 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongitudinal Risk Prediction in Mammography with Privileged History Distillation
Mar 16, 2026Breast cancer remains a leading cause of cancer-related mortality worldwide. Longitudinal mammography risk prediction models improve multi-year breast cancer risk prediction based on prior screening exams. However, in real-world clinical practice, longitudinal histories are often incomplete, irregular, or unavailable due to missed screenings, first-time examinations, heterogeneous acquisition schedules, or archival constraints. The absence of prior exams degrades the performance of longitudinal risk models and limits their practical applicability. While substantial longitudinal history is available during training, prior exams are commonly absent at test time. In this paper, we address missing history at inference time and propose a longitudinal risk prediction method that uses mammography history as privileged information during training and distills its prognostic value into a student model that only requires the current exam at inference time. The key idea is a privileged multi-teacher distillation scheme with horizon-specific teachers: each teacher is trained on the full longitudinal history to specialize in one prediction horizon, while the student receives only a reconstructed history derived from the current exam. This allows the student to inherit horizon-dependent longitudinal risk cues without requiring prior screening exams at deployment. Our new Privileged History Distillation (PHD) method is validated on a large longitudinal mammography dataset with multi-year cancer outcomes, CSAW-CC, comparing full-history and no-history baselines to their distilled counterparts. Using time-dependent AUC across horizons, our privileged history distillation method markedly improves the performance of long-horizon prediction over no-history models and is comparable to that of full-history models, while using only the current exam at inference time.
Adaptation of Weakly Supervised Localization in Histopathology by Debiasing Predictions
Mar 12, 2026Weakly Supervised Object Localization (WSOL) models enable joint classification and region-of-interest localization in histology images using only image-class supervision. When deployed in a target domain, distributions shift remains a major cause of performance degradation, especially when applied on new organs or institutions with different staining protocols and scanner characteristics. Under stronger cross-domain shifts, WSOL predictions can become biased toward dominant classes, producing highly skewed pseudo-label distributions in the target domain. Source-Free (Unsupervised) Domain Adaptation (SFDA) methods are commonly employed to address domain shift. However, because they rely on self-training, the initial bias is reinforced over training iterations, degrading both classification and localization tasks. We identify this amplification of prediction bias as a primary obstacle to the SFDA of WSOL models in histopathology. This paper introduces \sfdadep, a method inspired by machine unlearning that formulates SFDA as an iterative process of identifying and correcting prediction bias. It periodically identifies target images from over-predicted classes and selectively reduces the predictive confidence for uncertain (high entropy) images, while preserving confident predictions. This process reduces the drift of decision boundaries and bias toward dominant classes. A jointly optimized pixel-level classifier further restores discriminative localization features under distribution shift. Extensive experiments on cross-organ and -center histopathology benchmarks (glas, CAMELYON-16, CAMELYON-17) with several WSOL models show that SFDA-DeP consistently improves classification and localization over state-of-the-art SFDA baselines. {\small Code: \href{https://anonymous.4open.science/r/SFDA-DeP-1797/}{anonymous.4open.science/r/SFDA-DeP-1797/}}
CLIP-IT: CLIP-based Pairing for Histology Images Classification
Apr 22, 2025Multimodal learning has shown significant promise for improving medical image analysis by integrating information from complementary data sources. This is widely employed for training vision-language models (VLMs) for cancer detection based on histology images and text reports. However, one of the main limitations in training these VLMs is the requirement for large paired datasets, raising concerns over privacy, and data collection, annotation, and maintenance costs. To address this challenge, we introduce CLIP-IT method to train a vision backbone model to classify histology images by pairing them with privileged textual information from an external source. At first, the modality pairing step relies on a CLIP-based model to match histology images with semantically relevant textual report data from external sources, creating an augmented multimodal dataset without the need for manually paired samples. Then, we propose a multimodal training procedure that distills the knowledge from the paired text modality to the unimodal image classifier for enhanced performance without the need for the textual data during inference. A parameter-efficient fine-tuning method is used to efficiently address the misalignment between the main (image) and paired (text) modalities. During inference, the improved unimodal histology classifier is used, with only minimal additional computational complexity. Our experiments on challenging PCAM, CRC, and BACH histology image datasets show that CLIP-IT can provide a cost-effective approach to leverage privileged textual information and outperform unimodal classifiers for histology.
