 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Privacy in GANs Against Membership Inference Attack
Nov 06, 2023Generative Adversarial Networks (GANs) have been widely used for generating synthetic data for cases where there is a limited size real-world dataset or when data holders are unwilling to share their data samples. Recent works showed that GANs, due to overfitting and memorization, might leak information regarding their training data samples. This makes GANs vulnerable to Membership Inference Attacks (MIAs). Several defense strategies have been proposed in the literature to mitigate this privacy issue. Unfortunately, defense strategies based on differential privacy are proven to reduce extensively the quality of the synthetic data points. On the other hand, more recent frameworks such as PrivGAN and PAR-GAN are not suitable for small-size training datasets. In the present work, the overfitting in GANs is studied in terms of the discriminator, and a more general measure of overfitting based on the Bhattacharyya coefficient is defined. Then, inspired by Fano's inequality, our first defense mechanism against MIAs is proposed. This framework, which requires only a simple modification in the loss function of GANs, is referred to as the maximum entropy GAN or MEGAN and significantly improves the robustness of GANs to MIAs. As a second defense strategy, a more heuristic model based on minimizing the information leaked from generated samples about the training data points is presented. This approach is referred to as mutual information minimization GAN (MIMGAN) and uses a variational representation of the mutual information to minimize the information that a synthetic sample might leak about the whole training data set. Applying the proposed frameworks to some commonly used data sets against state-of-the-art MIAs reveals that the proposed methods can reduce the accuracy of the adversaries to the level of random guessing accuracy with a small reduction in the quality of the synthetic data samples.
$α$-Mutual Information: A Tunable Privacy Measure for Privacy Protection in Data Sharing
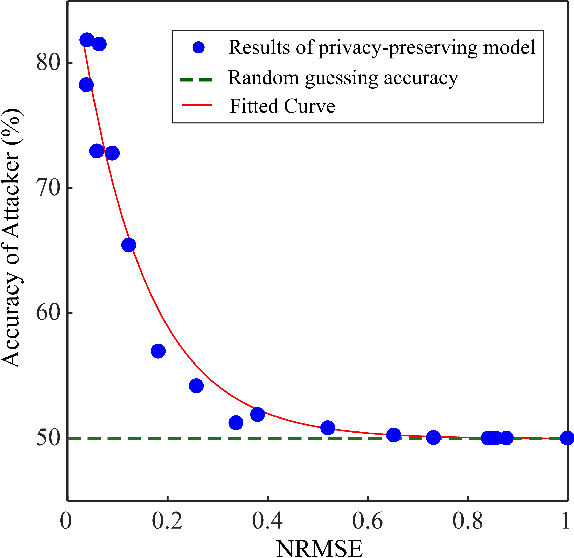
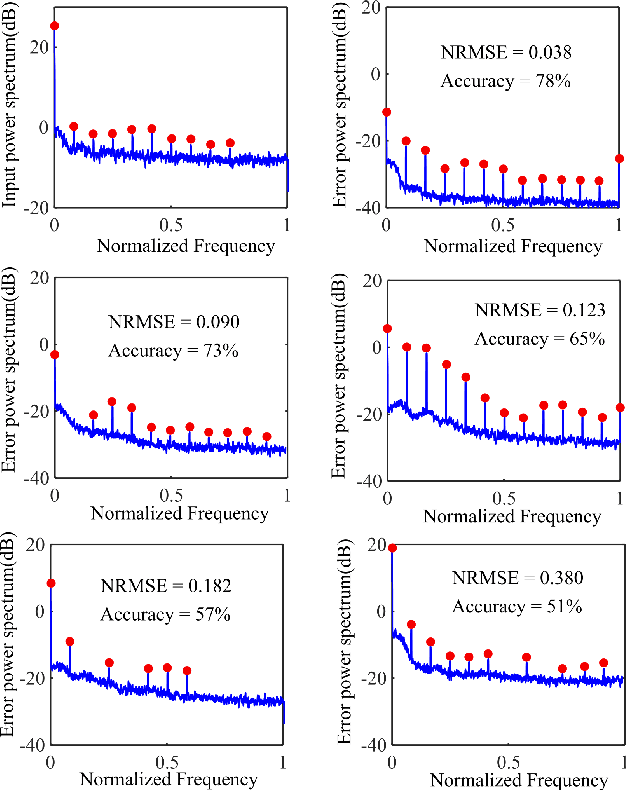
Oct 27, 2023This paper adopts Arimoto's $\alpha$-Mutual Information as a tunable privacy measure, in a privacy-preserving data release setting that aims to prevent disclosing private data to adversaries. By fine-tuning the privacy metric, we demonstrate that our approach yields superior models that effectively thwart attackers across various performance dimensions. We formulate a general distortion-based mechanism that manipulates the original data to offer privacy protection. The