of retrieving natural images (photos) that match the semantics and the spatial configuration of hand-drawn sketch queries. The universality of sketches extends the scope of possible applications and increases the demand for efficient SBIR solutions. In this paper, we study classic triplet-based SBIR solutions and show that a persistent invariance to horizontal flip (even after model finetuning) is harming performance. To overcome this limitation, we propose several approaches and evaluate in depth each of them to check their effectiveness. Our main contributions are twofold: We propose and evaluate several intuitive modifications to build SBIR solutions with better flip equivariance. We show that vision transformers are more suited for the SBIR task, and that they outperform CNNs with a large margin. We carried out numerous experiments and introduce the first models to outperform human performance on a large-scale SBIR benchmark (Sketchy). Our best model achieves a recall of 62.25% (at k = 1) on the sketchy benchmark compared to previous state-of-the-art methods 46.2%.
Analysis of Co-Laughter Gesture Relationship on RGB videos in Dyadic Conversation Contex
May 20, 2022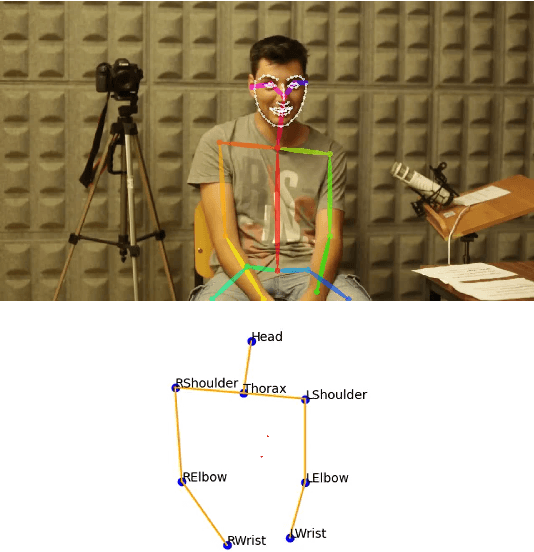

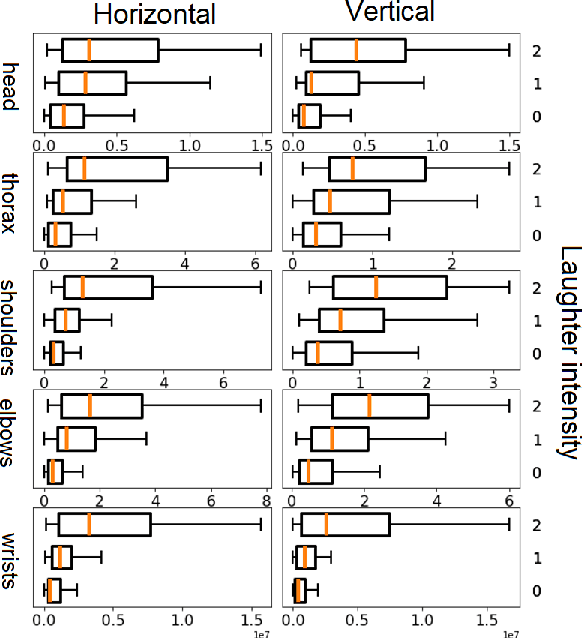
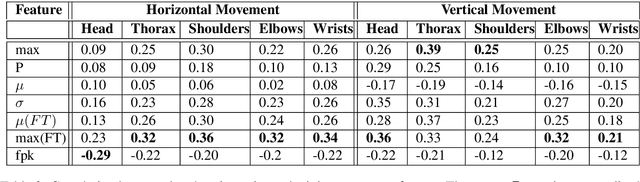
The development of virtual agents has enabled human-avatar interactions to become increasingly rich and varied. Moreover, an expressive virtual agent i.e. that mimics the natural expression of emotions, enhances social interaction between a user (human) and an agent (intelligent machine). The set of non-verbal behaviors of a virtual character is, therefore, an important component in the context of human-machine interaction. Laughter is not just an audio signal, but an intrinsic relationship of multimodal non-verbal communication, in addition to audio, it includes facial expressions and body movements. Motion analysis often relies on a relevant motion capture dataset, but the main issue is that the acquisition of such a dataset is expensive and time-consuming. This work studies the relationship between laughter and body movements in dyadic conversations. The body movements were extracted from videos using deep learning based pose estimator model. We found that, in the explored NDC-ME dataset, a single statistical feature (i.e, the maximum value, or the maximum of Fourier transform) of a joint movement weakly correlates with laughter intensity by 30%. However, we did not find a direct correlation between audio features and body movements. We discuss about the challenges to use such dataset for the audio-driven co-laughter motion synthesis task.