PixelCAM: Pixel Class Activation Mapping for Histology Image Classification and ROI Localization
Mar 31, 2025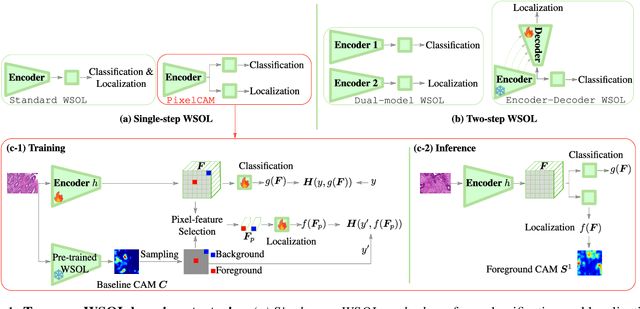



Weakly supervised object localization (WSOL) methods allow training models to classify images and localize ROIs. WSOL only requires low-cost image-class annotations yet provides a visually interpretable classifier, which is important in histology image analysis. Standard WSOL methods rely on class activation mapping (CAM) methods to produce spatial localization maps according to a single- or two-step strategy. While both strategies have made significant progress, they still face several limitations with histology images. Single-step methods can easily result in under- or over-activation due to the limited visual ROI saliency in histology images and the limited localization cues. They also face the well-known issue of asynchronous convergence between classification and localization tasks. The two-step approach is sub-optimal because it is tied to a frozen classifier, limiting the capacity for localization. Moreover, these methods also struggle when applied to out-of-distribution (OOD) datasets. In this paper, a multi-task approach for WSOL is introduced for simultaneous training of both tasks to address the asynchronous convergence problem. In particular, localization is performed in the pixel-feature space of an image encoder that is shared with classification. This allows learning discriminant features and accurate delineation of foreground/background regions to support ROI localization and image classification. We propose PixelCAM, a cost-effective foreground/background pixel-wise classifier in the pixel-feature space that allows for spatial object localization. PixelCAM is trained using pixel pseudo-labels collected from a pretrained WSOL model. Both image and pixel-wise classifiers are trained simultaneously using standard gradient descent. In addition, our pixel classifier can easily be integrated into CNN- and transformer-based architectures without any modifications.
MTLoc: A Confidence-Based Source-Free Domain Adaptation Approach For Indoor Localization
Mar 18, 2025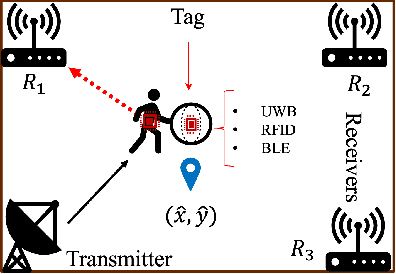
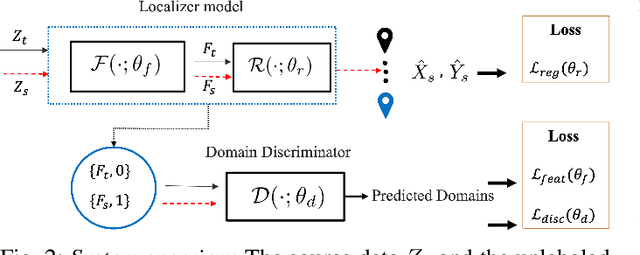
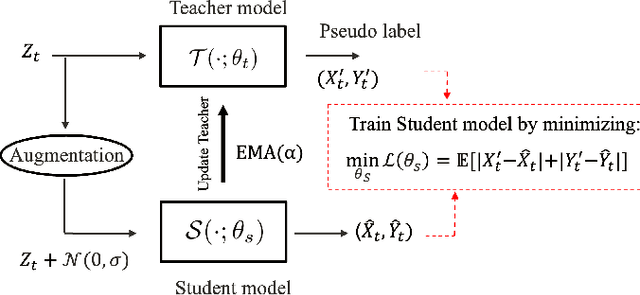
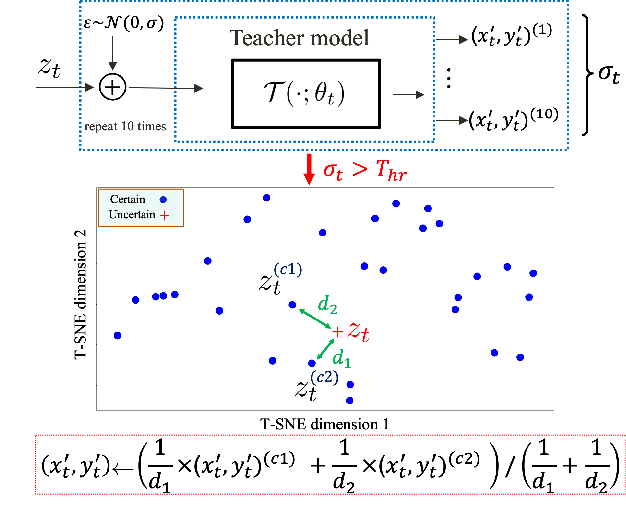
Various deep learning models have been developed for indoor localization based on radio-frequency identification (RFID) tags. However, they often require adaptation to ensure accurate tracking in new target operational domains. To address this challenge, unsupervised domain adaptation (UDA) methods have been proposed to align pre-trained models with data from target environments. However, they rely on large annotated datasets from the initial domain (source). Source data access is limited by privacy, storage, computational, and transfer constraints. Although many source-free domain adaptation (SFDA) methods address these constraints in classification, applying them to regression models for localization remains challenging. Indeed, target datasets for indoor localization are typically small, with few features and samples, and are noisy. Adapting regression models requires high-confidence target pseudo-annotation to avoid over-training. In this paper, a specialized mean-teacher method called MTLoc is proposed for SFDA. MTLoc updates the student network using noisy data and teacher-generated pseudo-labels. The teacher network maintains stability through exponential moving averages. To further ensure robustness, the teacher's pseudo-labels are refined using k-nearest neighbor correction. MTLoc allows for self-supervised learning on target data, facilitating effective adaptation to dynamic and noisy indoor environments. Validated using real-world data from our experimental setup with INLAN Inc., our results show that MTLoc achieves high localization accuracy under challenging conditions, significantly reducing localization error compared to baselines, including the state-of-the-art adversarial UDA approach with access to source data.