distortion metrics are determined according to the data structure of a specific experiment. We confront the problem expressed in the formulation by employing a general adversarial deep learning framework that consists of a releaser and an adversary, trained with opposite goals. This study conducts empirical experiments on images and time-series data to verify the functionality of $\alpha$-Mutual Information. We evaluate the privacy-utility trade-off of customized models and compare them to mutual information as the baseline measure. Finally, we analyze the consequence of an attacker's access to side information about private data and witness that adapting the privacy measure results in a more refined model than the state-of-the-art in terms of resiliency against side information.
Cardiotocography Signal Abnormality Detection based on Deep Unsupervised Models
Sep 29, 2022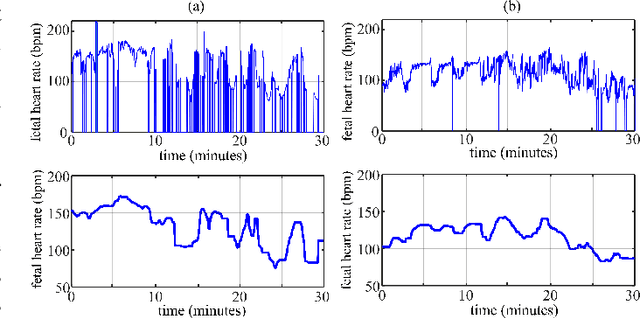
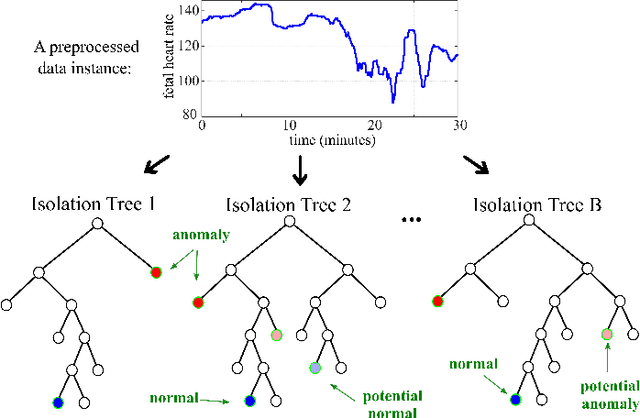
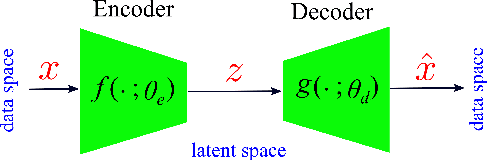
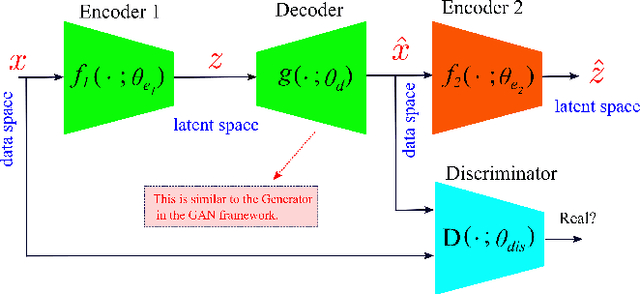
Cardiotocography (CTG) is a key element when it comes to monitoring fetal well-being. Obstetricians use it to observe the fetal heart rate (FHR) and the uterine contraction (UC). The goal is to determine how the fetus reacts to the contraction and whether it is receiving adequate oxygen. If a problem occurs, the physician can then respond with an intervention. Unfortunately, the interpretation of CTGs is highly subjective and there is a low inter- and intra-observer agreement rate among practitioners. This can lead to unnecessary medical intervention that represents a risk for both the mother and the fetus. Recently, computer-assisted diagnosis techniques, especially based on artificial intelligence models (mostly supervised), have been proposed in the literature. But, many of these models lack generalization to unseen/test data samples due to overfitting. Moreover, the unsupervised models were applied to a very small portion of the CTG samples where the normal and abnormal classes are highly separable. In this work, deep unsupervised learning approaches, trained in a semi-supervised manner, are proposed for anomaly detection in CTG signals. The GANomaly framework, modified to capture the underlying distribution of data samples, is used as our main model and is applied to the CTU-UHB dataset. Unlike the recent studies, all the CTG data samples, without any specific preferences, are used in our work. The experimental results show that our modified GANomaly model outperforms state-of-the-arts. This study admit the superiority of the deep unsupervised models over the supervised ones in CTG abnormality detection.