Islanding Detection for Active Distribution Networks Using WaveNet+UNet Classifier
Oct 17, 2024



This paper proposes an AI-based scheme for islanding detection in active distribution networks. By reviewing existing studies, it is clear that there are several gaps in the field to ensure reliable islanding detection, including (i) model complexity and stability concerns, (ii) limited accuracy under noisy conditions, and (iii) limited applicability to systems with different types of resources. Accordingly, this paper proposes a WaveNet classifier reinforced by a denoising U-Net model to address these shortcomings. The proposed scheme has a simple structure due to the use of 1D convolutional layers and incorporates residual connections that significantly enhance the model's generalization. Additionally, the proposed scheme is robust against noisy conditions by incorporating a denoising U-Net model. Furthermore, the model is sufficiently fast using a sliding window time series of 10 milliseconds for detection. Utilizing positive/negative/zero sequence components of voltages, superimposed waveforms, and the rate of change of frequency provides the necessary features to precisely detect the islanding condition. In order to assess the effectiveness of the suggested scheme, over 3k islanding/non-islanding cases were tested, considering different load active/reactive powers values, load switching transients, capacitor bank switching, fault conditions in the main grid, different load quality factors, signal-to-noise ratio levels, and both types of conventional and inverter-based sources.
Preserving Privacy in GANs Against Membership Inference Attack
Nov 06, 2023


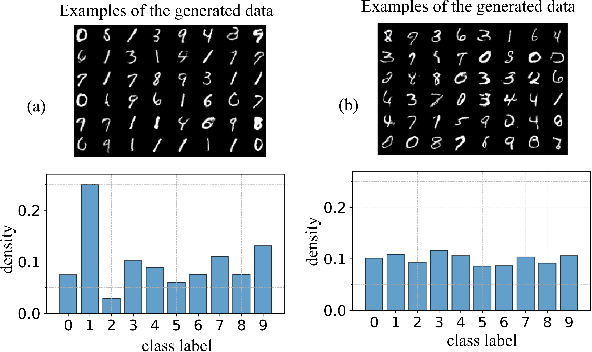
Generative Adversarial Networks (GANs) have been widely used for generating synthetic data for cases where there is a limited size real-world dataset or when data holders are unwilling to share their data samples. Recent works showed that GANs, due to overfitting and memorization, might leak information regarding their training data samples. This makes GANs vulnerable to Membership Inference Attacks (MIAs). Several defense strategies have been proposed in the literature to mitigate this privacy issue. Unfortunately, defense strategies based on differential privacy are proven to reduce extensively the quality of the synthetic data points. On the other hand, more recent frameworks such as PrivGAN and PAR-GAN are not suitable for small-size training datasets. In the present work, the overfitting in GANs is studied in terms of the discriminator, and a more general measure of overfitting based on the Bhattacharyya coefficient is defined. Then, inspired by Fano's inequality, our first defense mechanism against MIAs is proposed. This framework, which requires only a simple modification in the loss function of GANs, is referred to as the maximum entropy GAN or MEGAN and significantly improves the robustness of GANs to MIAs. As a second defense strategy, a more heuristic model based on minimizing the information leaked from generated samples about the training data points is presented. This approach is referred to as mutual information minimization GAN (MIMGAN) and uses a variational representation of the mutual information to minimize the information that a synthetic sample might leak about the whole training data set. Applying the proposed frameworks to some commonly used data sets against state-of-the-art MIAs reveals that the proposed methods can reduce the accuracy of the adversaries to the level of random guessing accuracy with a small reduction in the quality of the synthetic data samples.