Learning Sparse Privacy-Preserving Representations for Smart Meters Data
Jul 17, 2021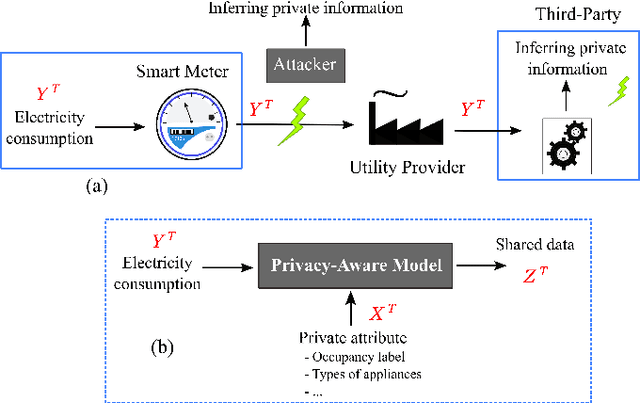
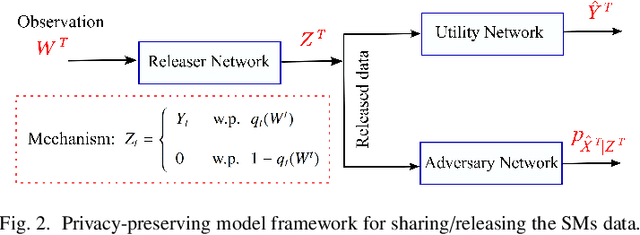
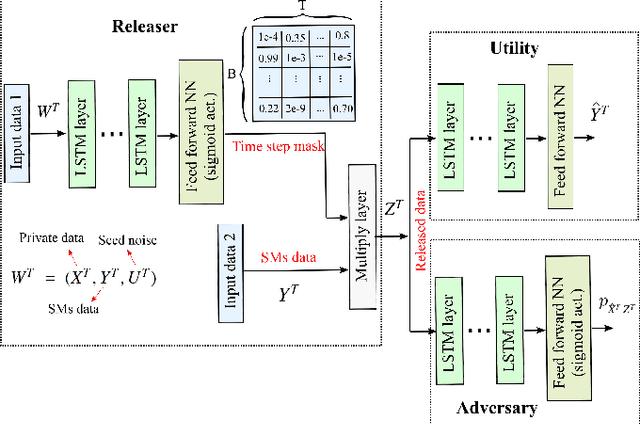
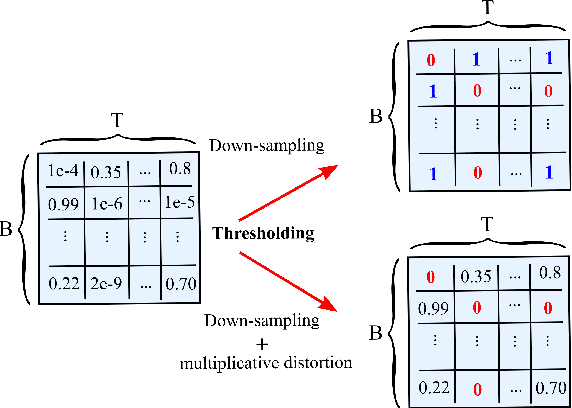
Fine-grained Smart Meters (SMs) data recording and communication has enabled several features of Smart Grids (SGs) such as power quality monitoring, load forecasting, fault detection, and so on. In addition, it has benefited the users by giving them more control over their electricity consumption. However, it is well-known that it also discloses sensitive information about the users, i.e., an attacker can infer users' private information by analyzing the SMs data. In this study, we propose a privacy-preserving approach based on non-uniform down-sampling of SMs data. We formulate this as the problem of learning a sparse representation of SMs data with minimum information leakage and maximum utility. The architecture is composed of a releaser, which is a recurrent neural network (RNN), that is trained to generate the sparse representation by masking the SMs data, and an utility and adversary networks (also RNNs), which help the releaser to minimize the leakage of information about the private attribute, while keeping the reconstruction error of the SMs data minimum (i.e., maximum utility). The performance of the proposed technique is assessed based on actual SMs data and compared with uniform down-sampling, random (non-uniform) down-sampling, as well as the state-of-the-art in privacy-preserving methods using a data manipulation approach. It is shown that our method performs better in terms of the privacy-utility trade-off while releasing much less data, thus also being more efficient.