$α$-Mutual Information: A Tunable Privacy Measure for Privacy Protection in Data Sharing
Oct 27, 2023This paper adopts Arimoto's $\alpha$-Mutual Information as a tunable privacy measure, in a privacy-preserving data release setting that aims to prevent disclosing private data to adversaries. By fine-tuning the privacy metric, we demonstrate that our approach yields superior models that effectively thwart attackers across various performance dimensions. We formulate a general distortion-based mechanism that manipulates the original data to offer privacy protection. The distortion metrics are determined according to the data structure of a specific experiment. We confront the problem expressed in the formulation by employing a general adversarial deep learning framework that consists of a releaser and an adversary, trained with opposite goals. This study conducts empirical experiments on images and time-series data to verify the functionality of $\alpha$-Mutual Information. We evaluate the privacy-utility trade-off of customized models and compare them to mutual information as the baseline measure. Finally, we analyze the consequence of an attacker's access to side information about private data and witness that adapting the privacy measure results in a more refined model than the state-of-the-art in terms of resiliency against side information.
Cardiotocography Signal Abnormality Detection based on Deep Unsupervised Models
Sep 29, 2022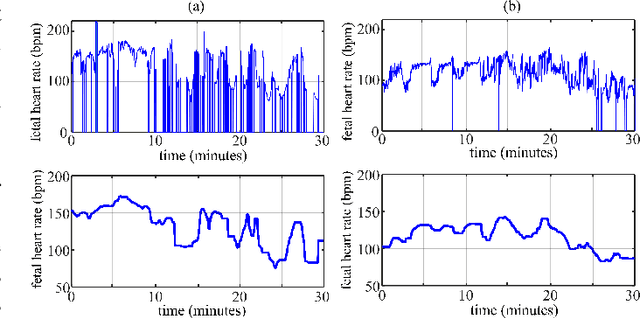
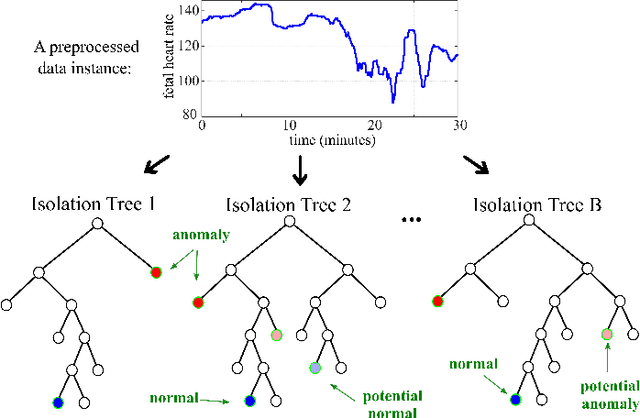
Cardiotocography (CTG) is a key element when it comes to monitoring fetal well-being. Obstetricians use it to observe the fetal heart rate (FHR) and the uterine contraction (UC). The goal is to determine how the fetus reacts to the contraction and whether it is receiving adequate oxygen. If a problem occurs, the physician can then respond with an intervention. Unfortunately, the interpretation of CTGs is highly subjective and there is a low inter- and intra-observer agreement rate among practitioners. This can lead to unnecessary medical intervention that represents a risk for both the mother and the fetus. Recently, computer-assisted diagnosis techniques, especially based on artificial intelligence models (mostly supervised), have been proposed in the literature. But, many of these models lack generalization to unseen/test data samples due to overfitting. Moreover, the unsupervised models were applied to a very small portion of the CTG samples where the normal and abnormal classes are highly separable. In this work, deep unsupervised learning approaches, trained in a semi-supervised manner, are proposed for anomaly detection in CTG signals. The GANomaly framework, modified to capture the underlying distribution of data samples, is used as our main model and is applied to the CTU-UHB dataset. Unlike the recent studies, all the CTG data samples, without any specific preferences, are used in our work. The experimental results show that our modified GANomaly model outperforms state-of-the-arts. This study admit the superiority of the deep unsupervised models over the supervised ones in CTG abnormality detection.