Adversarial Robustness via Fisher-Rao Regularization
Jun 12, 2021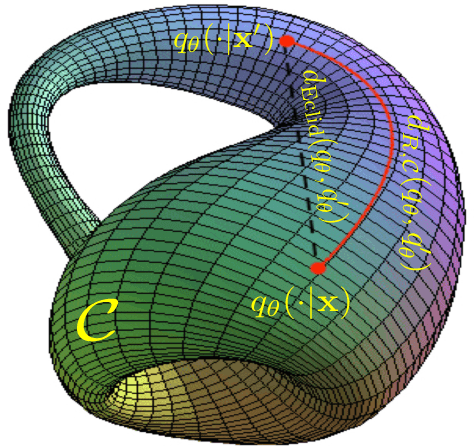
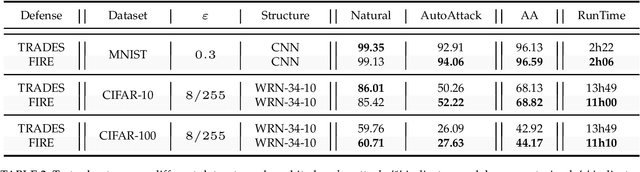
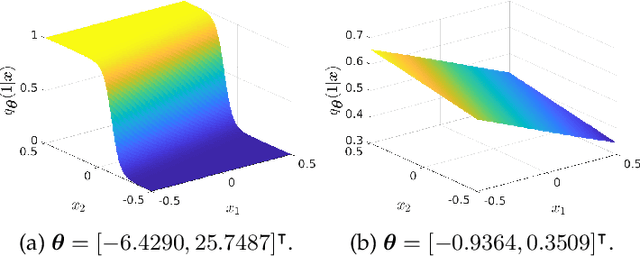
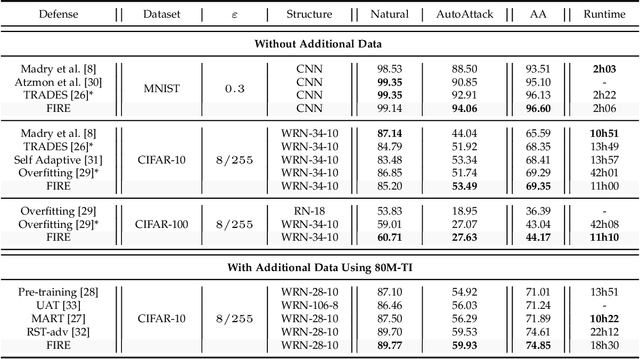
Adversarial robustness has become a topic of growing interest in machine learning since it was observed that neural networks tend to be brittle. We propose an information-geometric formulation of adversarial defense and introduce FIRE, a new Fisher-Rao regularization for the categorical cross-entropy loss, which is based on the geodesic distance between natural and perturbed input features. Based on the information-geometric properties of the class of softmax distributions, we derive an explicit characterization of the Fisher-Rao Distance (FRD) for the binary and multiclass cases, and draw some interesting properties as well as connections with standard regularization metrics. Furthermore, for a simple linear and Gaussian model, we show that all Pareto-optimal points in the accuracy-robustness region can be reached by FIRE while other state-of-the-art methods fail. Empirically, we evaluate the performance of various classifiers trained with the proposed loss on standard datasets, showing up to 2\% of improvements in terms of robustness while reducing the training time by 20\% over the best-performing methods.
Deep Directed Information-Based Learning for Privacy-Preserving Smart Meter Data Release
Nov 20, 2020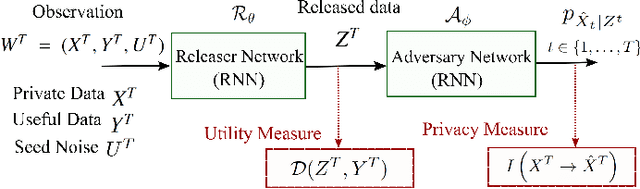
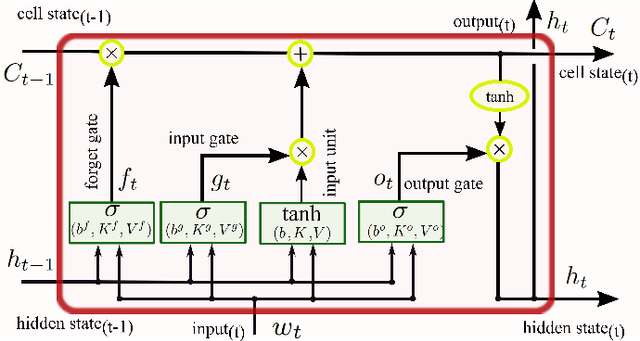
The explosion of data collection has raised serious privacy concerns in users due to the possibility that sharing data may also reveal sensitive information. The main goal of a privacy-preserving mechanism is to prevent a malicious third party from inferring sensitive information while keeping the shared data useful. In this paper, we study this problem in the context of time series data and smart meters (SMs) power consumption measurements in particular. Although Mutual Information (MI) between private and released variables has been used as a common information-theoretic privacy measure, it fails to capture the causal time dependencies present in the power consumption time series data. To overcome this limitation, we introduce the Directed Information (DI) as a more meaningful measure of privacy in the considered setting and propose a novel loss function. The optimization is then performed using an adversarial framework where two Recurrent Neural Networks (RNNs), referred to as the releaser and the adversary, are trained with opposite goals. Our empirical studies on real-world data sets from SMs measurements in the worst-case scenario where an attacker has access to all the training data set used by the releaser, validate the proposed method and show the existing trade-offs between privacy and utility.