Learning Sparse Privacy-Preserving Representations for Smart Meters Data
Jul 17, 2021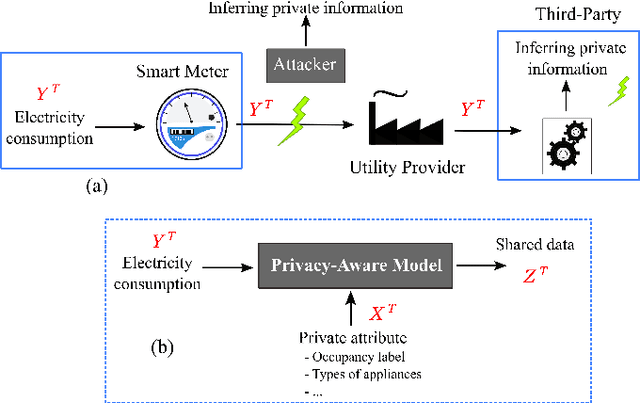
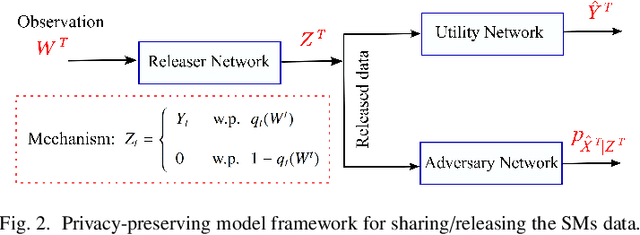
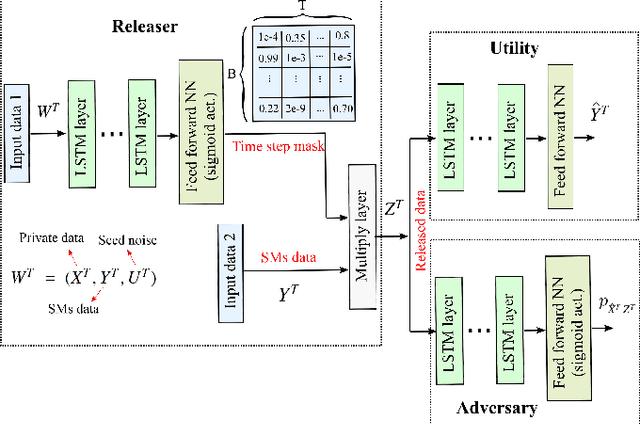
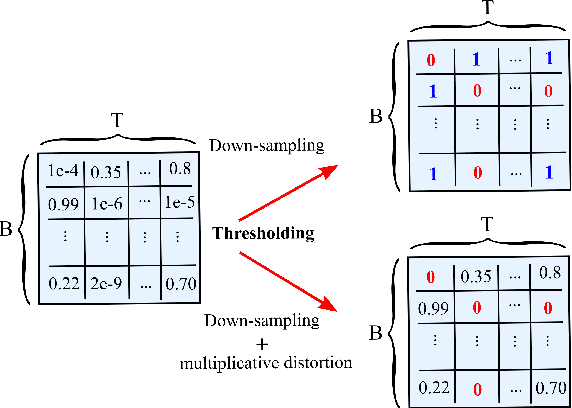
Fine-grained Smart Meters (SMs) data recording and communication has enabled several features of Smart Grids (SGs) such as power quality monitoring, load forecasting, fault detection, and so on. In addition, it has benefited the users by giving them more control over their electricity consumption. However, it is well-known that it also discloses sensitive information about the users, i.e., an attacker can infer users' private information by analyzing the SMs data. In this study, we propose a privacy-preserving approach based on non-uniform down-sampling of SMs data. We formulate this as the problem of learning a sparse representation of SMs data with minimum information leakage and maximum utility. The architecture is composed of a releaser, which is a recurrent neural network (RNN), that is trained to generate the sparse representation by masking the SMs data, and an utility and adversary networks (also RNNs), which help the releaser to minimize the leakage of information about the private attribute, while keeping the reconstruction error of the SMs data minimum (i.e., maximum utility). The performance of the proposed technique is assessed based on actual SMs data and compared with uniform down-sampling, random (non-uniform) down-sampling, as well as the state-of-the-art in privacy-preserving methods using a data manipulation approach. It is shown that our method performs better in terms of the privacy-utility trade-off while releasing much less data, thus also being more efficient.