Privacy-Preserving Adversarial Network (PPAN) for Continuous non-Gaussian Attributes
Mar 11, 2020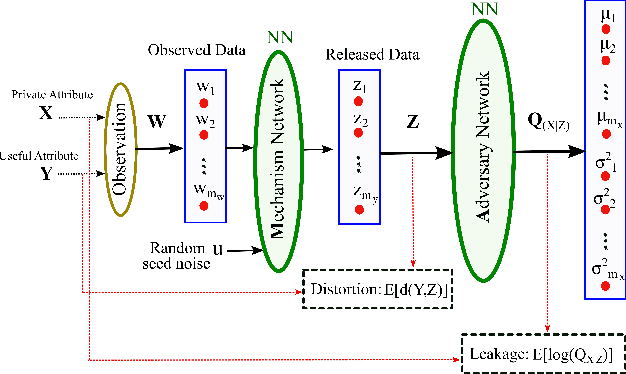
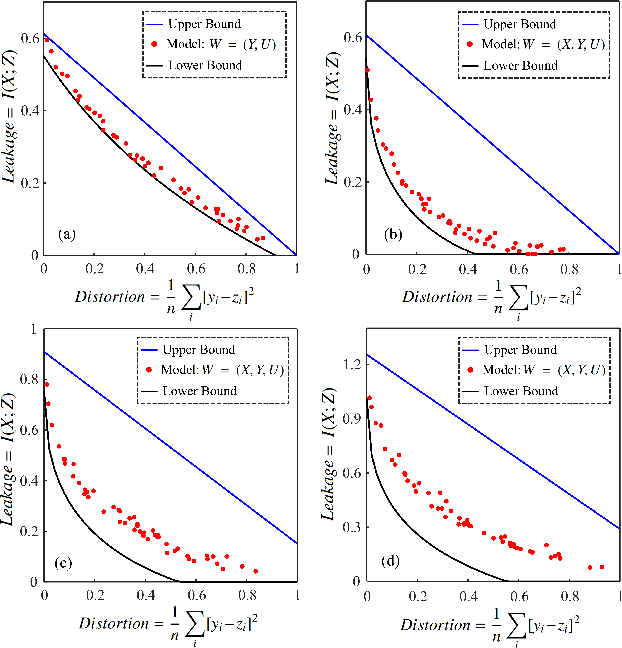
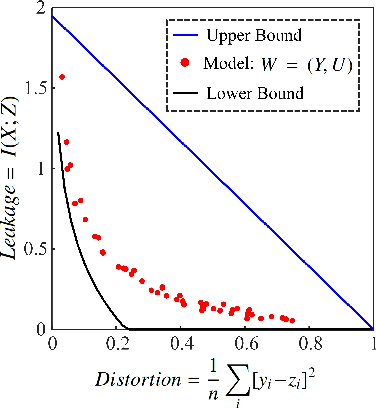
A privacy-preserving adversarial network (PPAN) was recently proposed as an information-theoretical framework to address the issue of privacy in data sharing. The main idea of this model was using mutual information as the privacy measure and adversarial training of two deep neural networks, one as the mechanism and another as the adversary. The performance of the PPAN model for the discrete synthetic data, MNIST handwritten digits, and continuous Gaussian data was evaluated compared to the analytically optimal trade-off. In this study, we evaluate the PPAN model for continuous non-Gaussian data where lower and upper bounds of the privacy-preserving problem are used. These bounds include the Kraskov (KSG) estimation of entropy and mutual information that is based on k-th nearest neighbor. In addition to the synthetic data sets, a practical case for hiding the actual electricity consumption from smart meter readings is examined. The results show that for continuous non-Gaussian data, the PPAN model performs within the determined optimal ranges and close to the lower bound.
Deep Recurrent Adversarial Learning for Privacy-Preserving Smart Meter Data Release
Jun 14, 2019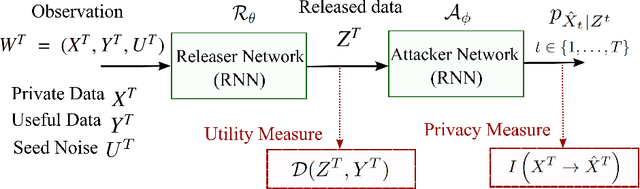
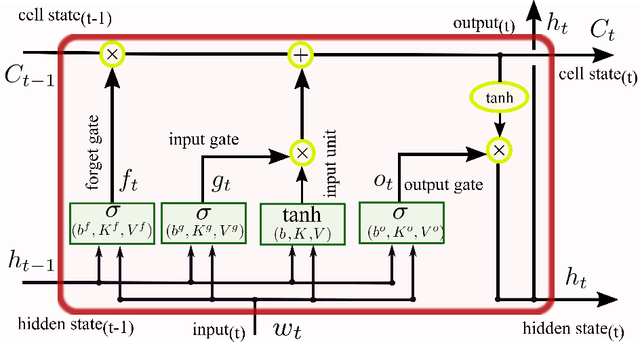
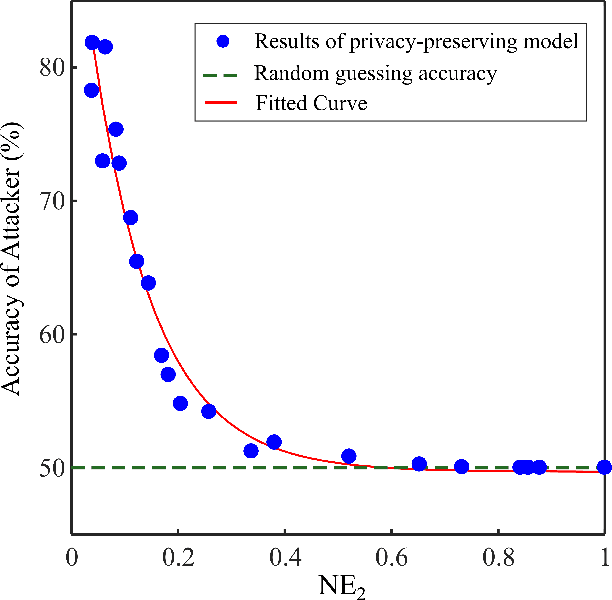
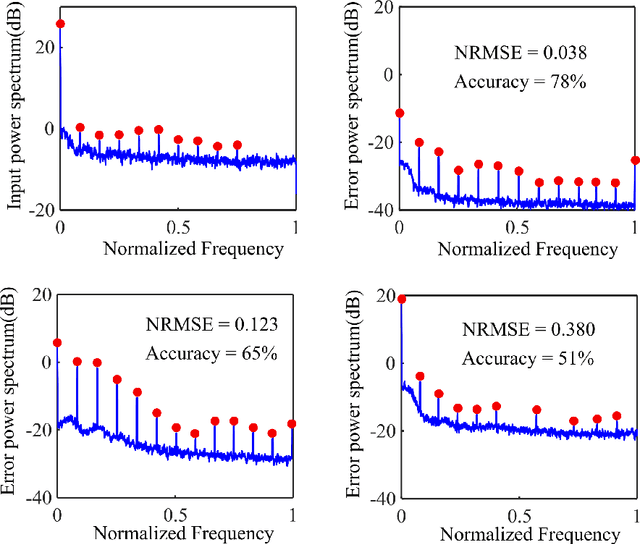
Smart Meters (SMs) are an important component of smart electrical grids, but they have also generated serious concerns about privacy data of consumers. In this paper, we present a general formulation of the privacy-preserving problem in SMs from an information-theoretic perspective. In order to capture the casual time series structure of the power measurements, we employ Directed Information (DI) as an adequate measure of privacy. On the other hand, to cope with a variety of potential applications of SMs data, we study different distortion measures along with the standard squared-error distortion. This formulation leads to a quite general training objective (or loss) which is optimized under a deep learning adversarial framework where two Recurrent Neural Networks (RNNs), referred to as the releaser and the attacker, are trained with opposite goals. An exhaustive empirical study is then performed to validate the proposed approach for different privacy problems in three actual data sets. Finally, we study the impact of the data mismatch problem, which occurs when the releaser and the attacker have different training data sets and show that privacy may not require a large level of distortion in real-world scenarios.
Distributed Lossy Source Coding Using Real-Number Codes
Jun 19, 2012

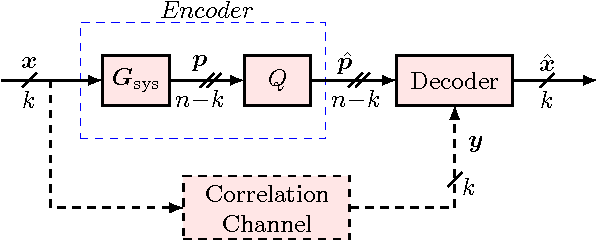

We show how real-number codes can be used to compress correlated sources, and establish a new framework for lossy distributed source coding, in which we quantize compressed sources instead of compressing quantized sources. This change in the order of binning and quantization blocks makes it possible to model correlation between continuous-valued sources more realistically and correct quantization error when the sources are completely correlated. The encoding and decoding procedures are described in detail, for discrete Fourier transform (DFT) codes. Reconstructed signal, in the mean squared error sense, is seen to be better than that in the conventional approach.